
1. مقدمة
شهد مجال الذكاء الاصطناعي تطورًا متسارعًا يمكن وصفه بالانفجار. فكما توقع تقرير Market Research Future، من المتوقع أن يصل سوق نماذج اللغة الكبيرة (LLM) في أمريكا الشمالية وحدها إلى 105.5 مليار دولار بحلول عام 2030. هذا النمو الهائل في أدوات الذكاء الاصطناعي، جنبًا إلى جنب مع الوصول إلى كميات هائلة من البيانات النصية، فتح الأبواب أمام توليد محتوى أفضل وأكثر تقدمًا مما كنا نأمله في أي وقت مضى. ومع ذلك، فإن هذا التوسع السريع يجعل من الصعب أكثر من أي وقت مضى التنقل بين نماذج LLM المتنوعة المتاحة واختيار الأدوات المناسبة.
يهدف هذا المقال إلى إبقائك، أيها المتحمس والمهني في مجال الذكاء الاصطناعي، على اطلاع دائم بالاتجاهات الحالية والابتكارات الأساسية في هذا المجال. فيما يلي، نسلط الضوء على أفضل 9 نماذج LLM التي نعتقد أنها تحدث حاليًا ضجة في الصناعة، ولكل منها قدرات متميزة ونقاط قوة متخصصة، وتتفوق في مجالات مثل معالجة اللغة الطبيعية، وتوليد التعليمات البرمجية، والتعلم القليل، أو قابلية التوسع. في حين أننا نعتقد أنه لا يوجد نموذج LLM واحد يناسب جميع حالات الاستخدام، فإننا نأمل أن تساعدك هذه القائمة في تحديد نموذج LLM الأكثر حداثة وملاءمة والذي يلبي المتطلبات الفريدة لعملك.
- 1.1 النمو المتسارع لنموذج اللغة الكبير (LLM): يتناول هذا القسم الزيادة الهائلة في عدد نماذج LLM المتاحة وقدراتها المتطورة، مدفوعة بتوفر البيانات الضخمة وقوة الحوسبة.
- 1.2 أهمية اختيار النموذج المناسب: يركز هذا الجزء على التحديات التي تواجه المستخدمين في اختيار النموذج الأمثل لتلبية احتياجاتهم الخاصة من بين المجموعة الواسعة من الخيارات المتاحة.
- 1.3 هدف المقال: تقديم أحدث التطورات وأهم الابتكارات في المجال: يحدد هذا القسم الهدف الرئيسي للمقال، وهو توفير رؤى شاملة ومحدثة حول أفضل نماذج LLM الرائدة في الصناعة.
بقية الفصول ستناقش بالتفصيل كل نموذج من النماذج التسعة المذكورة، مع التركيز على ميزاته الرئيسية وقدراته وأدائه وتطبيقاته المحتملة. سيتم تقديم كل نموذج بتقييم نقدي، مما يتيح للقراء اتخاذ قرارات مستنيرة بشأن استخدام نماذج LLM في سياقاتهم الخاصة.
2. GPT (Generative Pre-trained Transformer)
2.1 نظرة عامة على نماذج GPT من OpenAI
تتصدر نماذج GPT (Generative Pre-trained Transformer) من OpenAI قائمة نماذج اللغة الكبيرة، حيث تتجاوز باستمرار قدراتها السابقة مع كل إصدار جديد. تُعد هذه النماذج رائدة في مجال معالجة اللغة الطبيعية، حيث تقدم أداءً متميزًا في مجموعة واسعة من المهام، بدءًا من إنشاء النصوص الإبداعية وصولًا إلى حل المشكلات المعقدة. تعتمد GPT على بنية Transformer القوية، التي تسمح لها بالتعلم من كميات هائلة من البيانات النصية وفهم العلاقات المعقدة بين الكلمات والعبارات.
2.2 ChatGPT-4o و ChatGPT-4o Mini: تحسينات السرعة والقدرات
يمثل إطلاق ChatGPT-4o و ChatGPT-4o Mini أحدث التطورات في سلسلة GPT. بالمقارنة مع النماذج السابقة، توفر هذه النماذج الجديدة سرعات معالجة أسرع بكثير وقدرات محسنة عبر النصوص والصوت والرؤية. تتميز هذه التحسينات بأهمية خاصة في التطبيقات التي تتطلب استجابات في الوقت الفعلي، مثل روبوتات الدردشة التفاعلية وأنظمة المساعدة الافتراضية.
2.3 عدد المعلمات وحجم نافذة السياق
يُعتقد أن النماذج الأحدث تحتوي على أكثر من 175 مليار معلمة، متجاوزة عدد معلمات ChatGPT-3 (التي كانت تبلغ 175 مليارًا)، ونافذة سياق كبيرة تبلغ 128,000 رمزًا، مما يجعلها فعالة للغاية في معالجة وتوليد كميات كبيرة من البيانات. تسمح هذه النافذة السياقية الكبيرة للنموذج بفهم السياق الأوسع للنص ومعالجة العلاقات المعقدة بين الأجزاء المختلفة من النص.
2.4 القدرات المتعددة الوسائط (نص، صوت، صورة)
تم تجهيز كلا النموذجين بقدرات متعددة الوسائط للتعامل مع الصور والبيانات الصوتية. هذا يعني أن GPT يمكنه الآن فهم وإنشاء محتوى يعتمد على مزيج من النصوص والصور والأصوات، مما يفتح الباب أمام تطبيقات جديدة ومثيرة في مجالات مثل التعرف على الصور، والترجمة الصوتية، وإنشاء محتوى الوسائط المتعددة.
