VoXtream: ثورة في تقنية تحويل النص إلى كلام
يُعاني مجال تحويل النص إلى كلام (TTS) من مشكلة تأخير البداية، حيث تنتظر معظم النماذج استلام جزء من النص قبل بدء إنتاج الصوت، مما يؤدي إلى فترات صمت مزعجة. ولكن، يقدم لنا نموذج VoXtream، الذي طورته مجموعة “الكلام، الموسيقى، والسمع” في معهد KTH الملكي للتكنولوجيا في السويد، حلاً مبتكراً لهذه المشكلة.
ما هو تحويل النص إلى كلام ذو بث كامل (Full-Stream TTS)؟
يختلف VoXtream عن أنظمة بث الصوت التقليدية (Output-streaming) بشكل أساسي. فأنظمة بث الصوت التقليدية تقوم بفك تشفير الكلام على شكل أجزاء، ولكنها تتطلب النص الكامل مسبقًا قبل البدء في عملية فك التشفير. أما VoXtream فيعتمد على تقنية “البث الكامل”، حيث يستهلك النص كلمة بكلمة (مثلًا من نموذج لغوي كبير – LLM) ويصدر الصوت بشكل متزامن. هذا يعني أنه يبتلع تدفق الكلمات ويولد إطارات صوتية بشكل مستمر، مما يلغي الحاجة إلى تخزين مؤقت للنص المدخل مع الحفاظ على معدل حساب منخفض لكل إطار. يركز تصميمه بشكل خاص على بدء النطق من الكلمة الأولى، وليس فقط على معدل الإنتاجية.
كيف يبدأ VoXtream النطق دون انتظار الكلمات التالية؟
تعتمد خدعة VoXtream الرئيسية على آلية “التنبؤ الديناميكي بالصوتيات” داخل مُحول الصوتيات التزايدي (PT). يستطيع PT معاينة ما يصل إلى 10 أصوات لتثبيت الإيقاع، لكنه لا ينتظر وصول هذا السياق الكامل؛ بل يبدأ عملية توليد الصوت مباشرة بعد دخول الكلمة الأولى إلى المخزن المؤقت. هذا يجنب استخدام نوافذ معاينة ثابتة تزيد من زمن بدء النطق.
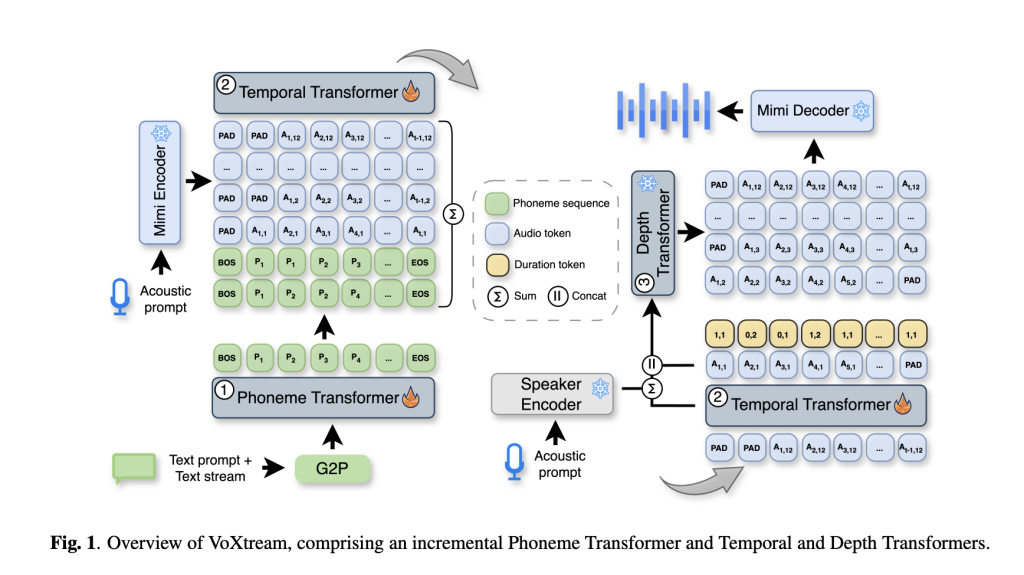
بنية نموذج VoXtream
يتكون VoXtream من خط أنابيب واحد ذاتي الانحدار بالكامل (AR) مع ثلاثة مُحولات:
- مُحول الصوتيات (PT): مُحول فك تشفير فقط، تزايدي، معاينة ديناميكية تصل إلى 10 أصوات، تحويل الكلمات إلى أصوات باستخدام g2pE على مستوى الكلمة.
