DeepConf: ثورة جديدة في استنتاج نماذج اللغة الكبيرة
تُعَدّ نماذج اللغة الكبيرة (LLMs) نقلة نوعية في مجال الاستنتاج الاصطناعي، حيث ساهمت تقنيات التفكير الموازي والاتساق الذاتي في تحقيق تقدم ملحوظ. ومع ذلك، تواجه هذه التقنيات تنازلاً أساسياً: فزيادة عدد مسارات الاستنتاج يُحسّن الدقة، لكن على حساب تكلفة حسابية باهظة. يُقدّم فريق من الباحثين في Meta AI وجامعة كاليفورنيا في سان دييغو (UCSD) نهجاً جديداً يُسمّى “DeepConf” (التفكير العميق بثقة)، والذي يُقلّل هذا التنازل بشكل كبير.
DeepConf: كفاءة عالية ودقة متقدمة
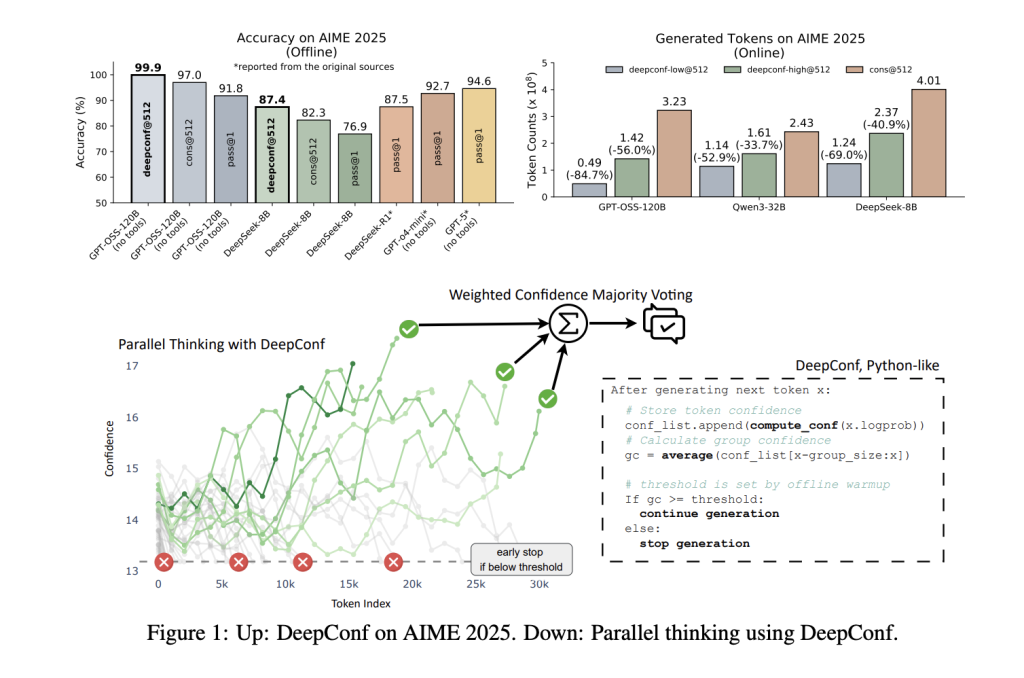
يُحقق DeepConf أداءً متقدماً في مجال الاستنتاج بكفاءة عالية، حيث حقق مثلاً دقة 99.9% في مسابقة الرياضيات الصعبة AIME 2025 باستخدام النموذج مفتوح المصدر GPT-OSS-120B، مع تقليل عدد الرموز المُولّدة بنسبة تصل إلى 85% مقارنةً بأساليب التفكير الموازي التقليدية.
لماذا DeepConf؟
يُعتبر التفكير الموازي (الاتساق الذاتي مع تصويت الأغلبية) المعيار المُعتمد لتعزيز استنتاج نماذج LLMs: توليد العديد من الحلول المُرشّحة، ثم اختيار الإجابة الأكثر شيوعاً. بينما تُعدّ هذه الطريقة فعّالة، إلا أنّ عوائدها تتناقص – حيث تتوقف الدقة عن الزيادة أو حتى تتناقص مع زيادة عدد المسارات المُستخدَمة، لأنّ مسارات الاستنتاج ذات الجودة المنخفضة قد تُضعِف عملية التصويت. علاوة على ذلك، فإنّ توليد مئات أو آلاف المسارات لكل استعلام مكلف من حيث الوقت والحسابات.
يتصدّى DeepConf لهذه التحديات من خلال استغلال إشارات الثقة الذاتية للنموذج. بدلاً من معاملة جميع مسارات الاستنتاج على قدم المساواة، يقوم DeepConf بتصفية المسارات منخفضة الثقة ديناميكياً – إما أثناء التوليد (أونلاين) أو بعده (أوفلاين) – باستخدام المسارات الأكثر موثوقية فقط لتحديد الإجابة النهائية. هذه الاستراتيجية لا تعتمد على نموذج محدد، ولا تتطلب تدريباً أو ضبطاً لمعلمات، ويمكن دمجها في أي نموذج أو إطار عمل قائم بتغييرات بسيطة في الكود.
آلية عمل DeepConf: الثقة كدليل
يُقدّم DeepConf العديد من التطورات في كيفية قياس واستخدام الثقة:
- ثقة الرمز: لحساب كل رمز مُولّد، يتم حساب متوسط لوغاريتم الاحتمال السلبي لأفضل k مرشح. هذا يُعطينا مقياساً محلياً لليقين.
- ثقة المجموعة: متوسط ثقة الرمز على نافذة متحركة (مثل 2048 رمز)، مما يُوفر إشارة مُسَوّاة ومتوسطة لجودة الاستنتاج.
