
mmBERT: ثورة في معالجة اللغات الطبيعية متعددة اللغات
يُمثل نموذج mmBERT تقدماً هائلاً في مجال معالجة اللغات الطبيعية متعددة اللغات، حيث يُقدّم بديلاً متطوراً لنموذج XLM-R الذي هيمن على هذا المجال لسنوات طويلة. يتميز mmBERT بسرعته الفائقة وكفاءته العالية وقدرته على معالجة كم هائل من اللغات.
لماذا نحتاج إلى مُشفّر لغوي متعدد اللغات جديد؟
سيطر نموذج XLM-RoBERTa (XLM-R) على مجال معالجة اللغات الطبيعية متعددة اللغات لأكثر من خمس سنوات، وهي فترة طويلة بشكل غير عادي في أبحاث الذكاء الاصطناعي. بينما كانت النماذج المُشفّرة فقط مثل BERT وRoBERTa أساسية في التقدم المبكر، تحوّل معظم الجهد البحثي نحو النماذج التوليدية القائمة على فك التشفير. ومع ذلك، تظل المُشفّرات أكثر كفاءة، وكثيراً ما تتفوق على فكّات التشفير في مهام تضمين النصوص، والاسترجاع، والتصنيف. على الرغم من ذلك، توقف تطوير المُشفرات متعددة اللغات. يُقدّم فريق من الباحثين من جامعة جونز هوبكنز نموذج mmBERT الذي يعالج هذه الفجوة من خلال تقديم مُشفّر حديث، يتفوق على XLM-R، ويتنافس مع النماذج واسعة النطاق الحديثة مثل o3 من OpenAI وGemini 2.5 Pro من Google.
بنية mmBERT
يتوفر mmBERT في نسختين رئيسيتين:
- النموذج الأساسي: 22 طبقة من مُحوّل الترانسفورمر، وبُعد مخفي 1152، وعدد المعلمات حوالي 307 مليون (110 مليون معلمة غير مُدمجة).
- النموذج الصغير: حوالي 140 مليون معلمة (42 مليون معلمة غير مُدمجة).
يعتمد mmBERT مُعالج Gemma 2 مع قاموس مفردات يتكون من 256 ألف مُدخل، وتركييبات المواضع الدورانية (RoPE)، وFlashAttention2 لتحقيق الكفاءة. تمتد طول التسلسل من 1024 إلى 8192 رمزاً، باستخدام التضمينات غير المُبطنة وانتباه النافذة المنزلقة. يسمح هذا لـ mmBERT بمعالجة سياقات أطول بعشر مرات تقريباً من XLM-R مع الحفاظ على استنتاج أسرع.
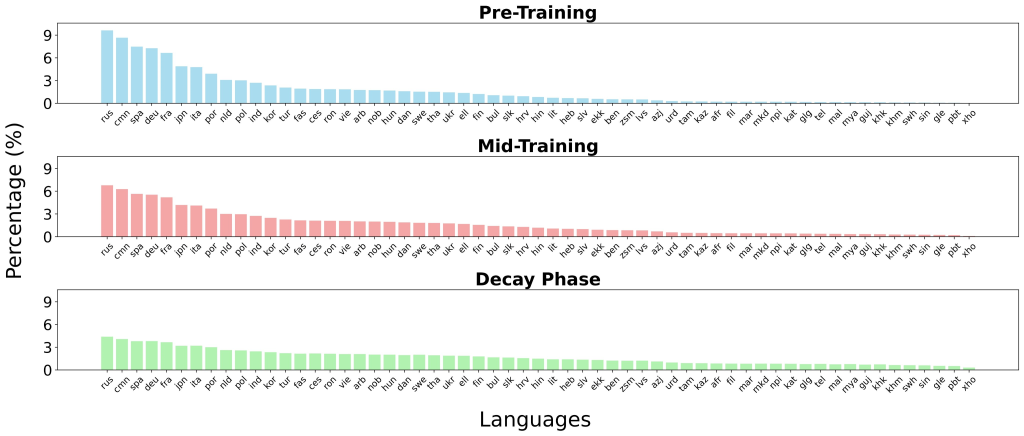
بيانات التدريب ومراحله
تم تدريب mmBERT على 3 تريليون رمز تغطي 1833 لغة. تشمل مصادر البيانات FineWeb2، وDolma، وMegaWika v2، وProLong، وStarCoder، وغيرها. لا تشكل اللغة الإنجليزية سوى حوالي 10-34% من النصوص حسب المرحلة. تم التدريب على ثلاث مراحل:
- مرحلة ما قبل التدريب: 2.3 تريليون رمز عبر 60 لغة وكود.
