محرك نقاط التفتيش من MoonshotAI: ثورة في تحديث أوزان نماذج اللغات الضخمة
أطلقت شركة MoonshotAI مشروعًا مفتوح المصدر يُسمى “محرك نقاط التفتيش” (Checkpoint-Engine)، وهو وسيط خفيف الوزن يُعنى بحل إحدى أبرز المعوقات في نشر نماذج اللغات الضخمة (LLM): تحديث أوزان النموذج بسرعة عبر آلاف وحدات معالجة الرسومات (GPUs) دون تعطيل الاستدلال. يُصمم هذا المحرك خصيصًا لتعزيز التعلم (RL) وتعزيز التعلم مع الملاحظات البشرية (RLHF)، حيث يتم تحديث النماذج بشكل متكرر، ويؤثر وقت التوقف بشكل مباشر على إنتاجية النظام. يمكنك الاطلاع على المشروع على GitHub.
سرعة غير مسبوقة في تحديث نماذج اللغات الضخمة
يحقق محرك نقاط التفتيش إنجازًا هائلاً من خلال تحديث نموذج يحتوي على تريليون معلمة عبر آلاف وحدات معالجة الرسومات في حوالي 20 ثانية فقط. مقارنةً بذلك، تتطلب خطوط أنابيب الاستدلال المُوزعة التقليدية عدة دقائق لإعادة تحميل نماذج بهذا الحجم. من خلال تقليل وقت التحديث بعامل عشرة، يعالج محرك نقاط التفتيش بشكل مباشر إحدى أكبر حالات عدم الكفاءة في الخدمات على نطاق واسع.
يُحقق النظام هذا من خلال:
- التحديثات الإذاعية للمجموعات الثابتة: يتم بث التحديثات بكفاءة عالية للمجموعات الثابتة من وحدات معالجة الرسومات.
- التحديثات من نظير إلى نظير (P2P) للمجموعات الديناميكية: تسمح هذه الطريقة بتحديثات مرنة في بيئات تتغير فيها الموارد باستمرار.
- تداخل الاتصال ونسخ الذاكرة: يُقلل هذا من زمن الوصول ويضمن استمرار عمل وحدات معالجة الرسومات خلال عملية التحديث.
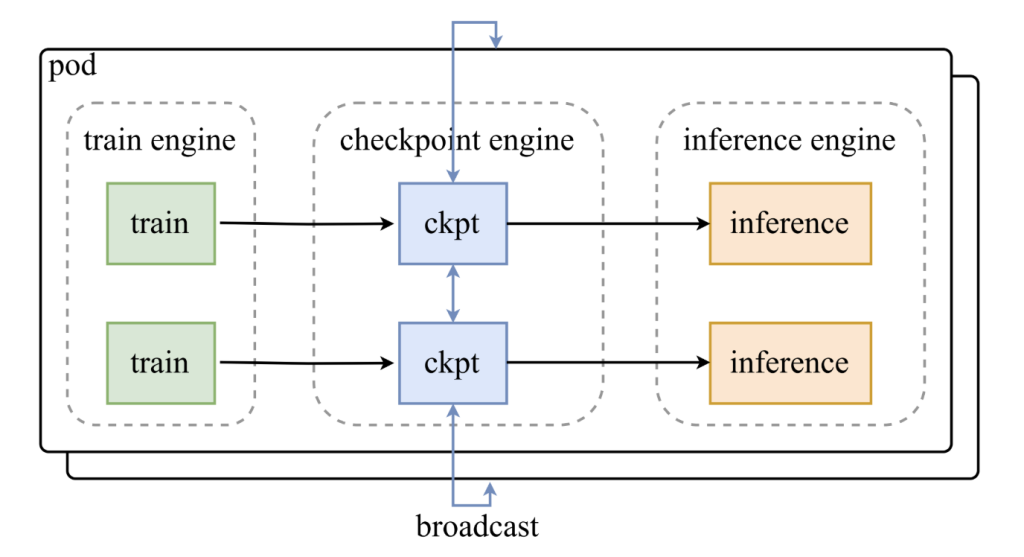
بنية محرك نقاط التفتيش
يقع محرك نقاط التفتيش بين محركات التدريب ومجموعات الاستدلال. وتتضمن تصميمه:
- خادم المعلمات (Parameter Server): ينسق التحديثات بين وحدات معالجة الرسومات المختلفة.
