إدارة الذاكرة الذكية في نماذج اللغات الكبيرة: إطار عمل Memory-R1
تُعتبر نماذج اللغات الكبيرة (LLMs) ركيزةً أساسيةً في العديد من الإنجازات الحديثة في مجال الذكاء الاصطناعي، بدءًا من روبوتات المحادثة ومساعدي البرمجة ووصولاً إلى الإجابة على الأسئلة والكتابة الإبداعية. مع ذلك، تعاني هذه النماذج من قصورٍ رئيسي يتمثل في افتقارها للذاكرة الدائمة؛ فكل استعلام يُعامل بشكلٍ مستقل دون أي تذكر للاستعلامات السابقة. تُحدّ نافذة السياق الثابتة من قدرتها على تراكم المعرفة عبر محادثات طويلة أو مهام متعددة الجلسات، كما تُعيق قدرتها على الاستدلال على أساس سجلات معقدة.
تحديات إدارة الذاكرة في نماذج اللغات الكبيرة
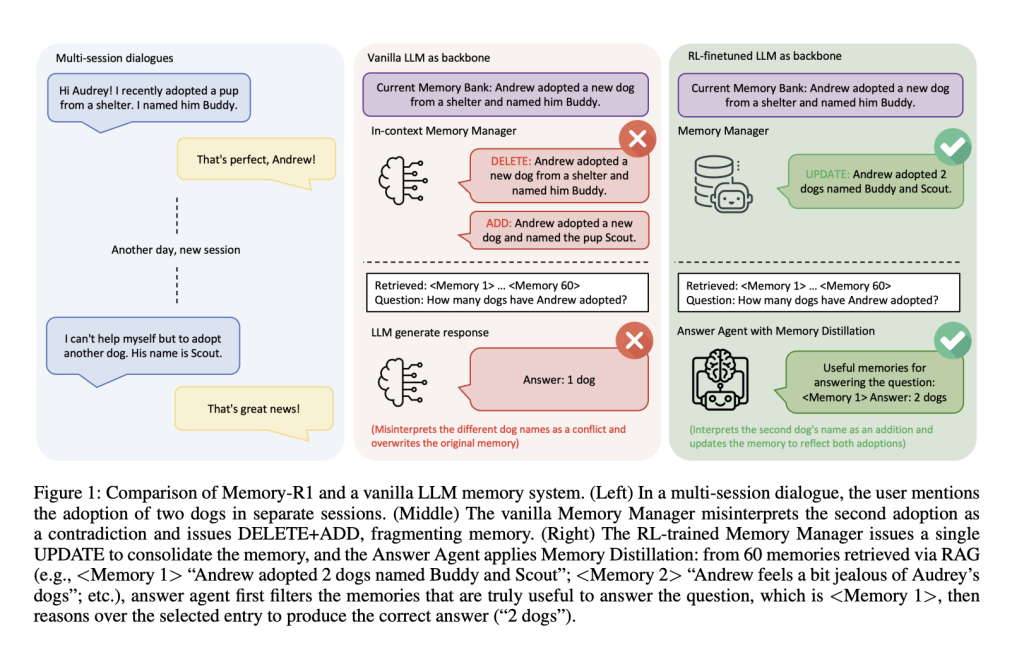
تُقدم الحلول الحديثة، مثل توليد الإجابات المُعزّزة بالاسترجاع (RAG)، معلومات سابقة كمدخلات إضافية، لكن هذا غالبًا ما يؤدي إلى سياقٍ ضجيج مليء بالتفاصيل غير ذات الصلة أو ينقصه معلومات أساسية. تخيل محادثة متعددة الجلسات: في الجلسة الأولى، يقول المستخدم: “تبنيت كلبًا اسمه بودي”. لاحقًا، يضيف: “تبنيت كلبًا آخر اسمه سكوت”. هل يجب على النظام استبدال البيان الأول بالثاني، أو دمجها، أو تجاهل التحديث؟ غالباً ما تفشل أنظمة الذاكرة التقليدية، حيث قد تمحو “بودي” وتضيف “سكوت”، مُفسرةً المعلومات الجديدة على أنها تناقض بدلاً من توضيح. مع مرور الوقت، تفقد هذه الأنظمة تماسكها، مُجزئةً معرفة المستخدم بدلاً من تطويرها. تستعيد أنظمة RAG المعلومات لكنها لا تُصفّيها؛ مما يؤدي إلى تلويث عملية الاستدلال وتشتيت انتباه النموذج. على النقيض من ذلك، يسترجع البشر المعلومات على نطاق واسع، ثم يُصفّون ما هو مهم بشكل انتقائي.
إطار عمل Memory-R1: حلول مبتكرة
للتغلب على هذه التحديات، قدم باحثون من جامعة ميونخ، والجامعة التقنية في ميونخ، وجامعة كامبريدج، وجامعة هونغ كونغ إطار عمل Memory-R1، وهو عبارة عن هيكل يُعلّم وكلاء نماذج اللغات الكبيرة (LLM) كيفية اتخاذ القرارات بشأن ما يجب تذكره وكيفية استخدامه. يتعلم وكيل LLM في هذا الإطار إدارة واستخدام الذاكرة الخارجية بنشاط، حيث يقرر ما يجب إضافته، وتحديثه، وحذفه، أو تجاهله، ويُصفّي الضوضاء عند الإجابة على الأسئلة.
مكونات إطار عمل Memory-R1:
يتألف Memory-R1 من وكيلين متخصصين مُدربين باستخدام تقنيات التعلم المعزز:
-
مدير الذاكرة (Memory Manager): يقرر عمليات الذاكرة (إضافة، تحديث، حذف، عدم إجراء عملية) التي يجب تنفيذها بعد كل جولة من الحوار، مُحدّثًا بنك الذاكرة الخارجي ديناميكيًا.
