نموذج rStar2-Agent: ثورة في التفكير الرياضي بفضل التعلم المعزز الوكيل
يُقدم هذا المقال تحليلاً شاملاً لنموذج rStar2-Agent، وهو نموذج لغوي ضخم جديد من مايكروسوفت متخصص في المنطق الرياضي، والذي حقق أداءً متفوقاً باستخدام تقنية التعلم المعزز الوكيل. يُبرز المقال الإنجازات الرئيسية للنموذج، والتحديات التقنية التي تم التغلب عليها، واستراتيجية التدريب الفريدة، بالإضافة إلى نتائج البحث المذهلة وآليات عمل النموذج.
مشكلة “التفكير لفترة أطول”
حققت نماذج اللغات الكبيرة تقدماً ملحوظاً في مجال التفكير الرياضي من خلال توسيع عمليات سلسلة الأفكار (Chain-of-Thought – CoT)، والتي تُعرف بـ”التفكير لفترة أطول” عبر خطوات استدلالية أكثر تفصيلاً. مع ذلك، يعاني هذا النهج من قيود جوهرية. فعندما تواجه النماذج أخطاءً دقيقة في سلاسل استدلالها، فإنها غالباً ما تُضخم هذه الأخطاء بدلاً من اكتشافها وتصحيحها. كما أن التأمل الذاتي الداخلي غالباً ما يفشل، خاصة عندما يكون نهج الاستدلال الأولي معيباً أساساً. يقدم بحث مايكروسوفت الجديد نموذج rStar2-Agent، الذي يتبنى نهجاً مختلفاً: بدلاً من مجرد التفكير لفترة أطول، يُعلم النموذج التفكير بشكل أذكى من خلال استخدام أدوات البرمجة بنشاط للتحقق من صحة استدلالاته، واستكشافها، وصقلها.
النهج الوكيل (Agentic Approach)
يمثل نموذج rStar2-Agent تحولاً نحو التعلم المعزز الوكيل، حيث يتفاعل نموذج ذو 14 مليار معلمة مع بيئة تنفيذ بايثون طوال عملية الاستدلال. بدلاً من الاعتماد فقط على التأمل الذاتي، يمكن للنموذج كتابة الشفرة، وتنفيذها، وتحليل النتائج، وتعديل نهجه بناءً على ردود فعل ملموسة. يُنشئ هذا عملية حل ديناميكية للمشاكل. عندما يواجه النموذج مشكلة رياضية معقدة، فقد يقوم بإنشاء استدلال أولي، وكتابة شفرة بايثون لاختبار الفرضيات، وتحليل نتائج التنفيذ، والتكرار حتى الوصول إلى الحل. يُحاكي هذا النهج الطريقة التي يعمل بها علماء الرياضيات البشر غالباً – باستخدام أدوات الحوسبة للتحقق من الحدس واستكشاف مسارات حلول مختلفة.
التحديات والحلول المتعلقة بالبنية التحتية
يُشكل توسيع نطاق التعلم المعزز الوكيل تحديات تقنية كبيرة. خلال التدريب، يمكن لمجموعة بيانات واحدة أن تولد عشرات الآلاف من طلبات تنفيذ الشفرة المتزامنة، مما يُنشئ اختناقات قد تُعيق استخدام وحدات معالجة الرسوميات (GPUs). عالج الباحثون هذه المشكلة من خلال ابتكارين رئيسيين في البنية التحتية:
- خدمة تنفيذ شفرة موزعة: قادرة على التعامل مع 45,000 طلب أداة متزامن مع زمن انتقال أقل من ثانية واحدة. يعزل النظام تنفيذ الشفرة عن عملية التدريب الرئيسية مع الحفاظ على الإنتاجية العالية من خلال موازنة التحميل بعناية عبر عمال وحدة المعالجة المركزية (CPUs).
