ZenFlow: محرك تسريع تدريب نماذج اللغات الضخمة بدون توقف
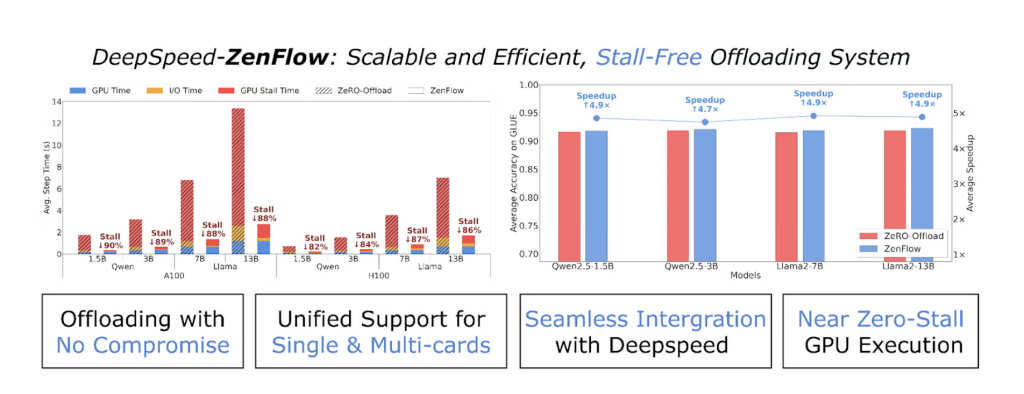
يُقدم فريق DeepSpeed ZenFlow، وهو محرك جديد لإدارة عمليات تحميل/تنزيل البيانات (Offloading) مصمم للتغلب على أحد أكبر المعوقات في تدريب نماذج اللغات الضخمة (LLM): توقف وحدة معالجة الرسوميات (GPU) بسبب وحدة المعالجة المركزية (CPU). بينما يُقلل تحميل المُحسّنات (Optimizers) والتدرجات (Gradients) إلى ذاكرة وحدة المعالجة المركزية من ضغط ذاكرة وحدة معالجة الرسوميات، غالباً ما تترك الأطر التقليدية مثل ZeRO-Offload و ZeRO-Infinity وحدات معالجة الرسوميات باهظة الثمن خاملة خلال معظم خطوات التدريب – في انتظار تحديثات وحدة المعالجة المركزية البطيئة ونقل البيانات عبر PCIe. فعلى سبيل المثال، قد يزيد وقت الخطوة الواحدة في ضبط Llama 2-7B بدقة على 4 وحدات معالجة رسوميات من طراز A100 مع تحميل البيانات الكامل من 0.5 ثانية إلى أكثر من 7 ثوانٍ، أي تباطؤ بمقدار 14 ضعفاً.
آلية عمل ZenFlow
يُزيل ZenFlow هذه التوقفات عن طريق فصل حسابات وحدة معالجة الرسوميات ووحدة المعالجة المركزية باستخدام خط أنابيب ذكي يعتمد على أهمية البيانات، مما يُوفر تسريعاً شاملاً يصل إلى 5 أضعاف مقارنةً بـ ZeRO-Offload ويُقلل من توقف وحدة معالجة الرسوميات بنسبة تزيد عن 85%.
تحديثات التدرج التي تعتمد على الأهمية:
يُعطي ZenFlow الأولوية لأهم k من التدرجات الأكثر تأثيراً لتحديثات وحدة معالجة الرسوميات الفورية، بينما يُؤجل التدرجات الأقل أهمية إلى تراكم غير متزامن على جانب وحدة المعالجة المركزية. يُقلل هذا من حركة مرور التدرج لكل خطوة بنسبة تقارب 50% وضغط عرض نطاق PCIe بمقدار الضعف تقريباً مقارنةً بـ ZeRO-Offload.
