الكاتب: عمر أحمد
-

هندسة السياق في نماذج اللغات الكبيرة: خارطة طريق تقنية
هندسة السياق في نماذج اللغات الكبيرة: خارطة طريق تقنية تُعدّ هندسة السياق مجالاً تقنياً متنامياً، يتجاوز مفهوم هندسة المطالبات (Prompt Engineering) بكثير. فهي تُعنى بتنظيم، وتجميع، وتحسين جميع أشكال السياق المُدخلة إلى نماذج اللغات الكبيرة (LLMs) لتعظيم أدائها في مجالات الفهم، والتفكير، والتكيف، والتطبيقات الواقعية.… قراءة المزيد
-
The Ultimate Guide to CPUs, GPUs, NPUs, and TPUs for AI/ML: Performance, Use Cases, and Key Differences
دليل شامل لوحدات معالجة البيانات للذكاء الاصطناعي وتعلّم الآلة: المعالجات المركزية، ووحدات معالجة الرسوميات، ووحدات معالجة الشبكات العصبية، ووحدات معالجة المصفوفات دليل شامل لوحدات معالجة البيانات للذكاء الاصطناعي وتعلّم الآلة: المعالجات المركزية، ووحدات معالجة الرسوميات، ووحدات معالجة الشبكات العصبية، ووحدات معالجة المصفوفات تُعتبر أعباء العمل… قراءة المزيد
-
إنشاء نظام متكامل لتتبع الأجسام وتحليلها باستخدام Roboflow Supervision
إنشاء نظام متكامل لتتبع الأجسام وتحليلها باستخدام مكتبة Roboflow Supervision هذا البرنامج التعليمي المتقدم يوضح كيفية بناء خط أنابيب كامل لكشف الأجسام باستخدام مكتبة Roboflow Supervision. سنبدأ بإعداد تتبع الأجسام في الوقت الفعلي باستخدام ByteTracker، وإضافة تنعيم الكشف، وتحديد مناطق مُضلّعة لمراقبة مناطق محددة في… قراءة المزيد
-

إطلاق إطار عمل CUDA-L1: تعزيز أداء معالجات الرسوميات بنسبة تصل إلى 3 أضعاف بفضل تقنيات التعلم المعزز
