
هلوسات نماذج اللغات الكبيرة: رحلة من مرحلة ما قبل التدريب إلى ما بعده
تُعرف نماذج اللغات الكبيرة (LLMs) بقدرتها المذهلة على توليد نصوص متماسكة، إلا أنها تعاني أحيانًا من مشكلة “الهلوسات”، وهي إنتاج إجابات واثقة لكنها خاطئة تبدو منطقية في ظاهرها. على الرغم من التطورات المُحرزة في طرق التدريب والهندسة المعمارية، إلا أن هذه المشكلة ما زالت قائمة. بحث جديد من OpenAI يقدم تفسيراً دقيقاً لهذه الظاهرة، مُشيراً إلى أن أصل الهلوسات يكمن في الخصائص الإحصائية لتعلم الإشراف مقابل التعلم الذاتي، وأن استمرارها يُعزى إلى معايير التقييم غير المُناسبة.
ما الذي يجعل الهلوسات أمراً حتمياً إحصائياً؟
يُفسر فريق البحث الهلوسات على أنها أخطاء جوهرية في عملية النمذجة التوليدية. حتى مع بيانات تدريب نظيفة تماماً، فإن دالة التوزيع المُستخدمة في مرحلة ما قبل التدريب تُحدث ضغوطاً إحصائية تؤدي إلى ظهور الأخطاء. قام الفريق بتبسيط المشكلة إلى مهمة تصنيف ثنائية مُشرف عليها تُسمى “هل هي صحيحة؟” (IIV): تحديد ما إذا كان مُخرَج النموذج صحيحاً أم خاطئاً. وقد أثبتوا أن معدل الخطأ التوليدي لنموذج اللغات الكبيرة هو ضعف معدل تصنيف IIV على الأقل. بعبارة أخرى، تحدث الهلوسات لنفس الأسباب التي تظهر بها التصنيفات الخاطئة في التعلم المُشرف: عدم اليقين المعرفي، نماذج رديئة، تحول في التوزيع، أو بيانات ضوضاء.
لماذا تُحفز الحقائق النادرة المزيد من الهلوسات؟
أحد أهم العوامل المُساعدة هو معدل العناصر الفريدة – وهي نسبة الحقائق التي تظهر مرة واحدة فقط في بيانات التدريب. بالمُقارنة مع تقدير الكتلة المفقودة لـ Good-Turing، إذا كانت 20% من الحقائق فريدة، فإن 20% منها على الأقل ستكون هلوسات. هذا يُفسر لماذا تُجيب نماذج اللغات الكبيرة بشكل موثوق حول الحقائق المُتكررة على نطاق واسع (مثل عيد ميلاد أينشتاين) ولكنها تفشل في الحقائق المُبهمة أو النادرة.
هل يمكن أن تؤدي عائلات النماذج الضعيفة إلى الهلوسات؟
نعم. تظهر الهلوسات أيضاً عندما لا تتمكن فئة النموذج من تمثيل النمط بشكل كافٍ. أمثلة كلاسيكية على ذلك تشمل نماذج n-gram التي تُنتج جُملاً غير نحوية، أو نماذج التجزئة الحديثة التي تُخطئ في عد الأحرف لأن الحروف مُخفية داخل رموز الكلمات الفرعية. هذه القيود التمثيلية تُسبب أخطاء منهجية حتى عندما تكون البيانات نفسها كافية.
