DeepSeek R1T2 Chimera: ثورة سرعة وذكاء في نماذج اللغات الكبيرة
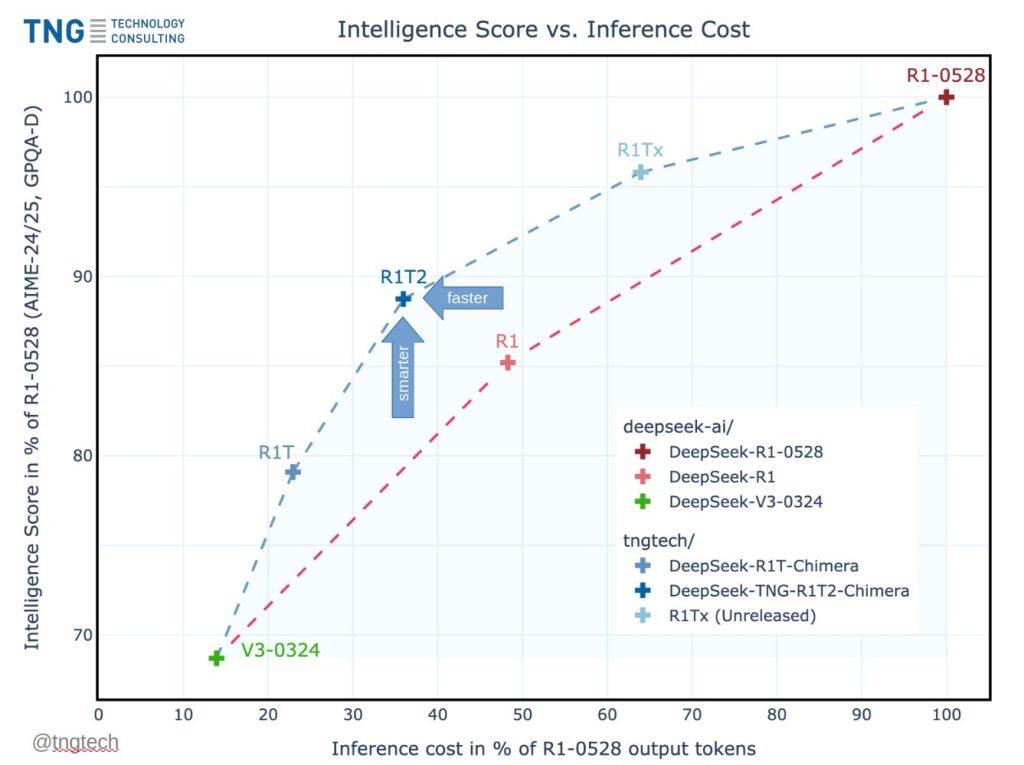
أعلنت شركة TNG Technology Consulting عن إطلاق نموذج DeepSeek-TNG R1T2 Chimera، وهو نموذج جديد قائم على تجميع الخبراء (AoE) يجمع بين الذكاء والسرعة من خلال استراتيجية مبتكرة لدمج النماذج. بناءً على ثلاثة نماذج رئيسية عالية الأداء – R1-0528 و R1 و V3-0324 – يُظهر R1T2 كيف يمكن للقياس البيني للطبقات الخبيرة على نطاق واسع أن يُحدث كفاءات جديدة في نماذج اللغات الكبيرة (LLMs).
تجميع الخبراء: تركيب نماذج فعال على نطاق واسع
يتطلب تدريب نماذج اللغات الكبيرة وضبطها الدقيق موارد حاسوبية ضخمة. تُعالج TNG هذه المشكلة من خلال نهج تجميع الخبراء (AoE)، حيث تقوم بدمج نماذج خليط الخبراء (MoE) واسعة النطاق على مستوى مُوتر الأوزان دون الحاجة لإعادة التدريب. تُمكن هذه الاستراتيجية من إنشاء نماذج جديدة في وقت خطي، حيث ترث قدراتها من عدة نماذج أصلية. تجمع بنية R1T2 بين مُوترات الخبراء من R1 وقاعدة V3-0324، وتُدرج بشكل انتقائي التحسينات من R1-0528، مما يُحسّن التوازن بين تكلفة الاستنتاج وجودة الاستدلال.
مكاسب السرعة والتوازن بين الذكاء والسرعة
في مقاييس الأداء، يُعد R1T2 أسرع بنسبة تزيد عن 20% من R1، وأسرع بأكثر من الضعف من R1-0528. تعزى هذه المكاسب في الأداء إلى حد كبير إلى طول رمز الإخراج المُختصر ودمج مُوترات الخبراء الانتقائي. بينما يقل أداءه قليلاً عن R1-0528 من حيث الذكاء الخام، إلا أنه يتفوق بشكل كبير على R1 عبر معايير الأداء عالية المستوى مثل GPQA Diamond و AIME-2024/2025. علاوة على ذلك، يحتفظ النموذج بـ … مسارات استدلال، والتي تظهر فقط عندما يتجاوز مساهمة R1 في الدمج عتبة محددة. يُعد هذا الاتساق السلوكي أمرًا حيويًا للتطبيقات التي تتطلب استدلالًا خطوة بخطوة.
