نموذج فالكون-H1: تقرير تقني يكشف عن نموذج هجين متفوق يتنافس مع نماذج اللغات الضخمة 70B
يُمثّل نموذج فالكون-H1، الذي طوره معهد الابتكار التكنولوجي (TII)، إنجازًا بارزًا في تطور نماذج اللغات الضخمة (LLMs). بدمج آلية الانتباه القائمة على مُحوّل ترانسفورمر مع نماذج فضاء الحالة (SSMs) القائمة على مامبا في تكوين هجين متوازي، يحقق فالكون-H1 أداءً استثنائيًا وكفاءة عالية في الذاكرة وقابلية للتطوير.
تصميم معماري مبتكر
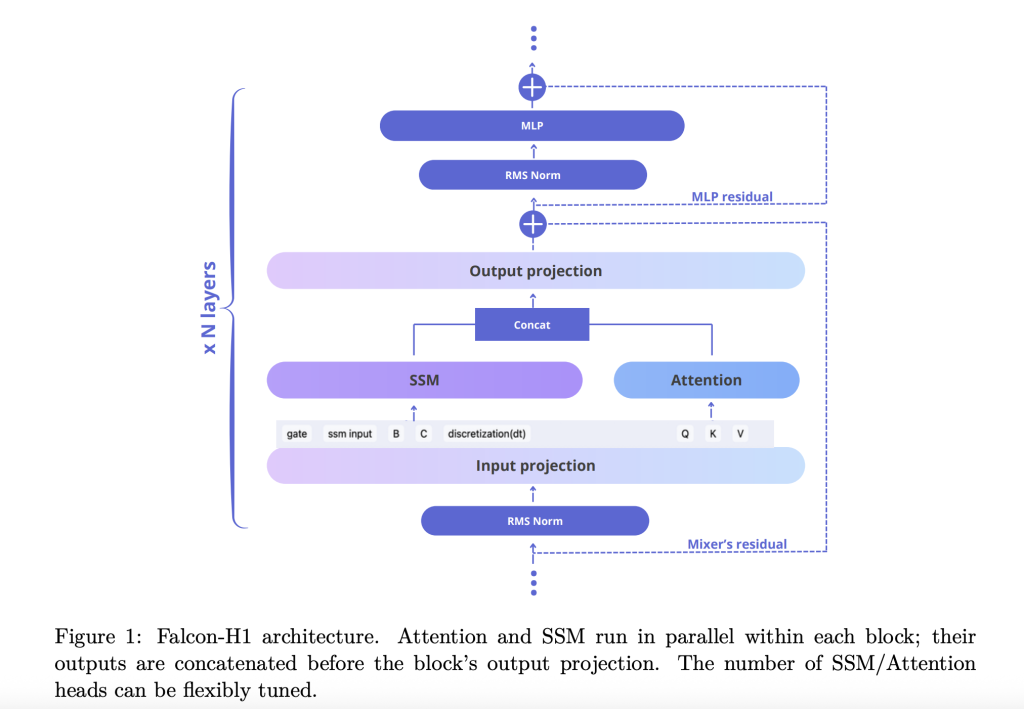
يُوضح التقرير التقني كيفية اعتماد فالكون-H1 لهيكلة هجينة متوازية جديدة، حيث تعمل وحدات الانتباه وSSMs بالتزامن، ويتم دمج نواتجهما قبل الإسقاط. يختلف هذا التصميم عن التكامل التسلسلي التقليدي، ويوفر المرونة لضبط عدد قنوات الانتباه وSSMs بشكل مستقل. يستخدم التكوين الافتراضي نسبة 2:1:5 لقنوات SSM والانتباه وMLP على التوالي، مما يُحسّن كفاءة التعلم وديناميكيته.
لتحسين النموذج أكثر، يستكشف فالكون-H1 ما يلي:
- تخصيص القنوات: تُظهر التجارب أن زيادة قنوات الانتباه تُضعف الأداء، بينما تحقيق التوازن بين SSM وMLP يُحقق مكاسب كبيرة.
- تكوين الكتل: يُظهر تكوين SA_M (متوازي جزئيًا مع تشغيل الانتباه وSSM معًا، يتبعه MLP) أفضل أداء في خسارة التدريب والكفاءة الحسابية.
- تردد قاعدة RoPE: أثبت تردد قاعدة مرتفع بشكل غير عادي يبلغ 10^11 في تضمينات المواضع الدورانية (RoPE) أنه مثالي، مما يحسّن التعميم أثناء تدريب السياق الطويل.
