
نماذج كُوين 3 القادمة: إصدارات FP8 لمعالجة النصوص بفعالية عالية
أعلن فريق كُوين التابع لشركة علي بابا عن إصدار نقاط تفتيش مُكمّاة بـ FP8 لنماذجه الجديدة Qwen3-Next-80B-A3B، وذلك في نسختين: “إرشادية” (Instruct) و “تفكيرية” (Thinking). يهدف هذا الإصدار إلى تحقيق استنتاج عالي الإنتاجية مع سياق نصي طويل جدًا وكفاءة عالية في آلية خلط الخبراء (MoE).
بنية النموذج Qwen3-Next-80B-A3B
يُعدّ Qwen3-Next-80B-A3B نموذجًا هجينًا يجمع بين شبكة دلتا ذات البوابات (Gated DeltaNet) – وهي بديل لآلية الاهتمام الخطية/التقلبية – وآلية الاهتمام ذات البوابات (Gated Attention)، بالتناوب مع آلية خلط الخبراء (MoE) فائقة التفرّع. يُفعّل هذا النموذج ذو 80 مليار معامل حوالي 3 مليارات معامل لكل رمز (Token) عبر 512 خبيرًا (10 مُوجّهة + 1 مُشتركة).
تتكون بنية النموذج من 48 طبقة مُرتّبة في 12 كتلة: 3 × (Gated DeltaNet → MoE) تليها 1 × (Gated Attention → MoE). يبلغ السياق الأصلي للنموذج 262,144 رمزًا، وقد تم التحقق من صحته حتى 1,010,000 رمزًا باستخدام مقياس RoPE (YaRN). يبلغ حجم الإخفاء 2048؛ تستخدم آلية الاهتمام 16 رأسًا للاستعلام (Q) و 2 رأسًا للقيمة والمفتاح (KV) ببعد 256؛ بينما تستخدم شبكة دلتا 32 رأسًا خطيًا للقيمة (V) و 16 رأسًا خطيًا للاستعلام والمفتاح (QK) ببعد 128.
أفاد فريق كُوين أن النموذج الأساسي 80B-A3B يتفوّق على Qwen3-32B في المهام المُتقدّمة بتكلفة تدريب تبلغ حوالي 10% من تكلفة تدريب النموذج الأكبر، كما أنه يقدّم إنتاجية استنتاجية أعلى بحوالي 10 أضعاف من إنتاجية النماذج الأخرى عند سياقات تتجاوز 32 ألف رمز، وذلك بفضل انخفاض التنشيط في آلية MoE والتنبؤ متعدد الرموز (MTP).
نسخة “إرشادية” لا تتضمن الاستدلال (بدون علامات )، بينما نسخة “تفكيرية” تُفرِض تتبع الاستدلال بشكل افتراضي وهي مُحسّنة للمشكلات المعقدة.
إصدارات FP8: التغييرات المُطبّقة
تُشير بطاقات نماذج FP8 إلى أن الكميّة هي “FP8 دقيقة الحبيبات” بحجم كتلة 128. يختلف النشر قليلاً عن BF16: يتطلّب كل من sglang و vLLM الإصدارات الرئيسية/الليليّة الحالية، مع توفير أوامر مثال على سياق 256 كيلوبايت وخيار MTP. كما توصي بطاقة FP8 “التفكيرية” باستخدام علم مُحلّل الاستدلال (مثل: –reasoning-parser deepseek-r1 في sglang، deepseek_r1 في vLLM). تحتفظ هذه الإصدارات برخصة Apache-2.0.