خصائص ناشئة في فضاء المعلمات
يُؤكد R1T2 النتائج الواردة في الورقة البحثية المصاحبة على أن دمج النماذج يمكن أن يُنتج نماذج قابلة للتطبيق في جميع أنحاء فضاء القياس البيني. ومن المثير للاهتمام، أن خصائص الذكاء تتغير تدريجيًا، ولكن العلامات السلوكية (مثل الاستخدام المُتناسق لـ …) تظهر بشكل مفاجئ بالقرب من نسبة وزن R1 بنسبة 50%. هذا يشير إلى أن بعض السمات موجودة في مسافات فرعية مُتميزة من مشهد أوزان LLM. من خلال دمج مُوترات الخبراء المُوجهة فقط وترك المكونات الأخرى (مثل الانتباه وشبكات MLP المُشتركة) من V3-0324 كما هي، يُحافظ R1T2 على درجة استدلال عالية مع تجنب الإطناب. يؤدي هذا التصميم إلى ما تُسميه TNG “اتساق التفكير-الرمز”، وهي سمة سلوكية حيث يكون الاستدلال دقيقًا ومُختصرًا.
ردود فعل مجتمع Reddit
تُبرز المناقشات المبكرة من مجتمع Reddit LocalLLaMA الانطباعات العملية لـ R1T2. يُثني المستخدمون على استجابة النموذج، وكفاءة الرموز، والتوازن بين السرعة والاتساق. لاحظ أحد المستخدمين، “إنها المرة الأولى التي يبدو فيها نموذج Chimera بمثابة ترقية حقيقية من حيث السرعة والجودة.” وأشار آخر إلى أنه يؤدي بشكل أفضل في السياقات الغنية بالرياضيات مقارنةً بالمتغيرات السابقة من R1. لاحظ بعض مستخدمي Reddit أيضًا أن R1T2 يُظهر شخصية أكثر أرضية، متجنبًا الهلوسة بشكل أكثر اتساقًا من نماذج R1 أو V3. تُعد هذه السمات الناشئة ذات صلة خاصة للمطورين الذين يبحثون عن خوادم خلفية LLM مستقرة لبيئات الإنتاج.
الأوزان المفتوحة والتوافر
يتوفر R1T2 للجمهور بموجب ترخيص MIT على Hugging Face: DeepSeek-TNG R1T2 Chimera. يُشجع الإصدار على التجارب المجتمعية، بما في ذلك ضبط الدقة التابع والتعلم المعزز. وفقًا لـ TNG، تقوم عمليات النشر الداخلية عبر نظام الاستنتاج الخادم الخالي من Chutes بمعالجة ما يقرب من 5 مليارات رمز يوميًا.
الخلاصة
يُظهر DeepSeek-TNG R1T2 Chimera إمكانات بناء تجميع الخبراء في إنشاء نماذج LLMs عالية الأداء وفعالة دون الحاجة إلى تدريب قائم على التدرج. من خلال الجمع الاستراتيجي لقدرات الاستدلال من R1، وتصميم V3-0324 الكفؤ للرموز، والتحسينات من R1-0528، يُنشئ R1T2 معيارًا جديدًا لتصميم النماذج المتوازن. يضمن إصداره ذو الأوزان المفتوحة بموجب ترخيص MIT سهولة الوصول، مما يجعله مرشحًا قويًا للمطورين الذين يبحثون عن نماذج لغات كبيرة سريعة وقادرة وقابلة للتخصيص. مع إثبات جدوى دمج النماذج حتى على مقياس 671 مليار معلمة، قد يُمثل R1T2 من TNG نموذجًا أوليًا للتجارب المستقبلية في قياس مساحة المعلمات، مما يُمكن تطوير نماذج LLMs أكثر وحدة وقابلية للتفسير. اطلع على الورقة البحثية والأوزان المفتوحة على Hugging Face. جميع حقوق هذه الدراسة تخص الباحثين في هذا المشروع. تابعونا أيضًا على Twitter، ولا تنسى الانضمام إلى مجتمعنا ML SubReddit الذي يضم أكثر من 100 ألف مشترك والاشتراك في قائمتنا البريدية.
مواضيع مشابهة:
 DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
 بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena
بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena



اترك تعليقاً