
مجموعة أدوات AU-Harness مفتوحة المصدر: ثورة في تقييم نماذج معالجة اللغة الصوتية الضخمة
يشهد مجال الذكاء الاصطناعي الصوتي تقدماً متسارعاً، حيث أصبحت القدرة على فهم ومعالجة الصوت أحد أهم الجوانب في تطوير أنظمة الذكاء الاصطناعي متعددة الوسائط. من المساعدين الافتراضيين إلى الوكلاء التفاعليين، تُغيّر هذه القدرة طريقة تفاعل الآلات مع البشر بشكل جذري. ومع ذلك، وعلى الرغم من التقدم السريع في قدرات النماذج اللغوية الصوتية، إلا أن أدوات تقييمها لم تواكب هذا التطور. فمعايير التقييم الحالية مجزأة، وبطيئة، وتركز على جوانب محددة، مما يُصعب مقارنة النماذج أو اختبارها في سيناريوهات واقعية متعددة الأدوار.
لماذا نحتاج إلى إطار عمل جديد لتقييم الصوت؟
للتغلب على هذه التحديات، أصدر فريق البحث في جامعة تكساس في أوستن وشركة ServiceNow مجموعة أدوات AU-Harness مفتوحة المصدر، المصممة لتقييم نماذج معالجة اللغة الصوتية الضخمة (LALMs) بكفاءة عالية. تتميز AU-Harness بسرعتها، وتوحيد معاييرها، وقابلية توسيعها، مما يُمكّن الباحثين من اختبار النماذج عبر مجموعة واسعة من المهام – من التعرف على الكلام إلى الاستدلال الصوتي المعقد – ضمن إطار عمل موحد.
تُعاني معايير التقييم الصوتية الحالية من عدة قصور، منها:
- اختناقات في الإنتاجية: لا تستفيد العديد من أدوات التقييم من تقنيات المعالجة المتوازية، مما يجعل عمليات التقييم واسعة النطاق بطيئة للغاية.
- عدم اتساق الطلبات: يُصعب مقارنة نتائج النماذج المختلفة بسبب اختلاف طريقة تقديم الطلبات.
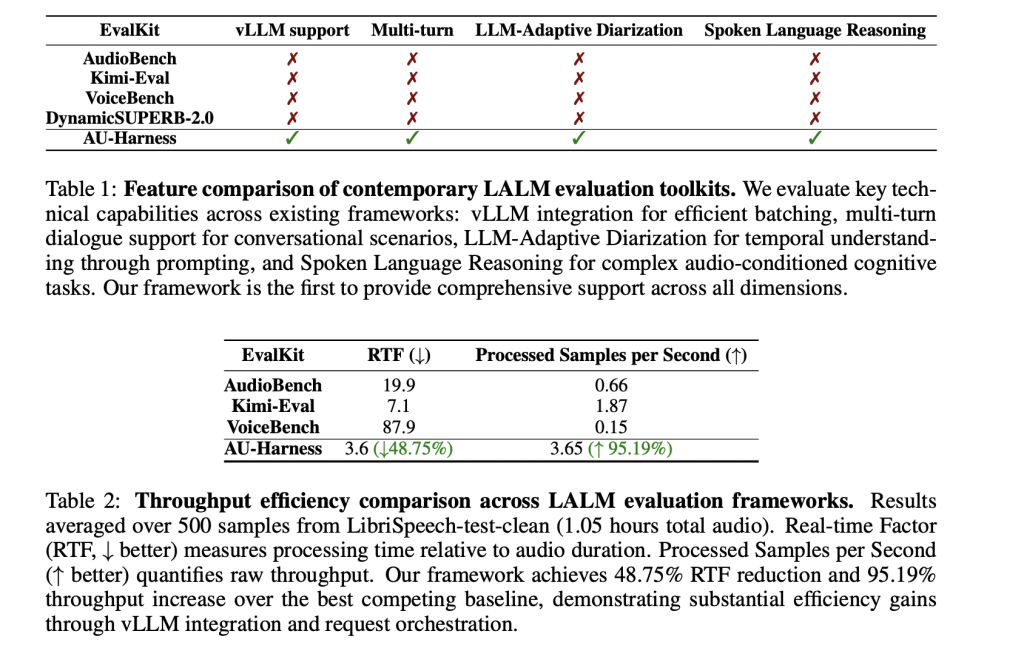
- نطاق المهام المحدود: تفتقر العديد من أدوات التقييم إلى تغطية مجالات مهمة مثل تحديد المتحدثين (من تحدث متى) والاستدلال الصوتي (اتباع التعليمات المُعطاة صوتيًا).
هذه القصور تحد من تقدم نماذج LALMs، خاصةً مع تطورها إلى وكلاء متعددي الوسائط يجب أن يتعاملوا مع تفاعلات طويلة ومعقدة ومتعددة الأدوار.
كيف تُحسّن AU-Harness الكفاءة؟
صُممت AU-Harness مع التركيز على السرعة. من خلال التكامل مع محرك الاستدلال vLLM، تُقدم AU-Harness مُجدول طلبات قائم على الرموز (tokens) يدير عمليات التقييم المتزامنة عبر عقدة حوسبة متعددة. كما تقوم بتقسيم مجموعات البيانات (sharding) لتوزيع أعباء العمل بالتناسب عبر موارد الحوسبة المتاحة. يُتيح هذا التصميم توسيع نطاق عمليات التقييم بشكل خطي تقريبًا، مع الحفاظ على استخدام كامل لقدرات الأجهزة.
في الواقع، تُقدم AU-Harness إنتاجية أعلى بنسبة 127% وتُقلل من عامل الوقت الحقيقي (RTF) بنسبة 60% تقريبًا مقارنةً بمجموعات الأدوات الحالية. هذا يعني أن عمليات التقييم التي كانت تستغرق أيامًا تُصبح الآن مكتملة في ساعات.