إطلاق إطار عمل CUDA-L1: تعزيز أداء معالجات الرسوميات بنسبة تصل إلى 3 أضعاف بفضل تقنيات التعلم المعزز أعلن فريق DeepReinforce عن إطار عمل جديد ثوري يُدعى CUDA-L1، والذي يُحقق تسريعًا متوسطًا يصل إلى 3.12 ضعفًا، وذروة تسريع تصل إلى 120 ضعفًا في 250 مهمة عملية… قراءة المزيد
-

وكيل جوجل للذكاء الاصطناعي MLE-STAR: ثورة في هندسة تعلم الآلة
وكيل جوجل للذكاء الاصطناعي MLE-STAR: ثورة في هندسة تعلم الآلة يُمثّل وكيل هندسة تعلم الآلة MLE-STAR (اختصارًا لـ Machine Learning Engineering via Search and Targeted Refinement)، الذي طوره باحثو جوجل كلاود، قفزة نوعية في مجال أتمتة تصميم وتحسين خطوط أنابيب تعلم الآلة المعقدة. باستخدام بحث… قراءة المزيد
-
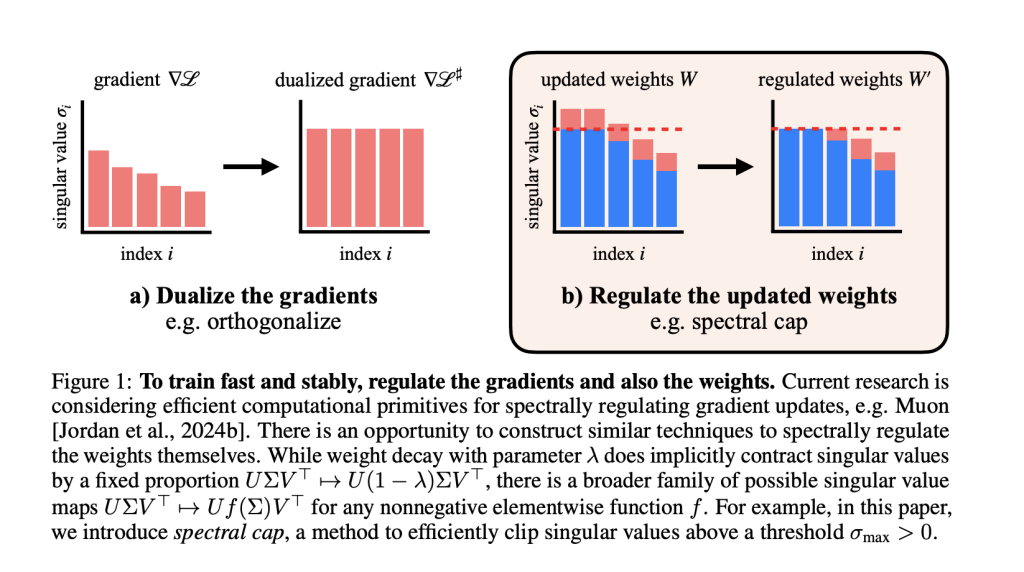
تحكم حساسية المُحوِّلات اللغوية: حدود ليبشيتز قابلة للتثبيت و مُحسّن ميون
تحكم حساسية المُحوِّلات اللغوية: حدود ليبشيتز قابلة للتثبيت و مُحسّن ميون يُشكّل تدريب المُحوِّلات اللغوية واسعة النطاق بشكل مُستقر تحديًا مُستمرًا في مجال التعلّم العميق، خاصةً مع ازدياد حجم النماذج وقدرتها التعبيرية. وقد عالج باحثون من معهد ماساتشوستس للتكنولوجيا (MIT) هذه المشكلة من جذورها، مُتطرقين… قراءة المزيد
-
بناء أنظمة متعددة الوكلاء الذكية باستخدام نموذج PEER: دليل برمجي شامل