- جدولة نشر ديناميكية: تُخصص العمل الحسابي بناءً على توفر ذاكرة التخزين المؤقت لوحدات معالجة الرسوميات في الوقت الفعلي بدلاً من التخصيص الثابت. يمنع هذا وقت الخمول لوحدات معالجة الرسوميات الناجم عن توزيع غير متساوٍ لأحمال العمل – وهي مشكلة شائعة عندما تتطلب بعض مسارات الاستدلال حسابات أكثر بكثير من غيرها.
أدت هذه التحسينات في البنية التحتية إلى إتمام عملية التدريب بأكملها في أسبوع واحد فقط باستخدام 64 وحدة معالجة رسوميات AMD MI300X، مما يدل على أن قدرات الاستدلال المتقدمة لا تتطلب موارد حسابية هائلة عند تنظيمها بكفاءة.
GRPO-RoC: التعلم من الأمثلة عالية الجودة
الابتكار الخوارزمي الرئيسي هو تحسين سياسة المجموعة النسبية مع إعادة أخذ العينات على الصحيح (GRPO-RoC). يواجه التعلم المعزز التقليدي في هذا السياق مشكلة في الجودة: تتلقى النماذج مكافآت إيجابية للإجابات النهائية الصحيحة حتى عندما تتضمن عملية استدلالها أخطاء متعددة في الشفرة أو استخدام غير فعال للأدوات. يعالج GRPO-RoC هذه المشكلة من خلال تنفيذ استراتيجية أخذ عينات غير متناظرة. خلال التدريب، تقوم الخوارزمية بما يلي:
- إعادة أخذ عينات من عمليات النشر الأولية: لإنشاء مجموعة أكبر من مسارات الاستدلال.
- الحفاظ على التنوع في المحاولات الفاشلة: للحفاظ على التعلم من أنماط الأخطاء المختلفة.
- تصفية الأمثلة الإيجابية: للتأكيد على المسارات التي تحتوي على أخطاء أدنى في الأدوات وتنسيق أنظف.
يضمن هذا النهج أن يتعلم النموذج من الاستدلال الناجح عالي الجودة مع الحفاظ على التعرض لأنماط الفشل المتنوعة. النتيجة هي استخدام أكثر كفاءة للأدوات ومسارات استدلال أقصر وأكثر تركيزاً.
استراتيجية التدريب: من البسيط إلى المعقد
تتطور عملية التدريب على ثلاث مراحل مصممة بعناية، بدءاً من ضبط دقيق خاضع للإشراف غير قائم على الاستدلال يركز فقط على اتباع التعليمات وتنسيق الأدوات – وتجنب عمداً أمثلة الاستدلال المعقدة التي قد تُنشئ تحيزات مبكرة.
- المرحلة الأولى: تُقيّد الردود إلى 8000 رمز، مما يُجبر النموذج على تطوير استراتيجيات استدلال موجزة. على الرغم من هذا القيد، فإن الأداء يقفز بشكل كبير – من ما يقرب من الصفر إلى أكثر من 70% في المعايير الصعبة.
- المرحلة الثانية: تُوسع حد الرموز إلى 12000، مما يسمح باستدلال أكثر تعقيداً مع الحفاظ على مكاسب الكفاءة من المرحلة الأولى.
- المرحلة الثالثة: يُركز على أصعب المشاكل عن طريق تصفية تلك التي أتقنها النموذج بالفعل، مما يضمن الاستمرار في التعلم من الحالات الصعبة.
يُعظم هذا التقدم من الاستدلال الموجز إلى الموسع، بالإضافة إلى زيادة صعوبة المشكلة، كفاءة التعلم مع تقليل الحد الأدنى من الموارد الحسابية.