- امتدادات العامل (Worker Extensions): تتكامل مع أطر عمل الاستدلال مثل vLLM.
وتعمل خط أنابيب تحديث الأوزان في ثلاث مراحل:
- من المضيف إلى الجهاز (H2D): يتم نسخ المعلمات إلى ذاكرة وحدة معالجة الرسومات.
- البث (Broadcast): يتم توزيع الأوزان على العمال باستخدام مخازن CUDA IPC.
- إعادة التحميل (Reload): يعيد كل جزء استدلال تحميل المجموعة الفرعية من الأوزان التي يحتاجها فقط.
تم تحسين خط الأنابيب هذا لتداخل المراحل، مما يضمن بقاء وحدات معالجة الرسومات نشطة طوال عملية التحديث.
الأداء العملي
تؤكد نتائج قياس الأداء على قابلية محرك نقاط التفتيش للتطوير:
- GLM-4.5-Air (BF16، 8×H800): 3.94 ثانية (بث)، 8.83 ثانية (P2P).
- Qwen3-235B-Instruct (BF16، 8×H800): 6.75 ثانية (بث)، 16.47 ثانية (P2P).
- DeepSeek-V3.1 (FP8، 16×H20): 12.22 ثانية (بث)، 25.77 ثانية (P2P).
- Kimi-K2-Instruct (FP8، 256×H20): ~21.5 ثانية (بث)، 34.49 ثانية (P2P).
حتى مع نماذج تريليون معلمة و 256 وحدة معالجة رسومات، تكتمل التحديثات الإذاعية في حوالي 20 ثانية، مما يُثبت هدف التصميم.
المقايضات
يقدم محرك نقاط التفتيش مزايا ملحوظة، ولكنه يأتي أيضًا ببعض القيود:
- زيادة استخدام الذاكرة: تتطلب خطوط الأنابيب المتداخلة ذاكرة إضافية لوحدة معالجة الرسومات؛ فإن عدم كفاية الذاكرة يؤدي إلى مسارات بديلة أبطأ.
- زمن الوصول في تحديثات P2P: تدعم تحديثات نظير إلى نظير المجموعات المرنة، لكنها تأتي بتكلفة أداء.
- التوافق: تم اختباره رسميًا مع vLLM فقط؛ يتطلب دعم محركات أوسع عملًا هندسيًا إضافيًا.
- الكمية: يوجد دعم FP8 ولكنه لا يزال تجريبيًا.
سيناريوهات النشر
يُعد محرك نقاط التفتيش ذا قيمة كبيرة لـ:
- خطوط أنابيب تعزيز التعلم التي تتطلب تحديثات متكررة للأوزان.
- مجموعات استدلال كبيرة تخدم نماذج بمعلمات تتراوح بين 100 مليار وتريليون معلمة أو أكثر.
- البيئات المرنة ذات المقياس الديناميكي، حيث تُعوض مرونة P2P عن تأخيرات الأداء.
الخلاصة
يمثل محرك نقاط التفتيش حلاً مركزًا لإحدى أصعب المشاكل في نشر نماذج اللغات الضخمة على نطاق واسع: وهي مزامنة الأوزان بسرعة دون إيقاف الاستدلال. مع التحديثات المُثبتة على نطاق تريليون معلمة في حوالي 20 ثانية، والدعم المرن لكل من وضعي البث و P2P، وخط أنابيب اتصال مُحسّن، فإنه يوفر مسارًا عمليًا لخطوط أنابيب تعزيز التعلم ومجموعات الاستدلال عالية الأداء. على الرغم من أنه لا يزال محدودًا بـ vLLM ويتطلب تحسينات في الكمية والمقياس الديناميكي، إلا أنه يُشكل أساسًا مهمًا لتحديثات النماذج الفعالة والمتواصلة في أنظمة الذكاء الاصطناعي الإنتاجية.




اترك تعليقاً