2.5 طبيعة النموذج الاحتكارية وقيود الوصول
على الرغم من قدراته المحادثة والاستدلال المتقدمة، تجدر الإشارة إلى أن GPT هو نموذج احتكاري، مما يعني أن بيانات التدريب والمعلمات تظل سرية بواسطة OpenAI، وأن الوصول إلى الوظائف الكاملة مقيد – غالبًا ما تكون هناك حاجة إلى ترخيص تجاري أو اشتراك لفتح النطاق الكامل من الميزات. هذا يعني أن الشركات التي ترغب في استخدام GPT يجب أن تكون على استعداد لدفع رسوم مقابل الوصول إلى النموذج وقد لا تتمكن من تخصيص النموذج لتلبية احتياجاتها الخاصة.
2.6 توصيات الاستخدام: الحوار التفاعلي، الاستدلال متعدد الخطوات، الحساب الفعال
في هذه الحالة، نوصي بهذا النموذج للشركات التي تتطلع إلى تبني نموذج لغوي كبير يتفوق في الحوار التفاعلي والاستدلال متعدد الخطوات والحساب الفعال والتفاعلات في الوقت الفعلي دون قيود الميزانية. يمكن استخدام GPT لإنشاء روبوتات دردشة ذكية يمكنها التعامل مع مجموعة واسعة من الأسئلة وتقديم إجابات دقيقة ومفيدة. بالإضافة إلى ذلك، يمكن استخدام GPT لحل المشكلات المعقدة التي تتطلب استدلالًا متعدد الخطوات، مثل التخطيط المالي وتحليل المخاطر.
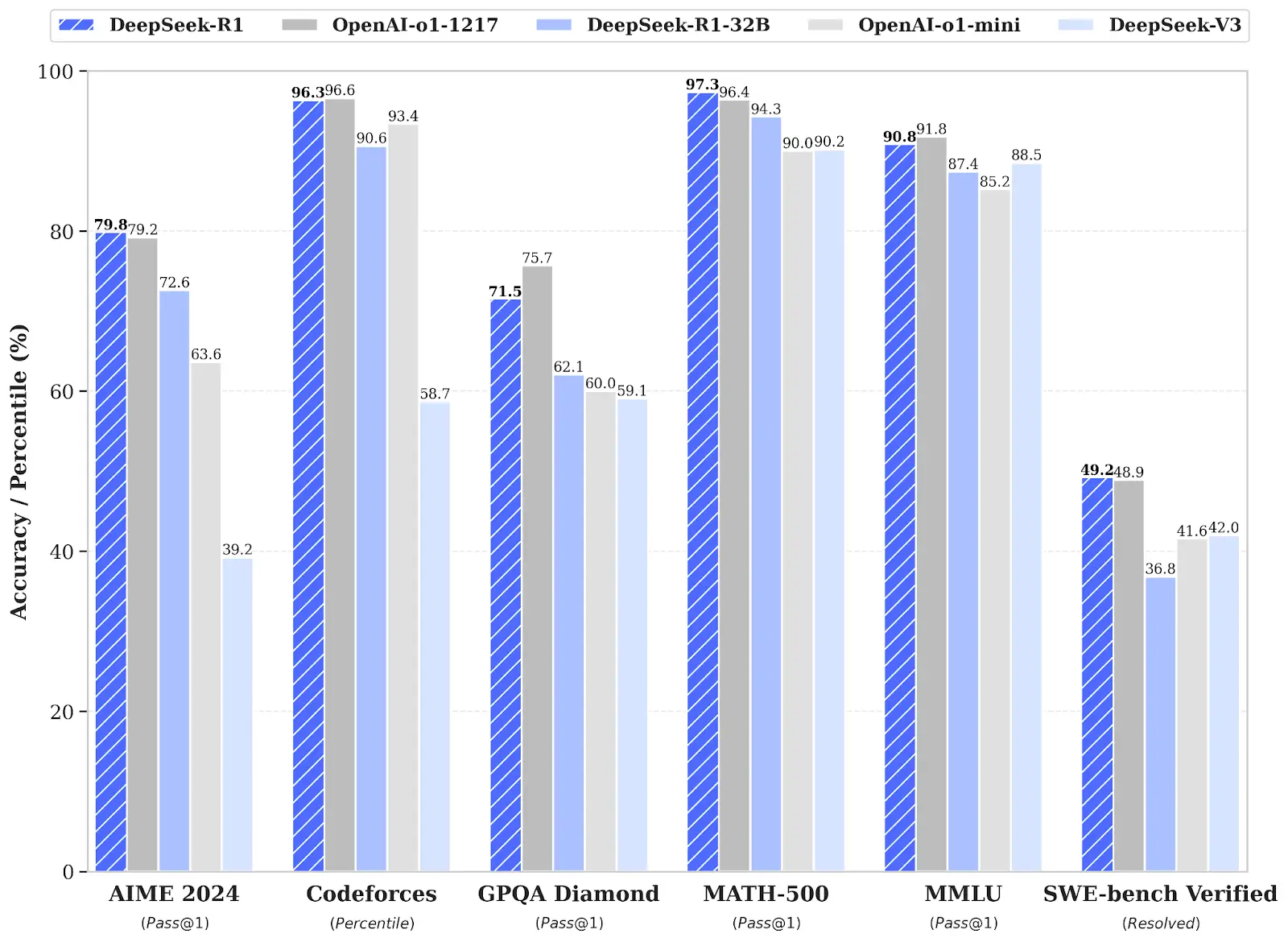
3. DeepSeek
مع أحدث نماذجها R1، وضعت شركة الذكاء الاصطناعي الصينية DeepSeek مرة أخرى معايير جديدة للابتكار في مجتمع الذكاء الاصطناعي. اعتبارًا من 24 يناير 2025، يحتل نموذج DeepSeek-R1 المرتبة الرابعة في ساحة Chatbot Arena، والأول كأفضل نموذج لغوي مفتوح المصدر.
