
نموذج ERNIE-4.5-21B-A3B-Thinking: التفكير العميق بكفاءة عالية
أعلنت شركة بايدو عن إطلاق نموذجها اللغوي الكبير الجديد ERNIE-4.5-21B-A3B-Thinking، وهو نموذج مُصمم خصيصًا للتفكير العميق، مع التركيز على الكفاءة، ومعالجة السياقات الطويلة، وإمكانية دمج الأدوات الخارجية. ينتمي هذا النموذج إلى عائلة ERNIE-4.5، ويعتمد على بنية “مزيج الخبراء” (MoE) بمعلمات إجمالية تبلغ 21 مليار، لكنه لا يُنشط سوى 3 مليارات معلمة لكل رمز (Token)، مما يجعله فعالاً من حيث الحوسبة مع الحفاظ على قدرة تفكير تنافسية. ويتم توفير هذا النموذج بموجب ترخيص Apache-2.0، وهو متاح للاستخدام البحثي والتجاري عبر منصة Hugging Face.
تصميم النموذج المعماري
يعتمد ERNIE-4.5-21B-A3B-Thinking على بنية “مزيج الخبراء” (MoE). بدلاً من تنشيط جميع المعلمات البالغة 21 مليار، يقوم جهاز التوجيه بتحديد مجموعة فرعية من الخبراء، مما يؤدي إلى تنشيط 3 مليارات معلمة لكل رمز. هذا التصميم يقلل من الحسابات دون المساومة على تخصص الخبراء المختلفين. وقد استخدم فريق البحث خسارة التعامد لجهاز التوجيه وخسارة التوازن بين الرموز لتشجيع تنشيط الخبراء المتنوع والثبات أثناء التدريب. يوفر هذا التصميم حلًا وسطًا بين النماذج الكثيفة الصغيرة والأنظمة الضخمة جدًا. ويُفترض أن 3 مليارات معلمة فعالة لكل رمز تمثل نقطة مثالية من حيث أداء التفكير وكفاءة الاستخدام.
معالجة السياقات الطويلة
من أهم مميزات ERNIE-4.5-21B-A3B-Thinking قدرته على معالجة سياقات بطول 128 ألف رمز. يسمح هذا للنموذج بمعالجة وثائق طويلة جدًا، وإجراء عمليات تفكير متعددة الخطوات، ودمج مصادر البيانات المنظمة مثل الأوراق الأكاديمية أو قواعد البيانات البرمجية متعددة الملفات. تم تحقيق ذلك من خلال التوسع التدريجي لدالات الترميز الدورانية (RoPE) – بزيادة قاعدة التردد تدريجيًا من 10 آلاف إلى 500 ألف خلال التدريب. كما تم استخدام تحسينات إضافية، بما في ذلك الانتباه FlashMask والجدولة الموفرة للذاكرة، لجعل هذه العمليات الحسابية قابلة للتطبيق.
استراتيجية التدريب
يتبع النموذج وصفة التدريب متعددة المراحل المُحددة في عائلة ERNIE-4.5:
- المرحلة الأولى (مرحلة ما قبل التدريب النصية): بناء العمود الفقري اللغوي الأساسي، بدءًا من سياق 8 آلاف رمز وصولاً إلى 128 ألف رمز.
- المرحلة الثانية (تدريب الرؤية): تم تخطي هذه المرحلة في هذا المتغير النصي فقط.
- المرحلة الثالثة (التدريب متعدد الوسائط المشترك): لم يتم استخدام هذه المرحلة أيضًا، حيث أن A3B-Thinking نصي بحت.
تركز مرحلة ما بعد التدريب على مهام التفكير. ويستخدم فريق البحث ضبطًا دقيقًا مُشرفًا (SFT) عبر الرياضيات، والمنطق، والبرمجة، والعلوم، تليها تعزيز التعلم التدريجي (PRL). تبدأ مراحل التعزيز بالمنطق، ثم تمتد إلى الرياضيات والبرمجة، وأخيرًا إلى مهام التفكير الأوسع. ويتم تعزيز ذلك من خلال تحسين التفضيلات الموحدة (UPO)، الذي يدمج تعلم التفضيلات مع PPO لتحقيق الاستقرار في المحاذاة وتقليل القرصنة المكافآت.
استخدام الأدوات
يدعم ERNIE-4.5-21B-A3B-Thinking استدعاء الوظائف والأدوات المنظمة، مما يجعله مفيدًا في السيناريوهات التي تتطلب حسابات خارجية أو استرجاع بيانات. يمكن للمطورين دمجه مع vLLM، وTransformers 4.54+، وFastDeploy. تُناسب هذه القدرة على استخدام الأدوات بشكل خاص توليد البرامج، والتفكير الرمزي، وعمليات سير العمل متعددة الوكلاء. يسمح استدعاء الوظائف المدمج للنموذج بالتفكير في سياقات طويلة مع استدعاء واجهات برمجة التطبيقات الخارجية ديناميكيًا، وهو شرط أساسي للتفكير التطبيقي في أنظمة المؤسسات.