مقاييس الأداء (المُبلغ عنها على أوزان BF16)
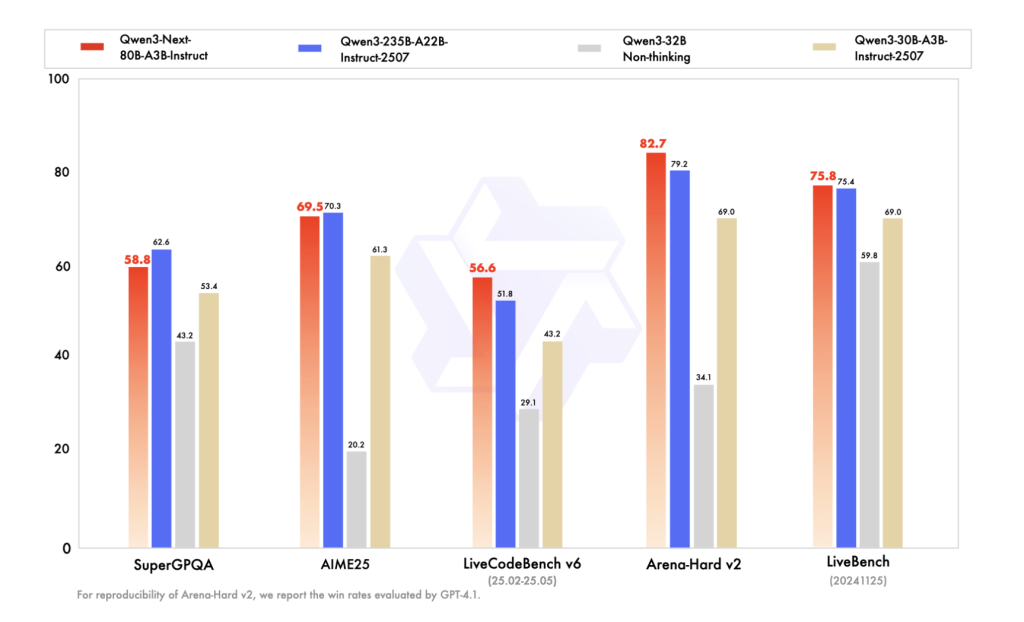
تُعيد بطاقة FP8 “الإرشادية” إنتاج جدول مقارنة BF16 الخاص بـ Qwen، حيث يُضاهي Qwen3-Next-80B-A3B-Instruct نموذج Qwen3-235B-A22B-Instruct-2507 في العديد من معايير المعرفة/الاستدلال/الترميز، ويتفوّق عليه في مهام السياق الطويل (حتى 256 كيلوبايت). تُدرج بطاقة FP8 “التفكيرية” معايير AIME’25، HMMT’25، MMLU-Pro/Redux، و LiveCodeBench v6، حيث يتفوّق Qwen3-Next-80B-A3B-Thinking على إصدارات Qwen3 “التفكيرية” السابقة (30B A3B-2507، 32B) ويدّعي الفوز على Gemini-2.5-Flash-Thinking في العديد من المعايير.
إشارات التدريب والتدريب اللاحق
تم تدريب السلسلة على حوالي 15 تريليون رمز قبل التدريب اللاحق. تُبرز كُوين الإضافات لتحسين الاستقرار (التطبيع الطبقي ذي المركز الصفري، انحلال الوزن، إلخ) وتستخدم GSPO في التدريب المُعزّز المُعزّز للنموذج “التفكيري” للتعامل مع مزيج الاهتمام الهجين و آلية MoE عالية التفرّع. يُستخدم MTP لتسريع الاستنتاج وتحسين إشارة ما قبل التدريب.
أهمية FP8
على المُعجّلات الحديثة، تعمل تنشيطات/أوزان FP8 على تقليل ضغط عرض نطاق الذاكرة والمساحة المُقيمة مقارنةً بـ BF16، مما يسمح بأحجام دفعات أكبر أو تسلسلات أطول بنفس زمن الانتظار تقريبًا. بسبب توجيه آلية A3B لحوالي 3 مليارات معامل لكل رمز فقط، فإن مزيج FP8 + تفرّع MoE يُضاعِف مكاسب الإنتاجية في أنظمة السياق الطويل، خاصةً عند إقرانه مع فك التشفير التنبؤي عبر MTP كما هو موضّح في أعلام الخدمة. ومع ذلك، تتفاعل الكميّة مع أنواع التوجيه والاهتمام؛ وقد تختلف معدلات القبول الفعلية لفك التشفير التنبؤي ودقة المهام النهائية باختلاف محرّك التنفيذ ونواة المعالجة – ومن هنا يأتي توجيه كُوين لاستخدام sglang/vLLM الحاليين وضبط الإعدادات التنبؤية.
ملخص
تُجعل إصدارات FP8 من كُوين من نموذج A3B ذي 80/3 مليار معامل مُفعّل عمليًا لخدمة سياق 256 كيلوبايت على المحرّكات الرئيسية، مع الحفاظ على التصميم الهجين لـ MoE ومسار MTP لتحقيق إنتاجية عالية. تحتفظ بطاقات النموذج بمعايير الأداء من BF16، لذا يجب على الفرق التحقق من دقة FP8 وزمن الانتظار على أنظمتهم الخاصة، خاصةً مع مُحلّلات الاستدلال والإعدادات التنبؤية. النتيجة النهائية: عرض نطاق ذاكرة أقل وتزامن مُحسّن دون انحدار معماري، مُصمّم لعمليات الإنتاج ذات السياق الطويل.






اترك تعليقاً