إن DeepSeek-R1 هو نموذج Mixture-of-Experts (MoE) يضم 671 مليار معلمة مع 37 مليار معلمة نشطة لكل رمز، تم تدريبه من خلال التعلم المعزز واسع النطاق مع تركيز قوي على قدرات الاستدلال. يتفوق النموذج في فهم ومعالجة المحتوى الطويل ويظهر أداءً فائقًا في المهام المعقدة مثل الرياضيات وتوليد التعليمات البرمجية. النموذج أكثر فعالية من حيث التكلفة بحوالي 30 مرة وأسرع 5 مرات من OpenAI-o1، مما يوفر أداءً رائدًا بتكلفة زهيدة. علاوة على ذلك، فقد أظهر دقة استثنائية في المهام التي تتطلب التعرف المعقد على الأنماط، مثل تحليل البيانات الجينومية والتصوير الطبي والمحاكاة العلمية واسعة النطاق.
تعتبر قدرات DeepSeek-R1 تحويلية عندما يتعلق الأمر بالتكامل مع بيانات المؤسسات الخاصة مثل معلومات التعريف الشخصية (PII) والسجلات المالية. من خلال الاستفادة من توليد الاسترجاع المعزز (RAG)، يمكن للمؤسسات ربط النموذج بمصادر بياناتها الداخلية لتمكين تفاعلات مخصصة للغاية واعية بالسياق – كل ذلك مع الحفاظ على معايير صارمة للأمن والامتثال. مع Shakudo، يمكنك تبسيط نشر ودمج نماذج الذكاء الاصطناعي المتقدمة مثل DeepSeek عن طريق أتمتة عمليات الإعداد والنشر والإدارة. هذا يلغي حاجة الشركات إلى الاستثمار في وصيانة بنية حوسبة واسعة النطاق. من خلال التشغيل داخل البنية التحتية الحالية لديك، تضمن المنصة تكاملًا سلسًا وأمانًا محسنًا وأداءً مثاليًا دون الحاجة إلى موارد داخلية كبيرة أو خبرة متخصصة.
يعتمد نموذج DeepSeek-R1 على معمارية Mixture-of-Experts (MoE)، وهي تقنية متطورة تسمح للنموذج بالتعامل مع كميات هائلة من البيانات بكفاءة عالية. في هذه المعمارية، يتم تقسيم النموذج إلى عدة “خبراء” متخصصين في معالجة أنواع معينة من المعلومات أو المهام. عندما يتم إدخال البيانات إلى النموذج، يتم توجيهها فقط إلى الخبراء الأكثر ملاءمة لمعالجة تلك البيانات، مما يوفر الوقت والموارد الحاسوبية. يساهم هذا التصميم في تحقيق النموذج لأداء فائق السرعة وفعالية من حيث التكلفة مقارنة بالنماذج الأخرى ذات الحجم المماثل.
تعتبر قدرة النموذج على فهم ومعالجة المحتوى الطويل ميزة رئيسية، حيث يمكنه الاحتفاظ بالسياق الضروري لفهم النصوص المعقدة والرد عليها بشكل متماسك. هذا يجعله مثاليًا لتطبيقات مثل تحليل المستندات القانونية أو التقارير الفنية أو الأبحاث العلمية، حيث يكون فهم التفاصيل الدقيقة والعلاقات المعقدة بين الأفكار أمرًا بالغ الأهمية.
كما أن أداء النموذج المتميز في المهام المعقدة مثل الرياضيات وتوليد التعليمات البرمجية يجعله أداة قيمة للمطورين والباحثين والمهندسين. يمكن استخدامه لتوليد التعليمات البرمجية تلقائيًا، أو للمساعدة في حل المشكلات الرياضية المعقدة، أو لإجراء محاكاة علمية واسعة النطاق.
إن قدرة DeepSeek-R1 على التكامل مع بيانات المؤسسات الخاصة باستخدام تقنية RAG تفتح آفاقًا جديدة لتطبيقات الذكاء الاصطناعي في الشركات والمؤسسات. من خلال ربط النموذج بمصادر البيانات الداخلية، يمكن للمؤسسات إنشاء أنظمة ذكاء اصطناعي مخصصة للغاية قادرة على فهم سياق بياناتها الخاصة والرد عليها بشكل ذكي. على سبيل المثال، يمكن استخدام النموذج للإجابة على أسئلة العملاء حول منتجات أو خدمات الشركة، أو لتقديم توصيات مخصصة بناءً على سجل مشترياتهم، أو للمساعدة في تحليل البيانات المالية أو القانونية.
باختصار، يعتبر DeepSeek-R1 نموذجًا لغويًا قويًا ومتعدد الاستخدامات يوفر أداءً رائدًا بتكلفة معقولة. إن قدراته المتقدمة في الاستدلال ومعالجة المحتوى الطويل والتكامل مع بيانات المؤسسات الخاصة تجعله أداة قيمة للشركات والمؤسسات التي تسعى إلى الاستفادة من الذكاء الاصطناعي لتحسين عملياتها واتخاذ قرارات أفضل.
4. Qwen (Alibaba)
4.1 نظرة عامة على نموذج QwQ-32B-Preview وتركيزه على قدرات الاستدلال
أحدث إصدار من Alibaba، نموذج QwQ، أحدث ضجة كبيرة في مجتمع الذكاء الاصطناعي. QwQ-32B-Preview هو نموذج بحثي تجريبي تم تطويره بواسطة فريق Qwen، ويركز على تطوير قدرات الاستدلال في الذكاء الاصطناعي. يمثل هذا النموذج قفزة نوعية في قدرة الآلات على فهم واستنتاج المعلومات، وهو أمر بالغ الأهمية في التطبيقات التي تتطلب تحليلاً متعمقًا واتخاذ قرارات معقدة.