بناء أنظمة متعددة الوكلاء الذكية باستخدام نموذج PEER: دليل برمجي شامل هذا البرنامج التعليمي العملي يشرح كيفية بناء نظام متعدد الوكلاء قوي يعتمد على نموذج PEER (التخطيط، التنفيذ، التعبير، المراجعة) باستخدام Google Colab/Notebook. سنقوم بدمج وكلاء متخصصين في أدوار مختلفة، مستفيدين من نموذج جيميني 1.5… قراءة المزيد
-
Trackio: مكتبة بايثون مفتوحة المصدر لتتبع التجارب في تعلم الآلة
Trackio: مكتبة بايثون مفتوحة المصدر لتتبع التجارب في تعلم الآلة تُعدّ عملية تتبع التجارب عنصرًا أساسيًا في تدفقات عمل تعلم الآلة الحديثة. سواء كنت تُعدّل المعلمات التشغيلية، أو تُراقب مقاييس التدريب، أو تتعاون مع الزملاء، فمن الضروري وجود أدوات قوية ومرنة تجعل تتبع التجارب بسيطًا… قراءة المزيد
-
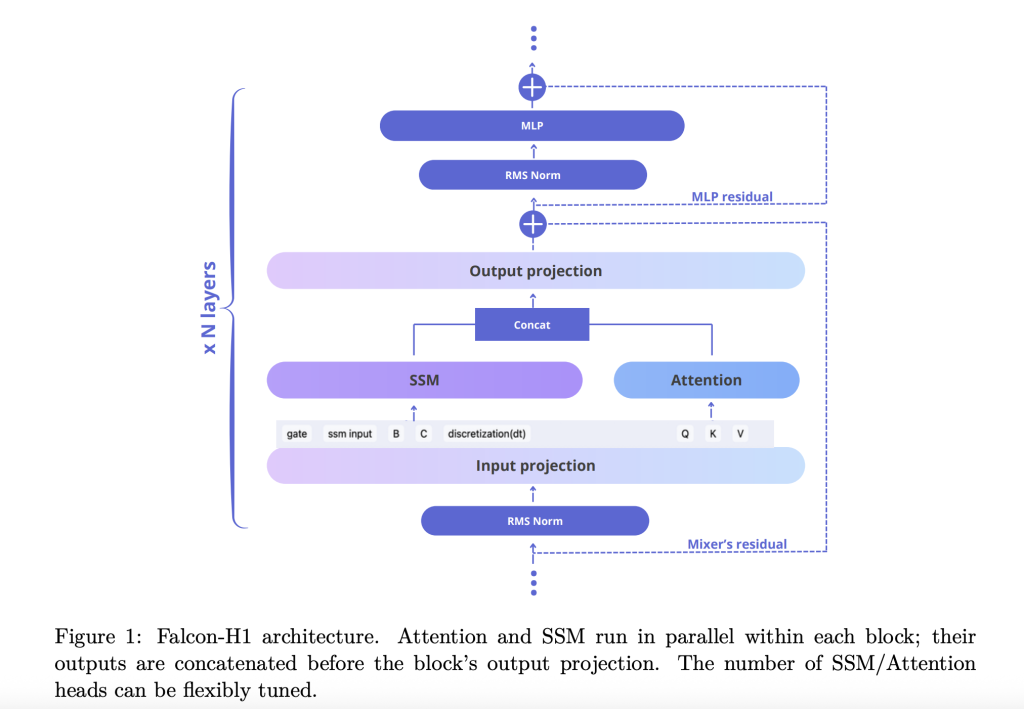
نموذج فالكون-H1: تقرير تقني يكشف عن نموذج هجين متفوق
نموذج فالكون-H1: تقرير تقني يكشف عن نموذج هجين متفوق يتنافس مع نماذج اللغات الضخمة 70B يُمثّل نموذج فالكون-H1، الذي طوره معهد الابتكار التكنولوجي (TII)، إنجازًا بارزًا في تطور نماذج اللغات الضخمة (LLMs). بدمج آلية الانتباه القائمة على مُحوّل ترانسفورمر مع نماذج فضاء الحالة (SSMs) القائمة… قراءة المزيد
-
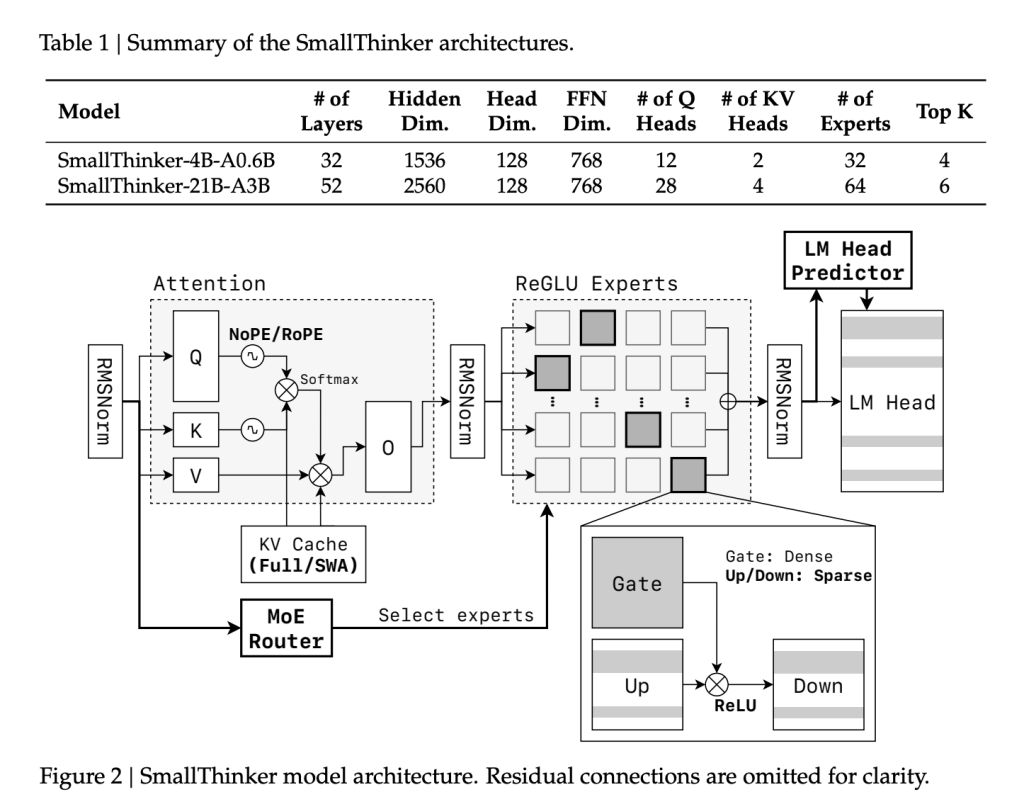
نماذج SmallThinker اللغوية: ثورة في الذكاء الاصطناعي المحلي
نماذج SmallThinker اللغوية: ثورة في الذكاء الاصطناعي المحلي يُهيمن على مشهد أنظمة الذكاء الاصطناعي التوليدي حاليًا نماذج اللغات الضخمة، المصممة غالبًا للعمل على سعة مراكز البيانات السحابية الهائلة. وبالرغم من قوة هذه النماذج، إلا أنها تُعيق أو تُحيل دون تمكين المستخدمين العاديين من نشر أنظمة… قراءة المزيد