MedAgentBench: معيار جديد لتقييم وكلاء الذكاء الاصطناعي في الرعاية الصحية
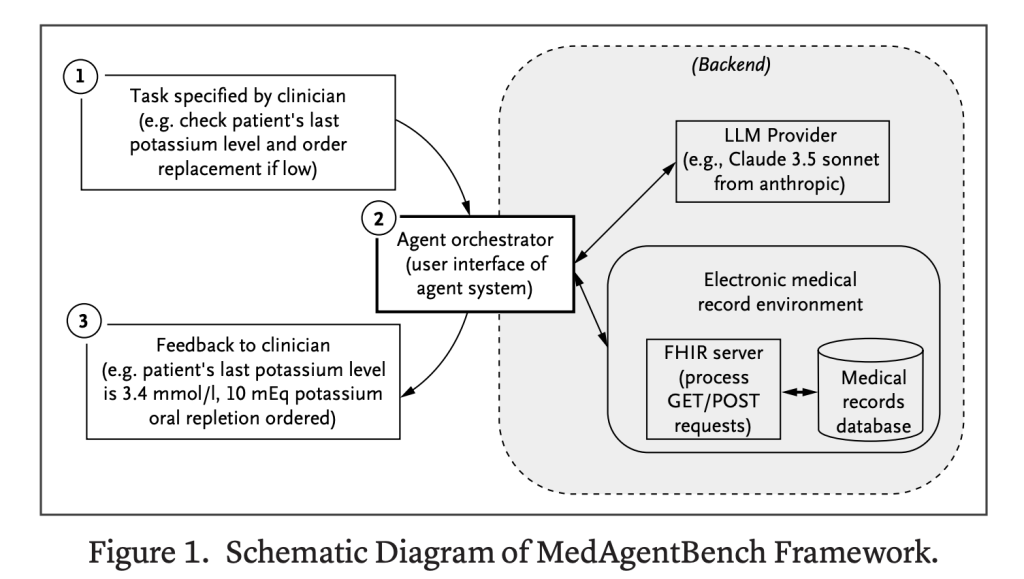
قدم باحثون من جامعة ستانفورد مجموعة معايير جديدة باسم MedAgentBench، وهي مصممة لتقييم أداء نماذج اللغات الكبيرة (LLMs) التي تعمل كوكلاء في سياقات الرعاية الصحية. يُعد هذا المعيار نقلة نوعية مقارنةً بمجموعات البيانات السابقة القائمة على الأسئلة والأجوبة، حيث يوفر MedAgentBench بيئة افتراضية لسجلات الصحة الإلكترونية (EHR) يتعين على أنظمة الذكاء الاصطناعي التفاعل فيها، والتخطيط، وتنفيذ مهام سريرية متعددة الخطوات. هذا يعني التحول من اختبار القدرات الاستنتاجية الثابتة إلى تقييم القدرات الوكيلة في تدفقات عمل طبية حية تعتمد على الأدوات. رابط المقال الأصلي
لماذا نحتاج إلى معايير وكيلة في الرعاية الصحية؟
تطورت نماذج اللغات الكبيرة الحديثة لتتجاوز التفاعلات الثابتة القائمة على الدردشة، نحو سلوك وكيل – أي تفسير التعليمات عالية المستوى، واستدعاء واجهات برمجة التطبيقات (APIs)، ودمج بيانات المرضى، وأتمتة العمليات المعقدة. في الطب، يمكن أن يساعد هذا التطور في معالجة نقص الكوادر الطبية، وعبء التوثيق، وعدم الكفاءة الإدارية. في حين توجد معايير وكيلة عامة الغرض (مثل AgentBench، وAgentBoard، وtau-bench)، إلا أن الرعاية الصحية افتقرت إلى معيار موحد يلتقط تعقيد البيانات الطبية، وتوافق FHIR، وسجلات المرضى على المدى الطويل. يُلبي MedAgentBench هذه الفجوة من خلال توفير إطار عمل قابل للتكرار وذو صلة سريرياً.