4.2 مقارنة الأداء مع نماذج أخرى في مجالات الترميز والتحليل
مع 32.5 مليار معلمة، يتفوق النموذج الأخير على بعض النماذج الحالية في هذه المجالات، مما يوفر القدرة على التعامل مع المهام المعقدة. على الرغم من كونه نموذجًا تجريبيًا (preview)، فقد أظهر Model قدرات كبيرة في مجالات مثل الترميز والمهام التحليلية، مثل العمليات الحسابية الرياضية والاستنتاجات المنطقية. يظهر هذا التفوق بوضوح في الأداء المتميز للنموذج في اختبارات الرياضيات والأداء في اختبار AIME (American Invitational Mathematics Examination)، متجاوزًا بذلك نماذج OpenAI o1-preview و GPT-4. هذا يشير إلى إمكانات قوية في التعامل مع المشكلات التي تتطلب تفكيرًا رياضيًا متقدمًا وقدرة على استخلاص استنتاجات دقيقة.
4.3 التفوق في العمليات الحسابية الرياضية والاستدلال المنطقي
يركز نموذج QwQ-32B-Preview بشكل خاص على تطوير قدرات الاستدلال المنطقي والمعالجة الرياضية. وقد أظهر أداءً فائقًا في حل المشكلات الرياضية المعقدة، متجاوزًا بذلك النماذج الأخرى المتاحة حاليًا. يعكس هذا الأداء المتميز قدرة النموذج على فهم العلاقات الرياضية المعقدة وتطبيقها بشكل صحيح لحل المشكلات. كما يمتلك النموذج قدرة استدلالية قوية، مما يمكنه من استخلاص استنتاجات منطقية من البيانات المتاحة واتخاذ قرارات مستنيرة.
4.4 توفر النموذج للاختبار على منصات مثل Hugging Face
النموذج متاح حاليًا للاختبار على منصات مثل Hugging Face، ولكن الوصول الكامل إليه محدود. يسمح هذا التوفر للمطورين والباحثين بتقييم قدرات النموذج وتحديد إمكانات استخدامه في تطبيقاتهم الخاصة. ومع ذلك، فإن الوصول المحدود قد يفرض بعض القيود على الاستخدام الكامل للنموذج.
4.5 قدرة النموذج على التحقق من الإجابات من خلال التخطيط والفحص الذاتي
يكمن أحد الجوانب الفريدة في نموذج QwQ في منهجه المبتكر في الاستدلال، مما يسمح له بالتحقق من إجاباته من خلال التخطيط والفحص الذاتي. تتيح هذه الميزة للنموذج تقييم مدى دقة وموثوقية استنتاجاته، مما يقلل من احتمالية الخطأ ويعزز جودة النتائج. من خلال التخطيط المسبق وتقييم خطوات الاستدلال، يمكن للنموذج تحسين دقته وموثوقيته بشكل عام.
4.6 توصيات الاستخدام: معالجة كميات كبيرة من البيانات مع رؤى منطقية معقدة
هذا النموذج هو خيار موصى به للشركات التي تتطلع إلى معالجة كميات كبيرة من البيانات مع استخلاص رؤى منطقية معقدة. إن قدرات الاستدلال المتقدمة للنموذج تجعله مناسبًا تمامًا للتطبيقات التي تتطلب تحليلًا متعمقًا واتخاذ قرارات مستنيرة. على سبيل المثال، يمكن استخدامه في مجالات مثل تحليل المخاطر المالية، واكتشاف الاحتيال، والتنبؤ بالاتجاهات السوقية.
4.7 نموذج Qwen 2.5 مفتوح المصدر: المميزات والتطبيقات
بالنسبة للشركات والمستخدمين الذين يبحثون عن بديل مفتوح المصدر، يتوفر نموذج Qwen 2.5 على منصات مثل Hugging Face و ModelScope. يضم هذا النموذج نماذج تتراوح بين 0.5 مليار و 72 مليار معلمة، ويتميز بنوافذ سياق تصل إلى 128,000 رمزًا، وهو ممتاز لتوليد التعليمات البرمجية وتصحيح الأخطاء والتنبؤ الآلي. يتيح هذا التوفر للمطورين والباحثين تخصيص النموذج وتعديله ليناسب احتياجاتهم الخاصة. إضافة إلى ذلك، تجعل قدرات النموذج في توليد التعليمات البرمجية وتصحيح الأخطاء منه أداة قيمة لمطوري البرامج والمهندسين.
5. LG AI (EXAONE)
5.1 نظرة عامة على نموذج EXAONE 3.0 ثنائي اللغة وأدائه المتميز
EXAONE 3.0 هو نموذج لغة كبير (LLM) تم تطويره بواسطة LG AI Research. تم إطلاق هذا النموذج ثنائي اللغة في ديسمبر 2024، وقد أظهر أداءً متميزًا عبر مجموعة واسعة من المعايير القياسية والتطبيقات الواقعية. يمثل EXAONE 3.0 تطوراً هاماً في قدرات الذكاء الاصطناعي اللغوية، حيث يسعى إلى توفير حلول لغوية متقدمة للشركات والمؤسسات في مختلف المجالات.