لماذا لا يُزيل التدريب اللاحق الهلوسات؟
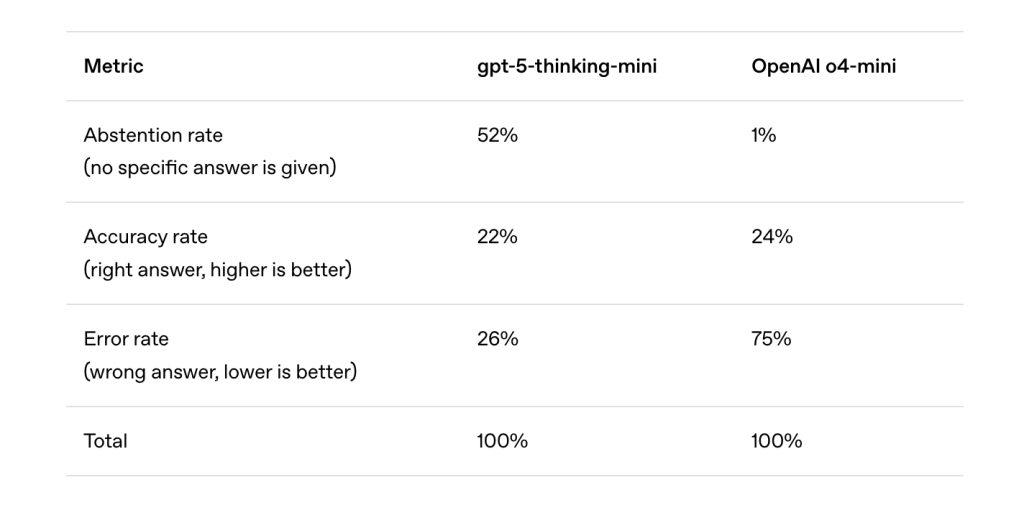
تُقلل طرق التدريب اللاحق مثل RLHF (التعلم التعزيزي من التغذية الراجعة البشرية)، و DPO، و RLAIF من بعض الأخطاء، خاصةً المُخرجات الضارة أو التآمرية. لكن الهلوسات المُفرطة في الثقة تبقى لأن حوافز التقييم غير مُحاذاة. مثل الطلاب الذين يخمنون في اختبارات الاختيار من متعدد، تُكافأ نماذج اللغات الكبيرة على التظاهر بالمعرفة عندما تكون غير متأكدة. تُطبق معظم معايير القياس – مثل MMLU، و GPQA، و SWE-bench – التصنيف الثنائي: الإجابات الصحيحة تحصل على نقاط، والامتناع عن الإجابة (“لا أعرف”) لا يحصل على نقاط، والإجابات الخاطئة لا تُعاقب بشكل أكثر شدة من الامتناع عن الإجابة. في ظل هذا النظام، يُعظم التخمين درجات معايير القياس، حتى لو أدى ذلك إلى زيادة الهلوسات.
كيف تُعزز لوحات المتصدرين الهلوسات؟
يُظهر استعراض معايير القياس الشائعة أن جميعها تقريباً تستخدم التقدير الثنائي بدون أي اعتماد جزئي لعدم اليقين. نتيجة لذلك، فإن النماذج التي تُعبّر عن عدم اليقين بصراحة تُحقق أداءً أسوأ من تلك التي تخمن دائماً. هذا يُخلق ضغطاً منهجياً على المُطورين لتحسين النماذج من أجل الحصول على إجابات واثقة بدلاً من المُعيرة.
ما التغييرات التي يمكن أن تُقلل من الهلوسات؟
يُجادل فريق البحث بأن إصلاح الهلوسات يتطلب تغييراً اجتماعياً-تقنياً، وليس فقط مجموعات تقييم جديدة. يقترحون أهداف ثقة صريحة: يجب أن تُحدد معايير القياس بوضوح عقوبات الإجابات الخاطئة والاعتماد الجزئي على الامتناع عن الإجابة. على سبيل المثال: “أجب فقط إذا كنت واثقاً بنسبة >75%. الخطأ يُخسر نقطتين؛ الإجابة الصحيحة تحصل على نقطة واحدة؛ و”لا أعرف” تحصل على صفر”. هذا التصميم يُحاكي الامتحانات الحقيقية مثل التنسيقات السابقة لـ SAT و GRE، حيث كان للتخمين عقوبات. وهو يُشجع على المعايرة السلوكية – حيث تمتنع النماذج عن الإجابة عندما تكون ثقتها أقل من الحد المحدد، مما يُنتج عددًا أقل من الهلوسات المُفرطة في الثقة مع الاستمرار في تحسين أداء معايير القياس.
ما هي الآثار الأوسع نطاقاً؟
يعيد هذا العمل صياغة الهلوسات كنتائج مُتوقعة لأهداف التدريب وعدم مُحاذاة التقييم بدلاً من كونها غرائب لا تُفسر. وتُبرز النتائج ما يلي:
- حتمية ما قبل التدريب: الهلوسات تُشابه أخطاء التصنيف الخاطئة في التعلم المُشرف.
- تعزيز ما بعد التدريب: تُحفز مخططات التقدير الثنائية على التخمين.
- إصلاح التقييم: تعديل معايير القياس الرئيسية لمكافأة عدم اليقين يمكن أن يُعيد مُحاذاة الحوافز ويُحسّن الموثوقية.
من خلال ربط الهلوسات بنظرية التعلم المُثبتة، يُزيل البحث الغموض عن أصلها ويُقترح استراتيجيات تخفيف عملية تُحوّل المسؤولية من هندسة النماذج إلى تصميم التقييم.




اترك تعليقاً