هل عمليات التقييم قابلة للتخصيص؟
تُعتبر المرونة من السمات الأساسية لـ AU-Harness. يمكن لكل نموذج في عملية التقييم أن يمتلك معاملاته الفائقة الخاصة، مثل معامل درجة الحرارة أو إعداد الحد الأقصى للرموز، دون المساس بالتوحيد في المعايير. تتيح التكوينات تصفية مجموعات البيانات (مثلًا، حسب اللهجة، أو طول الصوت، أو مستوى الضوضاء)، مما يُمكّن من التشخيص المُستهدف. والأهم من ذلك، تدعم AU-Harness تقييم الحوارات متعددة الأدوار. كانت أدوات التقييم السابقة محدودة بالمهام ذات الدور الواحد، لكن وكلاء الصوت الحديثة تعمل في محادثات ممتدة. مع AU-Harness، يمكن للباحثين قياس استمرارية الحوار، والاستدلال السياقي، وقابلية التكيف عبر التبادلات متعددة الخطوات.
ما هي المهام التي تغطيها AU-Harness؟
تُوسّع AU-Harness تغطية المهام بشكل كبير، حيث تدعم أكثر من 50 مجموعة بيانات، وأكثر من 380 مجموعة فرعية، و21 مهمة عبر ست فئات:
- التعرف على الكلام: من التعرف على الكلام البسيط إلى الكلام طويل الأمد والتحويل بين اللهجات.
- الخصائص الصوتية: التعرف على المشاعر، واللهجات، والجنس، والمتحدثين.
- فهم الصوت: فهم المشاهد والموسيقى.
- فهم اللغة المنطوقة: الإجابة على الأسئلة، والترجمة، وتلخيص الحوارات.
- الاستدلال باللغة المنطوقة: تحويل الكلام إلى أكواد، واستدعاء الوظائف، واتباع التعليمات متعددة الخطوات.
- السلامة والأمن: تقييم المتانة والكشف عن عمليات التزييف.
من أبرز الابتكارات في AU-Harness:
- تحديد المتحدثين القابل للتكيّف مع نماذج اللغة الضخمة: يقيم تحديد المتحدثين من خلال الطلبات بدلاً من النماذج العصبية المتخصصة.
- الاستدلال باللغة المنطوقة: يختبر قدرة النماذج على معالجة وفهم التعليمات المنطوقة، وليس مجرد نسخها.
ما الذي تكشفه معايير التقييم عن نماذج اليوم؟
عند تطبيق AU-Harness على أنظمة رائدة مثل GPT-4o، وQwen2.5-Omni، وVoxtral-Mini-3B، تُبرز النتائج نقاط القوة والضعف في هذه النماذج. تتفوق النماذج في مهام التعرف على الكلام والإجابة على الأسئلة، مُظهرة دقة عالية في التعرف على الكلام ومهام الأسئلة والأجوبة المنطوقة. لكنها تتأخر في مهام الاستدلال الزمني، مثل تحديد المتحدثين، وفي اتباع التعليمات المعقدة، خاصةً عندما تُعطى التعليمات بشكل صوتي.
من أهم النتائج التي توصلت إليها الدراسة هو الفجوة في طريقة تقديم التعليمات: عندما تُقدم المهام نفسها كتّعليمات منطوقة بدلاً من نصوص مكتوبة، ينخفض الأداء بنسبة تصل إلى 9.5 نقطة. يُشير هذا إلى أن النماذج ماهرة في معالجة الاستدلال القائم على النصوص، لكن تكييف هذه المهارات مع الوسائط الصوتية لا يزال يمثل تحديًا مفتوحًا.
الخلاصة
تمثل AU-Harness خطوة مهمة نحو تقييم موحد وقابل للتوسيع لنماذج معالجة اللغة الصوتية. من خلال الجمع بين الكفاءة، وإمكانية التكرار، وتغطية واسعة للمهام – بما في ذلك تحديد المتحدثين والاستدلال الصوتي – تعالج AU-Harness الثغرات طويلة الأمد في معايير تقييم أنظمة الذكاء الاصطناعي الصوتية. يُشجع إصدارها مفتوح المصدر واللوحة الرائدة العامة المجتمع على التعاون والمقارنة ودفع حدود ما يمكن لأنظمة الذكاء الاصطناعي الصوتية تحقيقه. يمكنكم الاطلاع على الورقة البحثية، والمشروع، وصفحة GitHub.
مواضيع مشابهة:
 دليل برمجي خطوة بخطوة لدمج أدوات البحث والتوصية في الوقت الحقيقي من Dappier AI مع واجهة برمجة تطبيقات دردشة OpenAI
من إليزا إلى نمذجة المحادثة: تطور أنظمة وباراديغمات الذكاء الاصطناعي المحادثي
دليل برمجي خطوة بخطوة لدمج أدوات البحث والتوصية في الوقت الحقيقي من Dappier AI مع واجهة برمجة تطبيقات دردشة OpenAI
من إليزا إلى نمذجة المحادثة: تطور أنظمة وباراديغمات الذكاء الاصطناعي المحادثي
 أداة Llama Prompt Ops: تحسين استجابات نماذج Llama بسهولة
أداة Llama Prompt Ops: تحسين استجابات نماذج Llama بسهولة
 هل يمكن الكشف الآلي عن الهلوسة في نماذج اللغات الكبيرة؟ دراسة نظرية وتطبيقية
هل يمكن الكشف الآلي عن الهلوسة في نماذج اللغات الكبيرة؟ دراسة نظرية وتطبيقية



اترك تعليقاً