5.2 عدد المعلمات والقدرة على فهم وإنشاء نصوص شبيهة بالنصوص البشرية
يحتوي EXAONE 3.0 على 7.8 مليار معلمة، مما يمنحه القدرة على فهم وإنشاء نصوص شبيهة بالنصوص البشرية في لغات متعددة. لا يقتصر هذا الفهم على النصوص العامة، بل يمتد إلى مجالات معقدة مثل الترميز والرياضيات وبراءات الاختراع والكيمياء. هذا التنوع في القدرات يجعل EXAONE 3.0 أداة قوية للعديد من التطبيقات.
5.3 تحسينات في وقت معالجة الاستدلال واستخدام الذاكرة وتكاليف التشغيل
تم تحسين EXAONE 3.0 لتقليل وقت معالجة الاستدلال بنسبة 56%، وتقليل استخدام الذاكرة بنسبة 35%، وتقليل تكاليف التشغيل بنسبة 72%. هذه التحسينات تجعل EXAONE 3.0 نموذجًا فعالاً من حيث التكلفة مع الحفاظ على الأداء العالي. يعزز هذا الجانب بشكل خاص من جاذبية النموذج للمؤسسات التي تسعى إلى تحقيق الكفاءة التشغيلية مع الاستفادة من تقنيات الذكاء الاصطناعي المتقدمة.
5.4 توفر النسخة الموجهة بالتعليمات ذات 7.8 مليار معلمة مفتوحة المصدر لأغراض البحث غير التجارية
أصدرت LG AI Research نسخة من EXAONE 3.0 موجهة بالتعليمات وتحتوي على 7.8 مليار معلمة كمصدر مفتوح للأغراض البحثية غير التجارية. يتيح هذا للمجتمع الأكاديمي والباحثين استكشاف قدرات النموذج وتطويره، مما يسهم في تقدم مجال الذكاء الاصطناعي اللغوي. من خلال إتاحة النموذج للأبحاث غير التجارية، تهدف LG AI Research إلى تعزيز الابتكار وتوسيع نطاق تطبيقات EXAONE 3.0 في مختلف المجالات العلمية والبحثية.
5.5 توصيات الاستخدام: توليد تعليمات برمجية بلغة Python، ومساعدة المطورين في استكشاف الأخطاء وإصلاحها، وإنشاء واجهات برمجة التطبيقات
بفضل قدراته في مجال الترميز، يوصى باستخدام EXAONE 3.0 في المجالات التالية:
- توليد تعليمات برمجية بلغة Python: يمكن استخدام EXAONE 3.0 لإنشاء تعليمات برمجية بلغة Python تلقائيًا، مما يوفر الوقت والجهد على المطورين.
- مساعدة المطورين في استكشاف الأخطاء وإصلاحها: يمكن لـ EXAONE 3.0 تحليل التعليمات البرمجية واقتراح حلول للأخطاء والمشكلات الموجودة فيها.
- إنشاء واجهات برمجة التطبيقات (APIs) وغيرها من المكونات الخلفية: يمكن استخدام EXAONE 3.0 لتطوير واجهات برمجة التطبيقات والمكونات الخلفية الأخرى، مما يساعد الشركات على بناء تطبيقات قوية وفعالة.
في ضوء هذه القدرات، يبرز EXAONE 3.0 كأداة قوية للشركات البرمجية والشركات الناشئة في مجال التكنولوجيا، حيث يمكنها الاستفادة من النموذج لتحسين عمليات التطوير، وتسريع وتيرة الابتكار، وتحقيق كفاءة أكبر في العمليات التشغيلية. إن القدرة على توليد تعليمات برمجية بلغة Python، والمساهمة في استكشاف الأخطاء وإصلاحها، وإنشاء واجهات برمجة التطبيقات، تمثل قيمة مضافة حقيقية للمطورين والمهندسين في هذا المجال.
6. LlaMA (Meta)
- 1 نظرة عامة على نماذج LlaMA 3.2 وقدراتها المتعددة الوسائط:
تواصل Meta ريادتها في مجال نماذج اللغات الكبيرة (LLMs) من خلال نماذج LlaMA المتطورة. أطلقت الشركة أحدث إصداراتها، LlaMA 3.2، في سبتمبر 2024، والتي تتميز بقدرات متعددة الوسائط تمكنها من معالجة كل من النصوص والصور لإجراء تحليل متعمق وتوليد استجابات دقيقة ومفصلة. هذه القدرات تسمح للنماذج بفهم محتوى الصورة، بما في ذلك تفسير الرسوم البيانية والخرائط، وترجمة النصوص المضمنة في الصور.
- 2 القدرة على معالجة النصوص والصور لتحليل متعمق وتوليد الاستجابات:
تمثل القدرة على معالجة كل من النصوص والصور خطوة كبيرة إلى الأمام في تطوير نماذج اللغات الكبيرة. يمكن لـ LlaMA 3.2 فهم العلاقات المعقدة بين النصوص والصور، مما يتيح لها تقديم تحليلات أكثر شمولاً وتوليد استجابات أكثر دقة وذات صلة بالسياق. على سبيل المثال، يمكن للنموذج تحليل رسم بياني وتحديد الاتجاهات الرئيسية، أو ترجمة نص موجود في صورة لافتة أو ملصق.
- 3 تنوع النماذج مع 8 و 70 و 405 مليار معلمة:
تقدم LlaMA 3.2 مجموعة متنوعة من النماذج بأحجام مختلفة، تتراوح بين 8 مليارات و 405 مليارات معلمة. هذا التنوع يتيح للمستخدمين اختيار النموذج الأنسب لاحتياجاتهم الخاصة، مع مراعاة عوامل مثل حجم البيانات المتاحة وقوة الحوسبة المطلوبة. النماذج الأصغر حجمًا مثالية للتطبيقات التي تتطلب استجابات سريعة واستهلاكًا أقل للموارد، بينما النماذج الأكبر حجمًا مناسبة للمهام التي تتطلب فهمًا أعمق للغة وتوليد محتوى أكثر تعقيدًا.
