
نماذج ترجمة هونيوان متعددة اللغات من تنسنت: أداء متميز مفتوح المصدر
أعلنت مجموعة هونيوان من تنسنت مؤخراً عن إطلاق نموذجين متطورين للترجمة الآلية متعددة اللغات: هونيوان-MT-7B وهونيوان-MT-Chimera-7B. يُعد هذان النموذجان إضافةً قيّمةً لمجال الترجمة الآلية، حيث حققا نتائج مبهرة في العديد من الاختبارات، متفوقين على العديد من النماذج الأخرى الأكبر حجماً. وقد شاركت تنسنت بهذين النموذجين في مهمة الترجمة الآلية العامة ضمن مسابقة WMT2025، محققة المركز الأول في 30 زوجاً لغوياً من أصل 31.
لمحة عامة عن النماذج
-
هونيوان-MT-7B: نموذج ترجمة يحتوي على 7 مليارات بارامتر، يدعم الترجمة المتبادلة بين 33 لغة، بما في ذلك لغات الأقليات الصينية مثل التبتية والمنغولية والويغورية والكازاخستانية. تم تحسينه للعمل بكفاءة عالية مع اللغات الغنية بالبيانات واللغات الفقيرة بالبيانات على حد سواء، محققاً نتائج متقدمة مقارنةً بنماذج أخرى بنفس الحجم.
-
هونيوان-MT-Chimera-7B: نموذج متكامل يدمج نتائج ترجمة متعددة في وقت الاستنتاج، وينتج ترجمة مُحسّنة باستخدام تقنيات التعلم المعزز. يُعتبر هذا النموذج الأول من نوعه مفتوح المصدر، مما يحسن جودة الترجمة بشكل ملحوظ مقارنةً بنماذج الترجمة أحادية النظام.
إطار عمل التدريب
تم تدريب النموذجين باستخدام إطار عمل من خمس مراحل مصمم خصيصاً لمهام الترجمة:
-
التدريب المسبق العام: استخدم 1.3 تريليون رمز مميز يغطي 112 لغة اللهجة. تم تقييم مجموعات البيانات متعددة اللغات من حيث قيمة المعرفة والمصداقية وأسلوب الكتابة، مع الحفاظ على التنوع من خلال أنظمة وسم حسب التخصص والصناعة والموضوع.
-
التدريب المسبق الموجه للترجمة: استخدم مجموعات بيانات أحادية اللغة من mC4 وOSCAR، مع تصفية البيانات باستخدام fastText (لتحديد اللغة)، وminLSH (لإزالة الازدواجية)، وKenLM (لتصفية البيانات بناءً على تعقيدها). كما تم استخدام مجموعات بيانات متوازية من OPUS وParaCrawl، مع تصفية البيانات باستخدام CometKiwi. تم إعادة استخدام 20% من بيانات التدريب المسبق العام لتجنب نسيان المعلومات المكتسبة سابقاً.
-
التحسين الدقيق الخاضع للإشراف (SFT):
- المرحلة الأولى: حوالي 3 ملايين زوج لغوي متوازي (Flores-200، مجموعات اختبار WMT، بيانات مُعالجة للغة الصينية ولهجاتها، أزواج لغوية اصطناعية، بيانات تدريب إرشادية).
- المرحلة الثانية: حوالي 268 ألف زوج لغوي عالي الجودة تم اختياره من خلال التقييم الآلي (CometKiwi، GEMBA) والتحقق اليدوي.
-
التعلم المعزز (RL): خوارزمية GRPO. وظائف المكافأة: تقييم جودة XCOMET-XXL وDeepSeek-V3-0324. مكافآت تعتمد على المصطلحات (TAT-R1). عقوبات للتكرار لتجنب النتائج المتدهورة.
-
التعلم المعزز من الضعيف إلى القوي: تم توليد عدة نتائج مرشحة ودمجها من خلال مكافآت تعتمد على النتائج. تم تطبيق هذه التقنية في هونيوان-MT-Chimera-7B، مما يحسن من متانة الترجمة ويقلل من الأخطاء المتكررة.