النتائج المذهلة
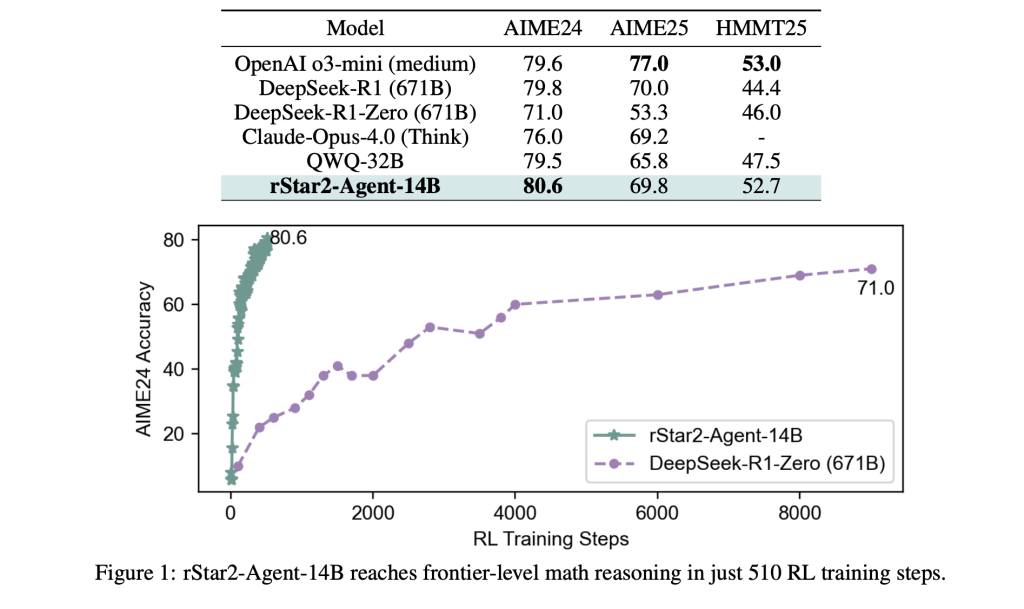
النتائج مذهلة. يحقق نموذج rStar2-Agent-14B دقة 80.6% على AIME24 و 69.8% على AIME25، متجاوزاً نماذج أكبر بكثير بما في ذلك نموذج DeepSeek-R1 الذي يحتوي على 671 مليار معلمة. ولعل الأهم من ذلك، أنه يُنجز هذا باستخدام مسارات استدلال أقصر بكثير – بمعدل حوالي 10000 رمز مقارنة بأكثر من 17000 لنماذج مماثلة. تتجاوز مكاسب الكفاءة الرياضيات. على الرغم من التدريب حصرياً على المشاكل الرياضية، يُظهر النموذج قدرة قوية على نقل التعلم، متفوقاً على النماذج المتخصصة في معايير الاستدلال العلمي والحفاظ على أداء تنافسي في مهام المحاذاة العامة.
فهم الآليات
يكشف تحليل النموذج المدرب عن أنماط سلوكية رائعة. تندرج الرموز عالية الإنتروبيا في مسارات الاستدلال في فئتين: رموز “التفرع” التقليدية التي تُحفز التأمل الذاتي والاستكشاف، وفئة جديدة من “رموز التأمل” التي تظهر تحديداً استجابةً لردود فعل الأداة. تمثل رموز التأمل شكلاً من أشكال الاستدلال المُدار بيئياً حيث يقوم النموذج بتحليل نتائج تنفيذ الشفرة بعناية، وتشخيص الأخطاء، وتعديل نهجه وفقاً لذلك. يُنشئ هذا سلوكاً أكثر تطوراً لحل المشكلات مما يمكن أن يحققه الاستدلال CoT البحت.
الخلاصة
يُظهر نموذج rStar2-Agent أن النماذج متوسطة الحجم يمكن أن تحقق استدلالاً متقدماً من خلال تدريب متطور بدلاً من التوسع القسري. يُشير هذا النهج إلى مسار أكثر استدامة نحو قدرات الذكاء الاصطناعي المتقدمة – مسار يُركز على الكفاءة، ودمج الأدوات، واستراتيجيات التدريب الذكية بدلاً من القوة الحسابية الخام. يُشير نجاح هذا النهج الوكيل أيضاً إلى أنظمة ذكاء اصطناعي مستقبلية يمكنها دمج العديد من الأدوات والبيئات بسلاسة، والانتقال من توليد النصوص الثابتة إلى قدرات حل المشكلات الديناميكية والتفاعلية.
مواضيع مشابهة:
 بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه
بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه



اترك تعليقاً