- 4 حجم نافذة السياق وقدرتها على التعامل مع مدخلات البيانات الضخمة والمعقدة:
تتميز LlaMA 3.2 بنافذة سياق كبيرة تبلغ 128,000 رمز، مما يمكنها من التعامل مع مدخلات البيانات الضخمة والمعقدة. تسمح هذه النافذة الكبيرة للنموذج بفهم السياق الأوسع للمحادثة أو النص، مما يؤدي إلى استجابات أكثر دقة وذات صلة بالسياق. هذه الميزة مهمة بشكل خاص للتطبيقات التي تتطلب معالجة النصوص الطويلة أو المحادثات المعقدة.
- 5 طبيعة النموذج مفتوحة المصدر ومرونة النشر:
على عكس نماذج ChatGPT، فإن LlaMA 3.2 مفتوحة المصدر، مما يمنح المستخدمين المرونة في الوصول إليها ونشرها بحرية على السحابة الخاصة بهم، اعتمادًا على المتطلبات المحددة للبنية التحتية الخاصة بهم، وتفضيلات الأمان، أو احتياجات التخصيص. هذه المرونة تجعل LlaMA 3.2 خيارًا جذابًا للشركات التي ترغب في التحكم الكامل في كيفية استخدام نماذج اللغات الكبيرة.
- 6 توصيات الاستخدام: توليد المحتوى المتقدم وفهم اللغة في خدمة العملاء والتعليم والتسويق:
يوصى باستخدام LlaMA 3.2 للشركات التي تبحث عن توليد محتوى متقدم وفهم اللغة، مثل تلك الموجودة في مجالات خدمة العملاء والتعليم والتسويق. يمكن استخدام LlaMA 3.2 لإنشاء روبوتات محادثة متطورة يمكنها التعامل مع مجموعة واسعة من استفسارات العملاء، وتطوير مواد تعليمية مخصصة، وإنشاء حملات تسويقية مقنعة. طبيعة هذه النماذج مفتوحة المصدر تسمح أيضًا بتحكم أكبر في أداء النموذج وضبطه ودمجه في مهام سير العمل الحالية. على سبيل المثال:
- خدمة العملاء: يمكن لـ LlaMA 3.2 إنشاء روبوتات محادثة يمكنها فهم استفسارات العملاء المعقدة وتقديم حلول دقيقة وفي الوقت المناسب.
- التعليم: يمكن استخدام LlaMA 3.2 لتطوير مواد تعليمية مخصصة تتكيف مع احتياجات الطلاب الفردية.
- التسويق: يمكن لـ LlaMA 3.2 إنشاء حملات تسويقية مقنعة تستهدف شرائح محددة من العملاء.
7. ميسترال
يقدم أحدث نماذج ميسترال، Mistral Large 2، إمكانات متميزة، خاصة فيما يتعلق بالكفاءة الحسابية، ودعم الترميز، وميزات الأمان.
يحتوي النموذج على 123 مليار معلمة ونافذة سياق ضخمة تبلغ 128,000 رمزًا، مما يعني أنه قادر على الحفاظ على الترابط عبر مقاطع نصية طويلة، مما يجعله مثاليًا للتطبيقات المعقدة التي تتطلب معالجة كميات كبيرة من المستندات. يسمح هذا الحجم الكبير لنافذة السياق للنموذج بفهم السياقات المعقدة واستخلاص استنتاجات دقيقة، حتى في المشاريع التي تتطلب تحليلًا متعمقًا للبيانات.
فيما يخص كفاءة الحوسبة، تم تصميم Mistral Large 2 لتقديم أداء ممتاز مع الحد الأدنى من استهلاك الموارد. هذا يجعله خيارًا جذابًا للشركات التي تبحث عن حلول الذكاء الاصطناعي القابلة للتطوير دون المساس بالأداء. بالإضافة إلى ذلك، يوفر النموذج دعمًا شاملاً للترميز، بما في ذلك إكمال التعليمات البرمجية وتصحيح الأخطاء وإنشاء الوثائق. هذا يجعلها أداة قيمة للمطورين والمهندسين الذين يتطلعون إلى تبسيط سير عملهم وأتمتة المهام المتكررة.
بالإضافة إلى ذلك، يتميز Mistral Large 2 بميزات أمان متقدمة لضمان أن تكون المخرجات الناتجة مسؤولة وأخلاقية. يتضمن ذلك آليات للكشف عن المحتوى الضار أو المتحيز والتخفيف منه، مما يضمن توافق النموذج مع أفضل الممارسات والمعايير التنظيمية. هذه الميزات مهمة بشكل خاص للشركات التي تتعامل مع معلومات حساسة أو تعمل في صناعات منظمة.
في حين أن Mistral Large 2 ليس مفتوح المصدر بالكامل، إلا أن الشركة تجعله متاحًا بسهولة على منصات مثل Hugging Face، بحيث يمكن للشركات الأخرى تنزيله لنشره في بيئاتها الخاصة. ومع ذلك، بالمقارنة مع النماذج مفتوحة المصدر، قد تجد صعوبة في ضبط هذا النموذج وتخصيصه لتطبيقات معينة. يمكن أن يشكل هذا تحديًا للشركات التي لديها متطلبات فريدة أو تحتاج إلى تعديل سلوك النموذج ليناسب حالات استخدام محددة. على الرغم من هذا القيد، فإن Mistral Large 2 يظل خيارًا قويًا للشركات التي تبحث عن نموذج لغة متطور يتميز بالكفاءة الحسابية ودعم الترميز وميزات الأمان.