تراكم غير متزامن محدود على وحدة المعالجة المركزية:
يتم تجميع التدرجات غير الحرجة وتحديثها بشكل غير متزامن على وحدة المعالجة المركزية، مما يخفي عمل وحدة المعالجة المركزية خلف حسابات وحدة معالجة الرسوميات. يضمن هذا أن تكون وحدات معالجة الرسوميات مشغولة دائمًا، مما يتجنب التوقفات ويُعظم استخدام الأجهزة.
اختيار التدرج الخفيف:
يستبدل ZenFlow عملية AllGather الكاملة للتدرج بمُحاكاة خفيفة الوزن لمعيار التدرج لكل عمود، مما يُقلل من حجم الاتصال بأكثر من 4000 ضعف مع تأثير ضئيل على الدقة. يُمكّن هذا من التوسع بكفاءة عبر مجموعات متعددة من وحدات معالجة الرسوميات.
مميزات ZenFlow
- لا حاجة لتغيير التعليمات البرمجية: ZenFlow مدمج في DeepSpeed ولا يتطلب سوى تغييرات طفيفة في تكوين JSON.
- سهولة التكوين: يمكن للمستخدمين ضبط المعلمات مثل
topk_ratio(مثلًا، 0.05 لأعلى 5% من التدرجات) وتمكين الاستراتيجيات التكيفية مع ضبطselect_strategy,select_interval, وupdate_intervalعلى “auto”. - الأداء المُحسّن تلقائياً: يُكيّف المحرك فترات التحديث أثناء وقت التشغيل، مما يلغي الحاجة إلى الضبط اليدوي ويضمن أقصى قدر من الكفاءة مع تطور ديناميكيات التدريب.
نتائج الأداء
| الميزة | التأثير |
|---|---|
| التسريع الشامل | يصل إلى 5 أضعاف |
| تقليل توقف GPU | أكثر من 85% |
| استخدام GPU | أعلى |
| تقليل حركة مرور PCIe | حوالي الضعف |
| ضغط عرض النطاق للشبكة | أقل |
| دقة النموذج | بدون فقدان في دقة معايير GLUE |
| اختيار التدرج الخفيف | قابل للتطوير بكفاءة إلى مجموعات متعددة من GPUs |
| الضبط التلقائي | لا حاجة للضبط اليدوي للمعلمات |
الاستخدام العملي
ZenFlow هو امتداد مُباشر لـ DeepSpeed’s ZeRO-Offload. لا يلزم إجراء تغييرات في التعليمات البرمجية؛ فقط تحديثات التكوين في ملف DeepSpeed JSON مطلوبة. يحتوي مستودع DeepSpeedExamples على مثال ضبط دقيق باستخدام ZenFlow على معيار GLUE.
الخلاصة
يُمثل ZenFlow قفزة نوعية كبيرة لأي شخص يُدرب أو يُحسّن نماذج اللغات الضخمة على موارد محدودة لوحدة معالجة الرسوميات. من خلال القضاء الفعال على توقف وحدة معالجة الرسوميات الناجم عن وحدة المعالجة المركزية، فإنه يُتيح إنتاجية أعلى وتكلفة إجمالية أقل للتدريب، دون التضحية بدقة النموذج. يُعد هذا النهج ذا قيمة خاصة للمنظمات التي تُوسّع أحمال عمل نماذج اللغات الضخمة عبر أجهزة متنوعة أو تسعى إلى تعظيم استخدام وحدة معالجة الرسوميات في مجموعات السحاب أو داخل الموقع. بالنسبة للفرق التقنية، فإن الجمع بين الضبط التلقائي، والتهيئة الدنيا، والتكامل السلس مع DeepSpeed يجعل ZenFlow في متناول اليد وقويًا في آن واحد. تُقلل الأمثلة والوثائق المُقدمة من عوائق التبني، مما يُمكّن من التجريب والانتشار السريع.
مواضيع مشابهة:
 DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
 بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena
بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena



اترك تعليقاً