- مرحلة التدريب المتوسط: 600 مليار رمز عبر 110 لغة، مع التركيز على المصادر عالية الجودة.
- مرحلة الانحدار: 100 مليار رمز تغطي 1833 لغة، مع التركيز على التكيّف مع اللغات ذات الموارد المحدودة.
استراتيجيات التدريب الجديدة
تُعزى أداء mmBERT المتميز إلى ثلاثة ابتكارات رئيسية:
- التعلم اللغوي المُخمد (ALL): يتم تقديم اللغات تدريجياً (60 → 110 → 1833). يتم تخفيف توزيعات أخذ العينات من اللغات عالية الموارد إلى توزيع موحد، مما يضمن حصول اللغات ذات الموارد المحدودة على تأثير خلال المراحل اللاحقة دون الإفراط في التكيّف مع البيانات المحدودة.
- جدول الإخفاء العكسي: يبدأ معدل الإخفاء عند 30% وينخفض إلى 5%، مما يشجع على التعلم الخشن في البداية والتحسينات الدقيقة لاحقاً.
- دمج النماذج عبر متغيرات الانحدار: يتم دمج نماذج متعددة من مرحلة الانحدار (غنية باللغة الإنجليزية، و110 لغة، و1833 لغة) عبر دمج TIES، والاستفادة من نقاط القوة التكميلية دون إعادة التدريب من الصفر.
أداء mmBERT في المعايير المرجعية
- فهم اللغة الطبيعية باللغة الإنجليزية (GLUE): حقق mmBERT الأساسي درجة 86.3، متجاوزاً XLM-R (83.3) ومقارباً ModernBERT (87.4)، على الرغم من تخصيص أكثر من 75% من التدريب للبيانات غير الإنجليزية.
- فهم اللغة الطبيعية متعدد اللغات (XTREME): سجل mmBERT الأساسي 72.8 مقابل 70.4 لـ XLM-R، مع مكاسب في مهام التصنيف والأسئلة والأجوبة.
- مهام التضمين (MTEB v2): تعادل mmBERT الأساسي ModernBERT باللغة الإنجليزية (53.9 مقابل 53.8) ويتصدر في اللغات المتعددة (54.1 مقابل 52.4 لـ XLM-R).
- استرجاع التعليمات البرمجية (CoIR): يتفوق mmBERT على XLM-R بنحو 9 نقاط، على الرغم من أن EuroBERT لا يزال أقوى على البيانات الخاصة.
التعامل مع اللغات ذات الموارد المحدودة
يضمن جدول التعلم المُخمد أن تستفيد اللغات ذات الموارد المحدودة خلال مراحل التدريب اللاحقة. في المعايير المرجعية مثل Faroese FoQA وTigrinya TiQuAD، يتفوق mmBERT بشكل ملحوظ على كل من o3 وGemini 2.5 Pro. تُظهر هذه النتائج أن نماذج المُشفرات، إذا تم تدريبها بعناية، يمكن أن تُعمّم بشكل فعال حتى في سيناريوهات الموارد المحدودة للغاية.
مكاسب الكفاءة
mmBERT أسرع من XLM-R وMiniLM بمقدار 2-4 أضعاف مع دعم مدخلات 8192 رمزاً. والجدير بالذكر أنه يبقى أسرع عند 8192 رمزاً مما كانت عليه المُشفرات القديمة عند 512 رمزاً. ينبع هذا التحسين في السرعة من وصفة تدريب ModernBERT، وآليات الانتباه الفعالة، والتضمينات المُحسّنة.
الخلاصة
يُمثل mmBERT البديل المُنتظر طويلاً لـ XLM-R، ويعيد تعريف إمكانيات المُشفّر متعدد اللغات. يعمل بسرعة تفوق XLM-R بمقدار 2-4 أضعاف، ويتعامل مع تسلسلات يصل طولها إلى 8000 رمز، ويتفوق على النماذج السابقة في كل من المعايير المرجعية عالية الموارد واللغات ذات الموارد المحدودة التي لم تحظَ بالاهتمام الكافي في الماضي. تُظهر وصفة تدريبه – 3 تريليون رمز مقترنة بالتعلم اللغوي المُخمد، والإخفاء العكسي، ودمج النماذج – كيف يمكن للتصميم الدقيق أن يُطلق العنان للتعميم الواسع بدون تكرار مفرط. والنتيجة هي مُشفّر مفتوح، وكفؤ، وقابل للتطوير، لا يملأ فقط الفجوة التي استمرت ست سنوات منذ XLM-R، بل يُوفر أيضاً أساساً قوياً للجيل القادم من أنظمة معالجة اللغات الطبيعية متعددة اللغات.
مواضيع مشابهة:
 بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه
بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه



اترك تعليقاً