8. Mistral
يمثل نموذج Mistral Large 2 أحدث إضافة إلى عائلة نماذج Mistral، ويأتي بقدرات متميزة تضعه في مصاف النماذج اللغوية الكبيرة الرائدة. يتميز هذا النموذج بكفاءة حوسبية عالية، ودعم قوي للترميز، وميزات أمان متطورة، مما يجعله خيارًا جذابًا لمجموعة واسعة من التطبيقات.
يحتوي Mistral Large 2 على 123 مليار معلمة، وهو عدد كبير يسمح له بفهم اللغة وتوليدها بدقة عالية. كما يمتلك نافذة سياق ضخمة تبلغ 128,000 رمز (token)، مما يعني قدرته على الحفاظ على الترابط والتماسك عبر مقاطع نصية طويلة جدًا. هذه القدرة ضرورية للتطبيقات المعقدة التي تتطلب معالجة كميات كبيرة من المستندات، مثل تلخيص التقارير الطويلة، والإجابة على الأسئلة المعقدة بناءً على مجموعة كبيرة من النصوص، وإنشاء محتوى إبداعي متماسك.
على الرغم من أن Mistral Large 2 ليس نموذجًا مفتوح المصدر تمامًا، إلا أن شركة Mistral تجعل الوصول إليه سهلاً على منصات مثل Hugging Face. يسمح هذا للشركات بتنزيل النموذج ونشره في بيئاتها الخاصة، مما يوفر لها درجة من التحكم في كيفية استخدامه. ومع ذلك، بالمقارنة مع النماذج مفتوحة المصدر، قد تجد الشركات صعوبة في إجراء تعديلات دقيقة وتخصيص النموذج لتطبيقات محددة. هذا القيد يتعلق بشكل أساسي بعدم إمكانية الوصول إلى بيانات التدريب الأصلية أو القدرة على تعديل بنية النموذج.
تعد كفاءة الحوسبة في Mistral Large 2 ميزة مهمة، خاصة بالنسبة للشركات التي تتطلع إلى تقليل تكاليف التشغيل. يسمح التصميم المحسّن للنموذج بتشغيله بكفاءة أكبر على الأجهزة المتاحة، مما يقلل من الحاجة إلى بنية تحتية حوسبية مكلفة. بالإضافة إلى ذلك، يوفر النموذج دعمًا قويًا للترميز، مما يجعله أداة قيمة للمطورين والمهندسين. يمكن استخدامه لإنشاء تعليمات برمجية تلقائيًا، واكتشاف الأخطاء وإصلاحها، وتحسين كفاءة عملية التطوير.
تولي Mistral أيضًا اهتمامًا كبيرًا لميزات الأمان في Mistral Large 2. يتضمن النموذج آليات للحد من توليد المحتوى الضار أو المتحيز، وضمان استخدامه بطريقة مسؤولة وأخلاقية. هذا مهم بشكل خاص للشركات التي تتعامل مع معلومات حساسة أو تسعى إلى بناء الثقة مع عملائها.
بشكل عام، يمثل Mistral Large 2 نموذجًا لغويًا كبيرًا قويًا ومتعدد الاستخدامات يقدم مجموعة من الميزات والقدرات. على الرغم من أنه ليس مفتوح المصدر تمامًا، إلا أن سهولة الوصول إليه وكفاءة الحوسبة وميزات الأمان القوية تجعله خيارًا جذابًا للعديد من الشركات والمؤسسات. ومع ذلك، يجب على الشركات أن تضع في اعتبارها قيود التخصيص والضبط الدقيق المحتملة مقارنة بالنماذج مفتوحة المصدر عند اتخاذ قرار بشأن استخدامه.
9. Gemini (Google)
تُمثل Gemini عائلة من نماذج اللغة الكبيرة (LLM) المغلقة المصدر التي طورتها شركة جوجل. صُممت النماذج الحالية – Gemini 1.0 Nano، و Gemini 1.5 Flash، و Gemini 1.5 Pro، و Gemini 1.0 Ultra – للعمل على أجهزة مختلفة، بدءًا من الهواتف الذكية وصولًا إلى الخوادم الضخمة. بوجود عدد هائل من المعلمات يصل إلى 1.5 تريليون، يُعد Gemini واحدًا من أكبر نماذج اللغة وأكثرها تقدمًا التي تم تطويرها حتى الآن.
تتميز عائلة نماذج Gemini بتنوعها وقدرتها على التكيف مع متطلبات المهام المختلفة. على سبيل المثال، تم تصميم Gemini 1.0 Nano ليتم تشغيله مباشرة على الأجهزة المحمولة، مما يتيح تجارب ذكاء اصطناعي مدمجة وسريعة الاستجابة. من ناحية أخرى، صُمم Gemini 1.5 Pro للتعامل مع مهام معالجة اللغة الأكثر تعقيدًا، مثل الترجمة الآلية وإنشاء المحتوى الإبداعي.
على الرغم من قدرات Gemini المذهلة، إلا أنه يظل نموذجًا احتكاريًا، مما يثير بعض المخاوف المتعلقة بالخصوصية والأمان. إذا كانت شركتك تتعامل بانتظام مع بيانات حساسة أو سرية، فقد تشعر بالقلق بشأن إرسالها إلى خوادم خارجية لأسباب أمنية. لتقليل هذه المخاطر، نوصي بشدة بالتحقق المزدوج من لوائح امتثال البائع للتأكد من تلبية معايير خصوصية وأمان البيانات، مثل الالتزام باللائحة العامة لحماية البيانات (GDPR) أو قانون HIPAA أو قوانين حماية البيانات الأخرى ذات الصلة. يتضمن ذلك فهم سياسات البائع المتعلقة بتخزين البيانات ومعالجتها والوصول إليها، بالإضافة إلى التدابير الأمنية التي يتم اتخاذها لحماية البيانات من الوصول غير المصرح به أو الاستخدام أو الكشف.