-
وكيل الإجابة (Answer Agent): يسترجع ما يصل إلى 60 ذكرى مرشحة لكل سؤال من المستخدم، ويُقطر هذه الذكريات إلى مجموعة فرعية أكثر صلة، ثم يستدل على أساس هذا السياق المُصفّى لإنتاج إجابة.
يتم تدريب كلا المكونين باستخدام التعلم المعزز (RL)، إما باستخدام خوارزمية “تحسين السياسة القريبة” (PPO) أو “تحسين السياسة النسبية الجماعية” (GRPO)، مع استخدام دقة الإجابة على السؤال كمكافأة فقط. هذا يعني أنه بدلاً من الحاجة إلى تمييز عمليات الذاكرة يدويًا، يتعلم الوكلاء من خلال التجربة والخطأ، مُحسّنين الأداء النهائي للمهمة.
مدير الذاكرة: تعلم تعديل المعرفة
بعد كل جولة حوار، يستخرج LLM الحقائق الرئيسية. ثم يسترجع مدير الذاكرة الإدخالات ذات الصلة من بنك الذاكرة، ويختار عملية:
- إضافة (ADD): إدراج معلومات جديدة غير موجودة بالفعل.
- تحديث (UPDATE): دمج تفاصيل جديدة في الذكريات الموجودة عندما تُوضح أو تُحسّن الحقائق السابقة.
- حذف (DELETE): إزالة المعلومات عتيقة الطراز أو المتناقضة.
- عدم إجراء عملية (NOOP): ترك الذاكرة دون تغيير إذا لم يتم إضافة أي شيء ذي صلة.
يتم تحديث مدير الذاكرة بناءً على جودة الإجابات التي يُنتجها وكيل الإجابة من بنك الذاكرة المُعدّل حديثًا. إذا مكّنت عملية الذاكرة وكيل الإجابة من الاستجابة بدقة، يحصل مدير الذاكرة على مكافأة إيجابية. تُلغي هذه المكافأة القائمة على النتائج الحاجة إلى التسمية اليدوية المكلفة لعمليات الذاكرة.
وكيل الإجابة: الاستدلال الانتقائي
يسترجع النظام ما يصل إلى 60 ذكرى مرشحة لكل سؤال باستخدام RAG. ولكن بدلاً من إرسال كل هذه الذكريات إلى LLM، يُقطر وكيل الإجابة المجموعة أولاً، مُحتفظًا فقط بالإدخالات الأكثر صلة. بعد ذلك فقط، يُولّد إجابة. يتم تدريب وكيل الإجابة أيضًا باستخدام التعلم المعزز، باستخدام التطابق الدقيق بين إجابته والإجابة الصحيحة كمكافأة. هذا يشجعه على التركيز على تصفية الضوضاء والاستدلال على سياق عالي الجودة.
كفاءة البيانات في التدريب والنتائج التجريبية
يتميز Memory-R1 بكفاءة عالية في استخدام البيانات، حيث يحقق نتائج قوية باستخدام 152 زوجًا فقط من أسئلة وأجوبة للتدريب. يُعزى ذلك إلى أن الوكيل يتعلم من النتائج، وليس من آلاف عمليات الذاكرة المُميزة يدويًا. تم اختبار Memory-R1 على نماذج LLaMA-3.1-8B-Instruct و Qwen-2.5-7B-Instruct، مُحققًا تحسينات ملحوظة مقارنةً بالخطوط الأساسية الأخرى.
أهمية Memory-R1
يُظهر Memory-R1 أنه يمكن تعلم إدارة الذاكرة واستخدامها، حيث لا تحتاج وكلاء LLM إلى الاعتماد على أساليب تقليدية هشة. من خلال ربط القرارات بالتعلم المعزز القائم على النتائج، يُحقق النظام:
- توحيد المعرفة تلقائيًا مع تطور المحادثات، بدلاً من تجزئتها أو الكتابة فوقها.
- تصفية الضوضاء عند الإجابة، مما يُحسّن دقة الحقائق وجودة الاستدلال.
- التعلم بكفاءة مع الحد الأدنى من الإشراف، والتوسع إلى المهام طويلة الأمد في العالم الحقيقي.
- التعميم عبر النماذج، مما يجعله أساسًا واعدًا للجيل التالي من أنظمة الذكاء الاصطناعي الذكية والواعية للذاكرة.
أسئلة شائعة
س1: ما الذي يجعل Memory-R1 أفضل من أنظمة ذاكرة LLM النموذجية؟
يستخدم Memory-R1 التعلم المعزز للتحكم النشط في الذاكرة، مُقررًا المعلومات التي يجب إضافتها أو تحديثها أو حذفها أو الاحتفاظ بها، مما يُمكّنه من توحيد أكثر ذكاءً وتجزئة أقل من الأساليب التقليدية الثابتة.
س2: كيف يُحسّن Memory-R1 جودة الإجابة من سجلات الحوار الطويلة؟
يُطبق وكيل الإجابة سياسة “تقطير الذاكرة”: يُصفّي ما يصل إلى 60 ذكرى مُسترجعة لعرض تلك الأكثر صلة بكل سؤال، مما يُقلل من الضوضاء ويُحسّن دقة الحقائق مقارنةً بمرور كل السياق إلى النموذج.
س3: هل Memory-R1 كفؤ من حيث البيانات في التدريب؟
نعم، يحقق Memory-R1 مكاسب متطورة باستخدام 152 زوجًا فقط من التدريب على الأسئلة والأجوبة، حيث تُلغي مكافآته القائمة على النتائج الحاجة إلى التسمية اليدوية المكلفة لكل عملية ذاكرة.
مواضيع مشابهة:
 DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
 بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena
بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena



اترك تعليقاً