- المُحول الزمني (TT): مُنبئ ذاتي الانحدار على رموز دلالية من ترميز Mimi بالإضافة إلى رمز مدة يُشفّر محاذاة أحادية التناظر بين الصوتيات والصوت (“ابقَ/اذهب” و {1, 2} صوتيات لكل إطار). يعمل Mimi بمعدل 12.5 هرتز (→ إطارات 80 مللي ثانية).
- المُحول العمقي (DT): مُولد ذاتي الانحدار لكُتب الشفرات الصوتية المتبقية في Mimi، مشروط بمخرجات TT ومدخلات ReDimNet لتمثيل المتحدث لتمكين ميزة “التحفيز الصوتي بدون تدريب مسبق”. يقوم فك تشفير Mimi بإعادة بناء شكل الموجة إطارًا بإطار، مما يسمح بالبث المستمر.
الأداء العملي لـ VoXtream
تُظهر الاختبارات نتائج مبهرة:
- على معالج A100: 171 مللي ثانية / 1.00 RTF بدون تجميع، و 102 مللي ثانية / 0.17 RTF مع تجميع.
- على معالج RTX 3090: 205 مللي ثانية / 1.19 RTF بدون تجميع، و 123 مللي ثانية / 0.19 RTF مع تجميع.
(RTF: معامل الوقت الحقيقي)
مقارنة VoXtream بالأنظمة الأخرى
أظهرت الدراسات أن VoXtream يتفوق على أنظمة بث أخرى، مثل CosyVoice2، من حيث معدل الخطأ في الكلمات (WER) وطبيعية الصوت، مع تحقيق أدنى زمن تأخير. يُلاحظ أن CosyVoice2 يُظهر تشابهاً أكبر مع صوت المتحدث.
لماذا يتفوق التصميم ذاتي الانحدار على تقنيات الانتشار/التدفق؟
تُنتج مشفرات الانتشار/التدفق الصوت عادةً على شكل أجزاء، مما يُحد من زمن التأخير الأولي. يحافظ VoXtream على جميع مراحله ذاتية الانحدار ومتزامنة مع الإطار، مما يسمح بإصدار أول حزمة صوتية (80 مللي ثانية) بعد مرور واحد عبر الخط الأنابيب.
بيانات التدريب
تم تدريب VoXtream على مجموعة بيانات متوسطة الحجم تبلغ حوالي 9000 ساعة: حوالي 4500 ساعة من Emilia و 4500 ساعة من HiFiTTS-2 (مجموعة فرعية 22 كيلوهرتز).
جودة النتائج
أظهرت النتائج أن VoXtream يُقدم جودة تنافسية في معدل الخطأ في الكلمات (WER)، وجودة الصوت (UTMOS)، وتشابه صوت المتحدث.
مكانة VoXtream في مجال TTS
يُعتبر VoXtream إنجازًا مهمًا في مجال تحويل النص إلى كلام، حيث يُقدم حلًا فعالاً لمشكلة التأخير، مع الحفاظ على جودة صوت عالية.
روابط مفيدة
- الورقة البحثية: [رابط الورقة البحثية]
- النموذج على Hugging Face: [رابط النموذج]
- صفحة GitHub: [رابط صفحة GitHub]







اترك تعليقاً