- ثقة الذيل: التركيز على الجزء الأخير من مسار الاستنتاج، حيث توجد غالباً الإجابة، للكشف عن أي انهيارات متأخرة.
- أقل ثقة في المجموعة: تحديد أقل جزء ثقة في المسار، والذي غالباً ما يُشير إلى انهيار الاستنتاج.
- النسبة المئوية الدنيا للثقة: تسليط الضوء على أسوأ الأجزاء، والتي تُعتبر الأكثر تنبؤاً بالأخطاء.
ثم تُستخدم هذه المقاييس لوزن الأصوات (الأثر ذو الثقة العالية يحسب أكثر) أو لتصفية المسارات (يتم الاحتفاظ فقط بأفضل η% من المسارات الأكثر ثقة). في الوضع الأونلاين، يتوقف DeepConf عن توليد مسار بمجرد انخفاض ثقته عن عتبة مُعيرة ديناميكياً، مما يُقلّل بشكل كبير من الحسابات المُهدرة.
النتائج الرئيسية: الأداء والكفاءة
تم تقييم DeepConf عبر معايير مُتعددة للاستنتاج (AIME 2024/2025، HMMT 2025، BRUMO25، GPQA-Diamond) ونماذج (DeepSeek-8B، Qwen3-8B/32B، GPT-OSS-20B/120B). النتائج مُذهلة:
| النموذج | مجموعة البيانات | دقة Pass@1 | دقة Cons@512 | دقة DeepConf@512 | الرموز المُوفّرة |
|---|---|---|---|---|---|
| GPT-OSS-120B | AIME 2025 | 91.8% | 97.0% | 99.9% | -84.7% |
| DeepSeek-8B | AIME 2024 | 83.0% | 86.7% | 93.3% | -77.9% |
| Qwen3-32B | AIME 2024 | 80.6% | 85.3% | 90.8% | -56.0% |
- زيادة الأداء: عبر النماذج ومجموعات البيانات، يُحسّن DeepConf الدقة بنسبة تصل إلى 10 نقاط مئوية مقارنةً بتصويت الأغلبية القياسي، وغالبًا ما يصل إلى الحد الأقصى للمعيار.
- كفاءة عالية: من خلال إيقاف مسارات منخفضة الثقة مبكراً، يُقلّل DeepConf العدد الإجمالي للرموز المُولّدة بنسبة 43-85%، بدون أي خسارة (وغالباً مع زيادة) في الدقة النهائية.
- سهولة الاستخدام: يعمل DeepConf مع أي نموذج دون الحاجة إلى ضبط دقيق أو بحث عن المعلمات أو إجراء تغييرات على البنية الأساسية.
دمج سهل: كود بسيط، أثر كبير
يُعتبر تنفيذ DeepConf بسيطاً للغاية. بالنسبة لـ vLLM، فإن التغييرات ضئيلة:
- توسيع مُعالج logprobs لتتبع ثقة النافذة المُتحركة.
- إضافة فحص لإيقاف مبكر قبل إصدار كل مُخرجات.
- تمرير عتبات الثقة عبر واجهة برمجة التطبيقات، بدون إعادة تدريب النموذج.
هذا يسمح لأي نقطة نهاية مُتوافقة مع OpenAI بدعم DeepConf بإعداد إضافي واحد، مما يجعل تبنيه في بيئات الإنتاج أمراً سهلاً.
الخاتمة
يمثّل DeepConf من Meta AI قفزة نوعية في استنتاج نماذج LLMs، حيث يوفر كل من الدقة القصوى والكفاءة غير المسبوقة. من خلال الاستفادة من ثقة النموذج الداخلية ديناميكياً، يُحقق DeepConf ما كان سابقاً بعيد المنال بالنسبة للنماذج مفتوحة المصدر: نتائج قريبة من الكمال في مهام الاستنتاج المتقدمة، مع جزء صغير من التكلفة الحسابية.
أسئلة شائعة
س1: كيف يُحسّن DeepConf الدقة والكفاءة مقارنةً بتصويت الأغلبية؟
يُعطي تصفية DeepConf و تصويتها على أساس الثقة الأولوية للمسارات ذات اليقين الأعلى للنموذج، مما يُعزز الدقة بنسبة تصل إلى 10 نقاط مئوية عبر معايير الاستنتاج مقارنةً بتصويت الأغلبية فقط. في الوقت نفسه، يُقلّل إيقاف المسارات منخفضة الثقة مبكراً استخدام الرموز بنسبة تصل إلى 85%، مما يوفر كل من الأداء ومكاسب كفاءة هائلة في عمليات النشر العملية.
س2: هل يمكن استخدام DeepConf مع أي نموذج لغوي أو إطار عمل؟
نعم. DeepConf لا يعتمد على نموذج محدد ويمكن دمجه في أي مجموعة عمل، بما في ذلك النماذج مفتوحة المصدر والتجارية، بدون تعديل أو إعادة تدريب. يتطلب النشر تغييرات طفيفة فقط (~50 سطرًا من الكود لـ vLLM)، باستخدام مخرجات logprob لتحديد الثقة ومعالجة الإيقاف المبكر.
س3: هل يتطلب DeepConf إعادة تدريب أو بيانات خاصة أو ضبطاً معقداً؟
لا. يعمل DeepConf بالكامل في وقت الاستنتاج، ولا يتطلب أي تدريب إضافي للنموذج أو ضبطاً دقيقاً أو بحثاً عن المعلمات. يُستخدم فقط مخرجات logprob المُدمجة ويعمل على الفور مع إعدادات واجهة برمجة التطبيقات القياسية للأطر الرائدة؛ إنه قابل للتطوير، وقوي، وقابل للنشر على أحمال العمل الحقيقية بدون انقطاع.
مواضيع مشابهة:
 DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
 بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena
بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena



اترك تعليقاً