الكاتب: عمر أحمد
-
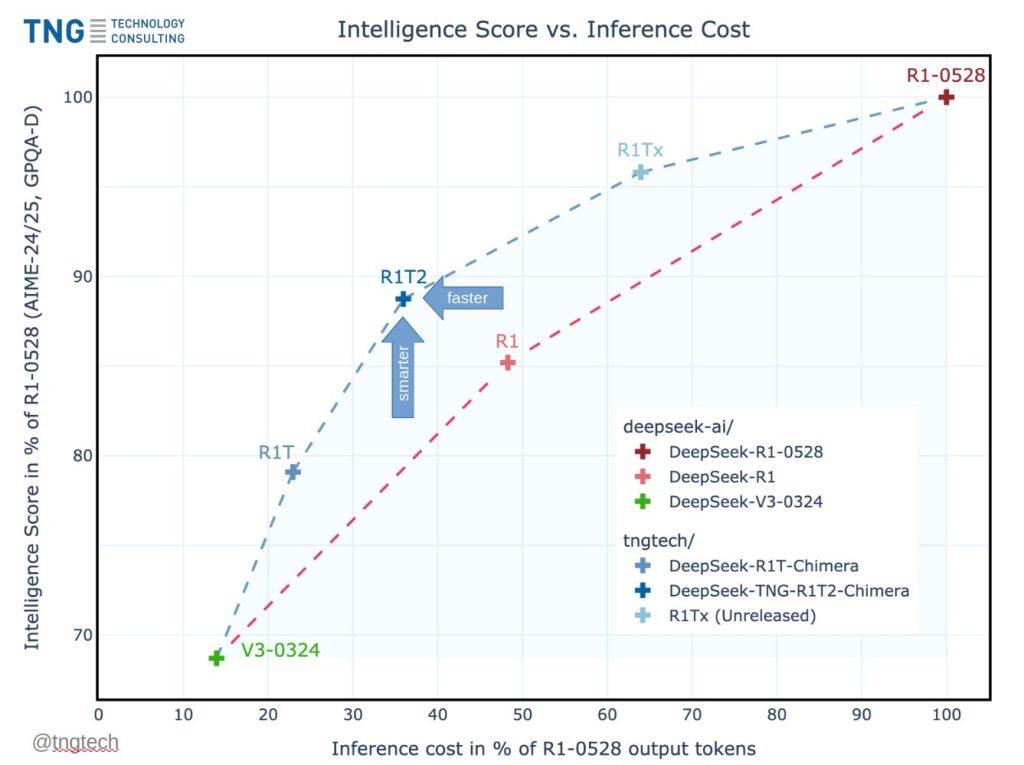
DeepSeek R1T2 Chimera: ثورة سرعة وذكاء في نماذج اللغات الكبيرة
DeepSeek R1T2 Chimera: ثورة سرعة وذكاء في نماذج اللغات الكبيرة أعلنت شركة TNG Technology Consulting عن إطلاق نموذج DeepSeek-TNG R1T2 Chimera، وهو نموذج جديد قائم على تجميع الخبراء (AoE) يجمع بين الذكاء والسرعة من خلال استراتيجية مبتكرة لدمج النماذج. بناءً على ثلاثة نماذج رئيسية عالية… قراءة المزيد
-

DeepSWE: وكيل ترميز مفتوح المصدر مدرب بتقنية التعلم المعزز يحقق نتائج مذهلة
DeepSWE: وكيل ترميز مفتوح المصدر مدرب بتقنية التعلم المعزز يحقق نتائج مذهلة أعلنت شركة Together AI عن إطلاق DeepSWE، وهو وكيل هندسة برمجيات متطور ومفتوح المصدر بالكامل، تم تدريبه باستخدام تقنية التعلم المعزز (Reinforcement Learning – RL). ويعتمد DeepSWE على نموذج اللغة الضخم Qwen3-32B، وقد… قراءة المزيد
-

**تعزيز نماذج اللغات الكبيرة بتقنية التعزيز التعلمي: اقتراح أكتوثينكر من جامعة جياو تونغ في شنغهاي**
تعزيز قدرات نماذج اللغات الكبيرة عبر التعلم المعزز يُظهر التقدم المُحرز في مجال نماذج اللغات الكبيرة (LLMs) قدراتٍ مذهلة في حلّ المسائل المعقدة، لا سيما من خلال استخدام تقنية “سلسلة الأفكار” (CoT) بالتحسين عبر تقنية التعلم المعزّز (RL). وقد برهنت نماذج مثل Deepseek-R1-Zero على قدرات… قراءة المزيد
-