النتائج
التقييم الآلي:
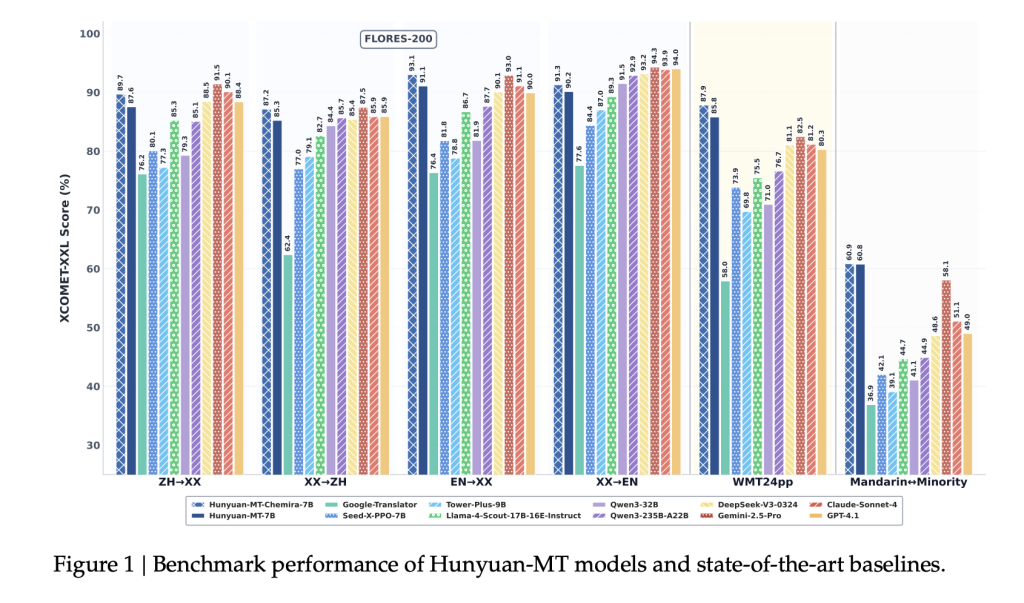
- WMT24pp (الإنجليزية⇔اللغات الأخرى): حقق هونيوان-MT-7B درجة 0.8585 (XCOMET-XXL)، متجاوزاً نماذج أكبر مثل Gemini-2.5-Pro (0.8250) وClaude-Sonnet-4 (0.8120).
- FLORES-200 (33 لغة، 1056 زوج): سجل هونيوان-MT-7B درجة 0.8758 (XCOMET-XXL)، متفوقاً على النماذج مفتوحة المصدر مثل Qwen3-32B (0.7933).
- اللغة الصينية القياسية⇔لغات الأقليات: سجل درجة 0.6082 (XCOMET-XXL)، أعلى من Gemini-2.5-Pro (0.5811)، مما يدل على تحسينات كبيرة في بيئات اللغات الفقيرة بالبيانات.
النتائج المقارنة:
- يتفوق على مترجم جوجل بنسبة 15-65% عبر فئات التقييم.
- يتفوق على نماذج الترجمة المتخصصة مثل Tower-Plus-9B وSeed-X-PPO-7B على الرغم من امتلاكه لعدد أقل من المعلمات.
- يضيف Chimera-7B تحسيناً بنسبة 2.3% تقريباً على FLORES-200، خاصةً في ترجمة اللغة الصينية⇔اللغات الأخرى والترجمة بين اللغات غير الإنجليزية.
التقييم البشري:
أظهر التقييم البشري باستخدام مجموعة بيانات مخصصة تغطي المجالات الاجتماعية والطبية والقانونية والإنترنت أن هونيوان-MT-7B يقارب جودة النماذج الكبيرة المملوكة، على الرغم من صغر حجمه (7 مليارات بارامتر):
- هونيوان-MT-7B: متوسط 3.189
- Gemini-2.5-Pro: متوسط 3.223
- DeepSeek-V3: متوسط 3.219
- مترجم جوجل: متوسط 2.344
دراسات حالة
يبرز التقرير العديد من حالات الاستخدام في العالم الحقيقي، مثل:
- المرجعيات الثقافية: ترجمة صحيحة لـ “小红薯” باسم منصة “REDnote”، على عكس ترجمة جوجل “بطاطا حلوة”.
- المصطلحات العامية: ترجمة “You are killing me” إلى “你真要把我笑死了” (التي تعبر عن التسلية)، بدلاً من الترجمة الحرفية الخاطئة.
- المصطلحات الطبية: ترجمة دقيقة لـ “uric acid kidney stones”، بينما تنتج النماذج الأخرى نتائج مشوهة.
- لغات الأقليات: إنتاج ترجمات متماسكة للكازاخستانية والتبتية، حيث تفشل النماذج الأخرى أو تنتج نصوصاً غير منطقية.
- تحسينات Chimera: إضافة تحسينات في مصطلحات الألعاب، وكلمات التكثيف، ومصطلحات الرياضة.
الخاتمة
يُمثل إطلاق تنسنت لنموذجي هونيوان-MT-7B وهونيوان-MT-Chimera-7B معياراً جديداً للترجمة مفتوحة المصدر. من خلال الجمع بين إطار عمل تدريب مدروس بعناية والتركيز على ترجمة اللغات المنخفضة الموارد ولغات الأقليات، حققت النماذج جودة تُضاهي أو تتجاوز أنظمة المصدر المغلقة الأكبر حجماً. يُتيح إطلاق هذين النموذجين لمجتمع أبحاث الذكاء الاصطناعي أدوات عالية الأداء وسهلة الوصول لأبحاث ونشر الترجمة متعددة اللغات.
يمكنكم الاطلاع على الورقة البحثية، صفحة جيثب، والنموذج على Hugging Face.






اترك تعليقاً