إطار عمل آر-زيرو: ثورة في تدريب نماذج اللغات الكبيرة ذات القدرة على التفكير
يُعَدّ تطوير نماذج اللغات الكبيرة (LLMs) ذات قدرة تفكير خارقة تحديًا كبيرًا في مجال الذكاء الاصطناعي. ففي حين حققت هذه النماذج تقدمًا مذهلًا في مجالات فهم اللغة الطبيعية، و البرمجة، وحتى الاستدلال، إلا أن الوصول إلى مستويات تفوق القدرات البشرية ما زال مُقيّدًا بضرورة الاعتماد على مجموعات بيانات ضخمة وعالية الجودة، و التي غالبًا ما تكون مُعلّمة يدويًا بواسطة البشر، وهي عملية مكلفة وتستغرق وقتًا طويلًا. يُقدّم لنا إطار عمل “آر-زيرو” (R-Zero) نهجًا ثوريًا جديدًا للتغلب على هذه العقبة.
آر-زيرو: التطور الذاتي من الصفر
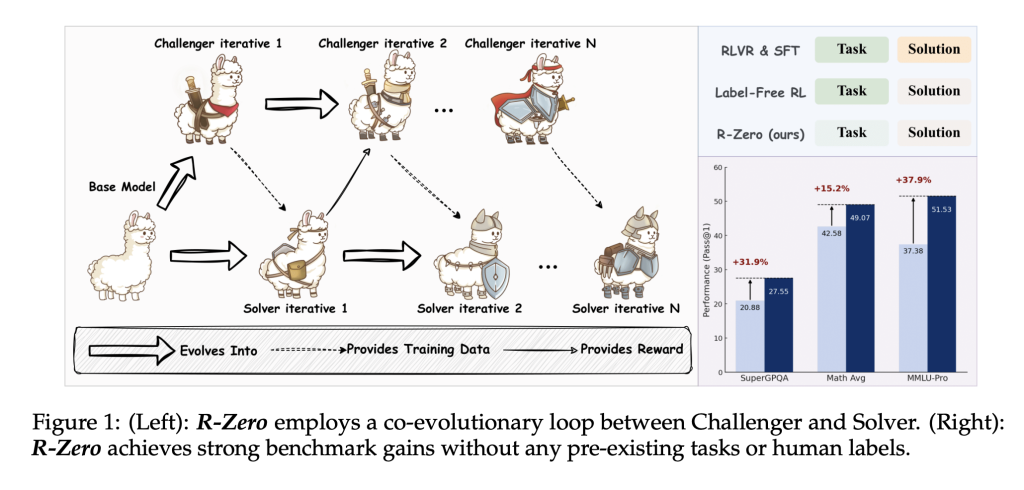
يُغيّر آر-زيرو قواعد اللعبة من خلال التخلص تمامًا من الاعتماد على البيانات الخارجية المُعلّمة. فهو يعتمد على آلية تطورية مشتركة بين نموذجين أساسيين:
المُنافِس (Challenger):
- مسؤول عن توليد مسائل جديدة ومعقدة تُمثّل تحديًا لقدرة المُحلّل (Solver).
- يُدرّب باستخدام تقنية تعزيز التعلم (Reinforcement Learning)، وتحديدًا خوارزمية “تحسين السياسة النسبية الجماعية” (GRPO).
- يُكافأ على توليد أسئلة صعبة بدرجة كافية بحيث تصل نسبة نجاح المُحلّل في الإجابة عليها إلى حوالي 50%، مما يُعزّز كفاءة عملية التعلم.
المُحلّل (Solver):
- يُدرّب على حلّ المسائل التي يولدها المُنافِس.
- تُحدّد الإجابات الصحيحة من خلال تصويت الأغلبية بين إجابات المُحلّل نفسه.
- يُستخدم فقط الأزواج “سؤال-إجابة” ذات مستوى متوسط من الاتساق في التدريب، مما يُساعد في تصفية الأسئلة الغامضة أو غير المحددة جيدًا.
آلية العمل التكراري
يعمل آر-زيرو من خلال دورة تكرّارية بين المُنافِس و المُحلّل:
- مرحلة التدريب الأولى: يُدرّب المُنافِس على توليد أسئلة جديدة.
- مرحلة التدريب الثانية: يُدرّب المُحلّل على حلّ الأسئلة التي وُلدت في المرحلة السابقة.
- التكرار: يُكرّر هذان النموذجان دوريهما عدة مرات، مُحسّنين قدراتهما على التفكير بشكل مُتزايد دون أي تدخّل بشري.
الابتكارات التقنية الرئيسية
- تحسين السياسة النسبية الجماعية (GRPO): خوارزمية تعزيز التعلم التي تُحسّن من كفاءة تدريب نماذج اللغات الكبيرة.
- منهاج تعليمي قائم على عدم اليقين: يُكافأ المُنافِس على توليد أسئلة صعبة بدرجة كافية، مما يُعزّز من كفاءة التعلم.
- عقوبة التكرار والتحقق من التنسيق: ضمان تنوّع البيانات وجودتها.
- مراقبة جودة التصنيفات الوهمية: ضمان دقة البيانات المُستخدمة في التدريب.
الأداء التجريبي
أظهر آر-زيرو نتائج مُذهلة في العديد من معايير قياس الأداء:
معايير قياس الأداء الرياضي:
- تم تقييم آر-زيرو باستخدام سبعة معايير رياضية صارمة، بما في ذلك مسابقات AMC و Minerva و MATH-500 و GSM8K و Olympiad-Bench و AIME.
- حقق تحسينات كبيرة في دقة الاستدلال الرياضي عبر جميع أحجام النماذج والهندسات المعمارية.
معايير قياس الأداء العامة:
- أظهر آر-زيرو تحسينات كبيرة في دقة الاستدلال في المجالات العامة، مما يُشير إلى قدرته على نقل المعرفة المكتسبة.
الخلاصة
يُمثّل آر-زيرو إنجازًا كبيرًا نحو تطوير نماذج لغات كبيرة ذات قدرة تفكير ذاتية ومتفوقة. يُقدّم هذا الإطار نهجًا جديدًا وواعدًا لتطوير أنظمة ذكاء اصطناعي قابلة للتطوير دون الحاجة إلى بيانات مُعلّمة يدويًا.





اترك تعليقاً