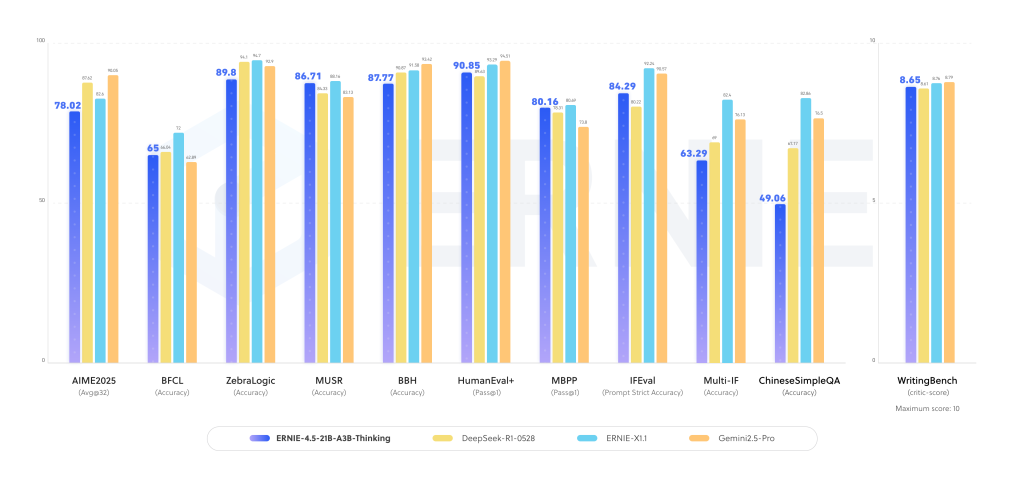
الأداء على معايير التفكير
يُظهر النموذج تحسينات كبيرة في الأداء عبر التفكير المنطقي، والرياضيات، وأسئلة الإجابة العلمية، ومهام البرمجة. في التقييمات، أظهر النموذج:
- دقة مُحسّنة في مجموعات بيانات التفكير متعدد الخطوات، حيث تكون سلاسل التفكير الطويلة مطلوبة.
- قدرة تنافسية مع النماذج الكثيفة الأكبر في مهام التفكير في مجالات العلوم والتكنولوجيا والهندسة والرياضيات (STEM).
- توليد نصوص ثابت وأداء في التركيب الأكاديمي، مستفيدًا من تدريب السياق المُوسّع.
تشير هذه النتائج إلى أن بنية MoE تُضخم تخصص التفكير، مما يجعلها فعالة دون الحاجة إلى مليارات المعلمات الكثيفة.
مقارنة مع نماذج LLMs الأخرى المُركزة على التفكير
يدخل هذا الإصدار في المنافسة مع نماذج أخرى مثل o3 من OpenAI، وClaude 4 من Anthropic، وDeepSeek-R1، وQwen-3. يعتمد العديد من هذه المنافسين على بنيات كثيفة أو عدد أكبر من المعلمات النشطة. يُقدم اختيار فريق بحث بايدو لنموذج MoE المضغوط مع 3 مليارات معلمة نشطة توازنًا مختلفًا:
- التوسع: يقلل التنشيط المتفرق من تكلفة الحوسبة مع زيادة سعة الخبراء.
- الاستعداد للسياقات الطويلة: تم تدريب سياق 128 ألف رمز بشكل مباشر، وليس بشكل مُعدّل.
- الانفتاح التجاري: يُقلل ترخيص Apache-2.0 من احتكاك التبني للمؤسسات.
ملخص
يُوضح ERNIE-4.5-21B-A3B-Thinking كيف يمكن تحقيق التفكير العميق دون الحاجة إلى عدد هائل من المعلمات الكثيفة. من خلال الجمع بين توجيه MoE الفعال، وتدريب السياقات بطول 128 ألف رمز، ودمج الأدوات، يقدم فريق بحث بايدو نموذجًا يُوازن بين التفكير البحثي وإمكانية الاستخدام. يمكنكم زيارة صفحة النموذج على Hugging Face و [الورقة البحثية](رابط الورقة البحثية إن وجد).
مواضيع مشابهة:
 دليل برمجي خطوة بخطوة لدمج أدوات البحث والتوصية في الوقت الحقيقي من Dappier AI مع واجهة برمجة تطبيقات دردشة OpenAI
من إليزا إلى نمذجة المحادثة: تطور أنظمة وباراديغمات الذكاء الاصطناعي المحادثي
دليل برمجي خطوة بخطوة لدمج أدوات البحث والتوصية في الوقت الحقيقي من Dappier AI مع واجهة برمجة تطبيقات دردشة OpenAI
من إليزا إلى نمذجة المحادثة: تطور أنظمة وباراديغمات الذكاء الاصطناعي المحادثي
 أداة Llama Prompt Ops: تحسين استجابات نماذج Llama بسهولة
أداة Llama Prompt Ops: تحسين استجابات نماذج Llama بسهولة
 هل يمكن الكشف الآلي عن الهلوسة في نماذج اللغات الكبيرة؟ دراسة نظرية وتطبيقية
هل يمكن الكشف الآلي عن الهلوسة في نماذج اللغات الكبيرة؟ دراسة نظرية وتطبيقية



اترك تعليقاً