لتلبية الحاجة إلى نماذج لغة كبيرة مفتوحة المصدر، قدمت جوجل أيضًا نموذج Gemma 2، وهو بديل اقتصادي نسبيًا يوفر أداءً يقارب أداء Gemini. يتوفر Gemma 2 بثلاثة نماذج مختلفة تتراوح بين 2 مليار و 9 مليارات و 27 مليار معلمة، مع نافذة سياق تبلغ 8200. هذا النموذج هو الخيار الأمثل للشركات التي تبحث عن حل فعال من حيث التكلفة لترجمة وفهم الرسائل بدقة ملحوظة. يسمح كون Gemma 2 مفتوح المصدر للمؤسسات بفحص وتعديل النموذج ليناسب احتياجاتها الخاصة، مما يزيد من الشفافية والتحكم.
بالإضافة إلى ذلك، يوفر Gemma 2 مجموعة واسعة من أدوات وموارد المطورين، مما يسهل على المؤسسات دمج النموذج في تطبيقاتها الحالية. هذا يجعل Gemma 2 خيارًا جذابًا للمؤسسات التي تبحث عن نموذج لغة كبير قوي ومرن يمكن نشره بسهولة وفعالية من حيث التكلفة.
في الختام، تمثل عائلة نماذج Gemini من جوجل تطورًا هامًا في مجال نماذج اللغة الكبيرة، حيث تقدم أداءً وقدرات لا مثيل لها. ومع ذلك، يجب على المؤسسات أن تزن بعناية فوائد استخدام هذه النماذج المغلقة المصدر مقابل المخاطر المحتملة المتعلقة بالخصوصية والأمان. بالنسبة للمؤسسات التي تبحث عن بديل مفتوح المصدر، يوفر Gemma 2 خيارًا قويًا وفعالاً من حيث التكلفة.
10. Command (Cohere)
Command R هي عائلة من النماذج القابلة للتوسع طورتها شركة Cohere بهدف تحقيق توازن دقيق بين الأداء العالي والدقة القوية، على غرار نهج Claude. يركز هذا النهج على توفير نماذج لغوية كبيرة لا تتفوق فقط في المهام المعيارية ولكن أيضًا تحافظ على مستوى عالٍ من الدقة والموثوقية في مخرجاتها. هذا التوازن ضروري للتطبيقات العملية حيث تعتبر الاستجابات الصحيحة والمتسقة ذات أهمية قصوى.
تتميز كل من نموذجي Command R و Command R+ بتوفير واجهات برمجة تطبيقات (APIs) محسّنة خصيصًا لتقنية الاسترجاع المعزز بالتوليد (Retrieval Augmented Generation – RAG). RAG هي تقنية تجمع بين قوة نماذج اللغة الكبيرة وقدرة أنظمة استرجاع المعلومات. تسمح هذه التقنية للنماذج بالوصول إلى مصادر معلومات خارجية في الوقت الفعلي واستخدام هذه المعلومات لتوجيه عملية التوليد. هذا يعني أن النماذج يمكن أن تولد استجابات أكثر دقة وذات صلة بالسياق، خاصة في الحالات التي تتطلب معلومات حديثة أو متخصصة.
تقنية RAG تلعب دوراً حاسماً في تعزيز قدرات نماذج Command R. بدلاً من الاعتماد فقط على المعرفة المضمنة في بيانات التدريب الخاصة بها، يمكن لهذه النماذج الوصول إلى مجموعة واسعة من مصادر المعلومات الخارجية أثناء عملية التوليد. هذا يتيح لها تقديم استجابات أكثر دقة وشمولية، خاصة في المجالات التي تتطلب معرفة متخصصة أو معلومات حديثة. علاوة على ذلك، RAG يساعد في تقليل الاعتماد على المعلومات القديمة أو غير الدقيقة التي قد تكون موجودة في بيانات التدريب الأصلية.
في الوقت الحالي، يتباهى نموذج Command R+ بـ 104 مليار معلمة، مما يجعله نموذجًا كبيرًا وقادرًا على التعامل مع المهام اللغوية المعقدة. بالإضافة إلى ذلك، يوفر هذا النموذج نافذة سياق رائدة في الصناعة تبلغ 128,000 رمز (token)، مما يعزز بشكل كبير قدرات معالجة النماذج الطويلة وإمكانات المحادثة متعددة المنعطفات. تتيح نافذة السياق الواسعة للنموذج فهم العلاقات المعقدة بين الكلمات والجمل في النص، مما يؤدي إلى استجابات أكثر تماسكًا ودقة.
إن نافذة السياق الكبيرة في نموذج Command R+ تجعله مناسبًا بشكل خاص للتطبيقات التي تتطلب معالجة نصوص طويلة أو المشاركة في محادثات متعددة الأوجه. على سبيل المثال، يمكن استخدام هذا النموذج لتلخيص المستندات الطويلة، والإجابة على الأسئلة المعقدة المتعلقة بمجموعة كبيرة من النصوص، أو المشاركة في محادثات طبيعية تشبه الإنسان على مدى عدة تبادلات. هذه القدرات تجعل Command R+ أداة قيمة لمجموعة واسعة من التطبيقات، بما في ذلك خدمة العملاء والتعليم والبحث والتطوير.







اترك تعليقاً