محتويات MedAgentBench وهيكلية المهام
يتكون MedAgentBench من 300 مهمة موزعة على 10 فئات، صاغها أطباء مرخصون. تتضمن هذه المهام استرجاع معلومات المريض، وتتبع نتائج المختبر، والتوثيق، وطلب الاختبارات، والإحالات، وإدارة الأدوية. تتطلب المهام في المتوسط خطوتين إلى ثلاث خطوات، وتعكس تدفقات العمل التي تُصادف في الرعاية الصحية للمرضى الداخليين والخارجيين.
بيانات المرضى التي تدعم المعيار
يعتمد المعيار على 100 ملفًا واقعيًا للمرضى مستخرجة من مستودع بيانات STARR في جامعة ستانفورد، والذي يتضمن أكثر من 700,000 سجل، بما في ذلك نتائج المختبرات، والعلامات الحيوية، والتشخيصات، والإجراءات، وطلبات الأدوية. تم إلغاء تحديد هوية البيانات وتشويهها للحفاظ على الخصوصية مع الحفاظ على صحتها السريرية.
كيفية بناء البيئة
تتوافق البيئة مع معيار FHIR، وتدعم كل من استرجاع (GET) وتعديل (POST) بيانات EHR. يمكن لأنظمة الذكاء الاصطناعي محاكاة التفاعلات السريرية الواقعية، مثل توثيق العلامات الحيوية أو وضع طلبات للأدوية. يجعل هذا التصميم المعيار قابلاً للتطبيق مباشرة على أنظمة EHR الحية.
كيفية تقييم النماذج
- المقياس: معدل نجاح المهمة (SR)، يقاس بـ pass@1 الصارم ليعكس متطلبات السلامة في العالم الحقيقي.
- النماذج التي خضعت للاختبار: 12 من أفضل نماذج اللغات الكبيرة، بما في ذلك GPT-4o، وClaude 3.5 Sonnet، وGemini 2.0، وDeepSeek-V3، وQwen2.5، وLlama 3.3.
- منسق الوكيل: إعداد تنسيق أساسي مع تسع وظائف FHIR، يقتصر على ثماني جولات تفاعل لكل مهمة.
أفضل النماذج أداءً
- Claude 3.5 Sonnet v2: أفضل أداء عام بنسبة نجاح 69.67٪، خاصةً في مهام الاسترجاع (85.33٪).
- GPT-4o: نسبة نجاح 64.0٪، مع أداء متوازن في الاسترجاع والعمل.
- DeepSeek-V3: نسبة نجاح 62.67٪، متصدرًا بين النماذج المفتوحة الوزن.
ملاحظة: تفوقت معظم النماذج في مهام الاستعلام، لكنها واجهت صعوبة في المهام القائمة على العمل التي تتطلب تنفيذًا متعدد الخطوات آمنًا.
الأخطاء التي ارتكبتها النماذج
ظهر نمطان رئيسيان للفشل:
- فشل في الالتزام بالتعليمات: مكالمات API غير صالحة أو تنسيق JSON غير صحيح.
- عدم تطابق المخرجات: تقديم جمل كاملة عندما كانت هناك حاجة إلى قيم رقمية منظمة.
تُبرز هذه الأخطاء الثغرات في الدقة والموثوقية، وكلاهما أمر بالغ الأهمية في النشر السريري.
الخلاصة
يُعد MedAgentBench أول معيار واسع النطاق لتقييم وكلاء نماذج اللغات الكبيرة في إعدادات EHR الواقعية، حيث يقترن 300 مهمة صاغها أطباء ببيئة متوافقة مع FHIR و 100 ملفًا لبيانات المرضى. تُظهر النتائج إمكانات قوية ولكن موثوقية محدودة – حيث يتصدر Claude 3.5 Sonnet v2 بنسبة 69.67٪ – مما يُبرز الفجوة بين نجاح الاستعلام وتنفيذ العمل الآمن. على الرغم من قيود البيانات من مؤسسة واحدة ونطاق EHR، إلا أن MedAgentBench يوفر إطار عمل مفتوح وقابل للتكرار لدفع الجيل التالي من وكلاء الذكاء الاصطناعي الموثوقين في الرعاية الصحية.
رابط الورقة البحثية [رابط مدونة التقنية] [رابط صفحة GitHub] [رابط تويتر] [رابط ريديت] [رابط النشرة البريدية]






اترك تعليقاً