- التوازن بين العرض والعمق: تُظهر التجارب أن النماذج الأعمق تتفوق على النماذج الأوسع ضمن ميزانيات المعلمات الثابتة. يتفوق نموذج Falcon-H1-1.5B-Deep (66 طبقة) على العديد من نماذج 3B و7B.
استراتيجية المُعالج اللغوي
يستخدم فالكون-H1 مجموعة مُخصصة من مُعالج ترميز الأزواج الثنائية (BPE) بأحجام مُفردات تتراوح من 32 ألف إلى 261 ألف. وتشمل الخيارات الرئيسية للتصميم:
- تقسيم الأرقام وعلامات الترقيم: يُحسّن الأداء تجريبيًا في إعدادات البرمجة واللغات المتعددة.
- حقن رمز LATEX: يُعزز دقة النموذج في معايير الرياضيات.
- دعم اللغات المتعددة: يُغطي 18 لغة ويتوسع إلى أكثر من 100 لغة، باستخدام مقاييس خصوبة محسّنة وبايت/رمز.
مجموعة بيانات التدريب واستراتيجية البيانات
تم تدريب نماذج فالكون-H1 على ما يصل إلى 18 تريليون رمز من مجموعة بيانات مُدققة بعناية تتكون من 20 تريليون رمز، وتشمل:
- بيانات الويب عالية الجودة (FineWeb المُفلترة).
- مجموعات بيانات متعددة اللغات: Common Crawl، ويكيبيديا، arXiv، OpenSubtitles، وموارد مُدققة لـ 17 لغة.
- مجموعة بيانات التعليمات البرمجية: 67 لغة، مُعالجة عبر إزالة الازدواجية باستخدام MinHash، ومرشحات جودة CodeBERT، وإزالة المعلومات الشخصية.
- مجموعات بيانات الرياضيات: MATH، GSM8K، وعمليات بحث مُحسّنة بـ LaTeX داخلية.
- بيانات اصطناعية: مُعاد كتابتها من مجموعات بيانات خام باستخدام نماذج لغات ضخمة متنوعة، بالإضافة إلى أسئلة وأجوبة على طراز الكتب الدراسية من 30 ألف موضوع قائم على ويكيبيديا.
- تسلسلات سياقية طويلة: مُحسّنة عبر Fill-in-the-Middle، وإعادة الترتيب، ومهام الاستدلال الاصطناعي التي تصل إلى 256 ألف رمز.
البنية التحتية لمنهجية التدريب
استخدم التدريب معلمات تحديث قصوى مُخصصة (µP)، مما يدعم التوسع السلس عبر أحجام النماذج. تستخدم النماذج استراتيجيات موازاة مُتقدمة:
- موازاة المُخلط (MP):
- موازاة السياق (CP): تُعزز الإنتاجية لمعالجة السياق الطويل.
- الكمية: مُتاحة في متغيرات bfloat16 و 4 بت لتسهيل عمليات النشر على الأجهزة الطرفية.
التقييم والأداء
يحقق فالكون-H1 أداءً غير مسبوق لكل معلمة:
- يتفوق Falcon-H1-34B-Instruct أو يُطابق نماذج بحجم 70B مثل Qwen2.5-72B وLLaMA3.3-70B عبر مهام الاستدلال، والرياضيات، واتباع التعليمات، واللغات المتعددة.
- يُنافس Falcon-H1-1.5B-Deep نماذج 7B-10B.
- يُوفر Falcon-H1-0.5B أداء نماذج 7B لعام 2024.
تشمل المعايير MMLU، GSM8K، HumanEval، ومهام السياق الطويل. تُظهر النماذج محاذاة قوية عبر SFT وتحسين التفضيل المباشر (DPO).
الخاتمة
يُحدد فالكون-H1 معيارًا جديدًا لنماذج اللغات الضخمة مفتوحة الوزن من خلال دمج الهياكل الهجينة المتوازية، والتحليل اللغوي المرن، وديناميكيات التدريب الفعالة، والقدرة المتعددة اللغات القوية. يسمح مزيجه الاستراتيجي من SSM والانتباه بأداء غير مسبوق ضمن ميزانيات الحوسبة والذاكرة العملية، مما يجعله مثاليًا لكل من البحث والنشر عبر بيئات متنوعة.
يمكنكم الاطلاع على الورقة البحثية والنماذج على Hugging Face.






اترك تعليقاً