نموذج بحث بايدو الجديد: إطار متعدد الوكلاء لبحث معلوماتي أذكى
نموذج بحث بايدو الجديد: إطار متعدد الوكلاء لبحث معلوماتي أذكى يُعَدّ تطوّر محركات البحث المعرفية والتكيّفية ضرورة ملحّة في ظلّ التزايد الهائل في حجم وتعقيد استفسارات المستخدمين، خاصةً تلك التي تتطلّب استنتاجات متعددة الطبقات. لم تعد أنظمة البحث التقليدية، التي تعتمد على مطابقة الكلمات المفتاحية… قراءة المزيد
-

ERNIE 4.5: بايدو تطلق عائلة نماذج لغة ضخمة مفتوحة المصدر
ERNIE 4.5: ثورة في معالجة اللغات الطبيعية أعلنت شركة بايدو الصينية مؤخراً عن إطلاق عائلة نماذج اللغة الضخمة ERNIE 4.5 مفتوحة المصدر، والتي تمثل نقلة نوعية في مجال فهم اللغة، والتفكير، وإنتاج النصوص. وتتضمن هذه العائلة عشرة نماذج مختلفة، تتراوح أحجامها من 0.3 مليار إلى… قراءة المزيد
-
مقاييس أوميغا: اختبار جديد لقدرات الاستدلال الرياضي لدى نماذج اللغات الكبيرة
مقدمة: تعميم الاستدلال الرياضي أظهرت نماذج اللغات الكبيرة واسعة النطاق، مثل DeepSeek-R1، والتي تستخدم الاستدلال المتسلسل الطويل (CoT)، نتائج جيدة في مسائل الرياضيات على مستوى الأولمبياد. ومع ذلك، تعتمد النماذج المدربة من خلال الضبط الدقيق الخاضع للإشراف أو التعلم المعزز على تقنيات محدودة، مثل تكرار… قراءة المزيد
-
بناء سير عمل متطور للذكاء الاصطناعي متعدد الوكلاء باستخدام AutoGen و Semantic Kernel
بناء سير عمل متطور للذكاء الاصطناعي متعدد الوكلاء باستخدام AutoGen و Semantic Kernel يقدم هذا البرنامج التعليمي شرحًا تفصيليًا لكيفية دمج AutoGen و Semantic Kernel بسلاسة مع نموذج Gemini Flash من جوجل. سنبدأ بإعداد فئات GeminiWrapper و SemanticKernelGeminiPlugin لربط القوة التوليدية لـ Gemini مع آلية… قراءة المزيد
-
LongWriter-Zero: إطار تعلم تقوية لتوليد نصوص طويلة للغاية بدون بيانات اصطناعية
LongWriter-Zero: إطارٌ جديدٌ لِتوليد النصوص الطويلة للغاية باستخدام تقنيات تعلم التعزيز دون الحاجة إلى بيانات اصطناعية يُمثّل توليد النصوص الطويلة للغاية، التي تمتد لآلاف الكلمات، تحديًا متزايد الأهمية في العديد من التطبيقات الواقعية، مثل كتابة القصص والقضايا القانونية والمواد التعليمية. ومع ذلك، لا تزال نماذج… قراءة المزيد
-

نماذج الانتشار المُقنّعة المُحسّنة: إطار عمل MDM-Prime
نماذج الانتشار المُقنّعة المُحسّنة: إطار عمل MDM-Prime لإنتاج بيانات أكثر دقة وكفاءة مقدمة: تحديات نماذج الانتشار المُقنّعة (MDMs) تُعدّ نماذج الانتشار المُقنّعة (MDMs) أدوات قوية لتوليد البيانات المنفصلة، مثل النصوص أو التسلسلات الرمزية، من خلال الكشف التدريجي عن الرموز (tokens) بمرور الوقت. في كل خطوة،… قراءة المزيد
-

إطار عمل G-ACT: توجيه تحيز لغات البرمجة في نماذج اللغات الكبيرة
إطار عمل G-ACT: توجيه تحيز لغات البرمجة في نماذج اللغات الكبيرة تُظهر نماذج اللغات الكبيرة (LLMs) تقدماً مذهلاً في معالجة اللغة الطبيعية، مما يُمكّن تطوير أنظمة قادرة على إدارة سير العمل المعقدة. ومع ذلك، لا يزال استخدام هذه النماذج في توليد الشيفرات العلمية مجالاً غير… قراءة المزيد