
نماذج هرمس 4: ثورةٌ في معالجة اللغة الطبيعية بالذكاء الاصطناعي مفتوح المصدر
أعلنت شركة Nous Research مؤخراً عن إطلاق عائلة نماذج هرمس 4 (Hermes 4)، وهي مجموعة من نماذج الذكاء الاصطناعي مفتوحة الوزن (Open-Weight) ذات قدرات استنتاجية متقدمة. تتوافر هذه النماذج بثلاثة أحجام مختلفة، 14 مليار، و70 مليار، و405 مليار بارامتر، وتعتمد على نقاط تفتيش Llama 3.1. وتتميز هذه النماذج بتحقيقها لأداءً متقدماً باستخدام تقنيات ما بعد التدريب فقط.
آلية الاستنتاج الهجين في هرمس 4
تتميز نماذج هرمس 4 بآلية استنتاج هجين، حيث يمكنها التبديل بين الاستجابات القياسية والاستنتاج الصريح باستخدام علامات <think>...</think> عندما تتطلب المشاكل المعقدة تفكيراً أعمق. هذا يسمح للنموذج بالتفكير خطوة بخطوة وتقديم تفسير منطقي لإجاباته، مما يزيد من الشفافية والفهم.
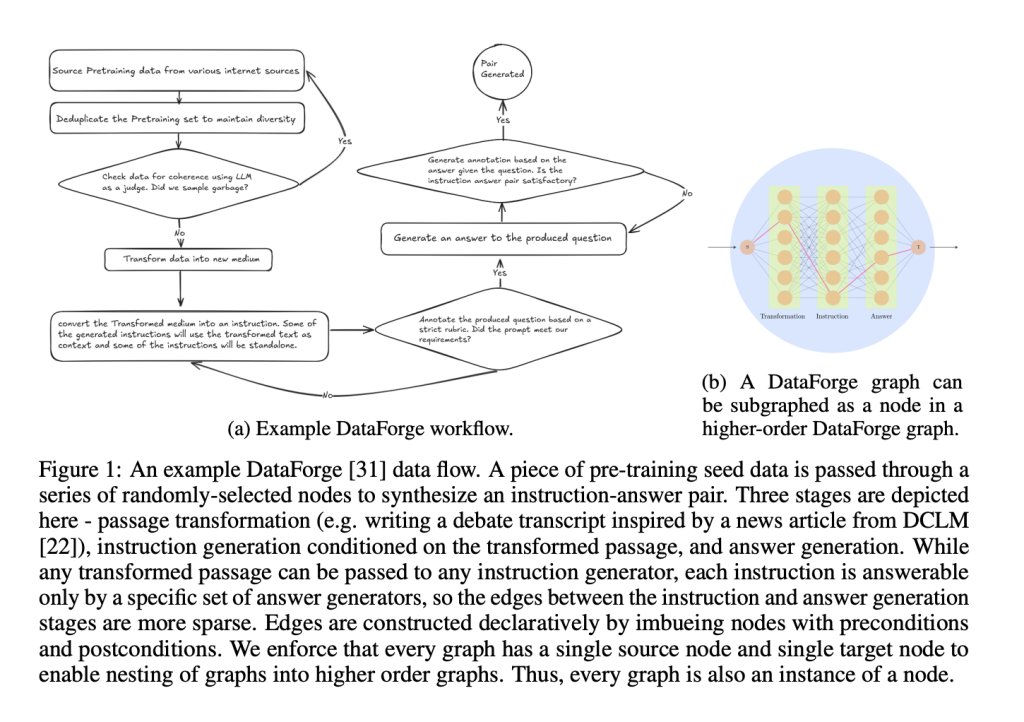
DataForge: توليد البيانات الاصطناعية القائمة على الرسوم البيانية
يُعد DataForge المكون الرئيسي وراء بنية هرمس 4 الأساسية. وهو نظام ثوري لتوليد البيانات الاصطناعية القائمة على الرسوم البيانية، ويُغير طريقة إنشاء بيانات التدريب. على عكس أساليب الإعداد التقليدية، يعمل DataForge من خلال رسم بياني دوري غير مُوجه (DAG)، حيث يُنفذ كل عقدة واجهة عمل بلغة تعريف مجال التخطيط (PDDL). يحدد كل عقدة الشروط المسبقة، والشروط اللاحقة، والتحويلات، مما يُسهل إنشاء خطوط أنابيب البيانات المعقدة تلقائيًا.
باستخدام بيانات البذور قبل التدريب من DCLM و FineWeb، يمكن للنظام تحويل مقال من ويكيبيديا إلى أغنية راب، ثم توليد أزواج تعليمات/إجابات بناءً على هذا التحويل. يُنتج هذا النهج حوالي 5 ملايين عينة، بإجمالي 19 مليار رمز، مع عِدّة عينات استنتاجية كثيفة الرموز – بمتوسط خمسة أضعاف عدد الرموز مقارنةً بنظيراتها غير الاستنتاجية لاستيعاب آثار التفكير التي تصل إلى 16000 رمز.
أخذ العينات بالرفض على نطاق غير مسبوق
تستخدم هرمس 4 بيئة التعلم المعزز مفتوحة المصدر Atropos من Nous Research لتنفيذ أخذ العينات بالرفض عبر حوالي 1000 مُحقق مُخصص للمهام. تُصفّي هذه البنية التحتية للتحقق الضخمة مسارات الاستنتاج عالية الجودة عبر مجالات متنوعة. تشمل بيئات التحقق الرئيسية تدريب تنسيق الإجابة (مكافأة التنسيق الصحيح عبر أكثر من 150 تنسيقًا للإخراج)، واتباع التعليمات (باستخدام مهام RLVR-IFEval ذات القيود المعقدة)، والالتزام بالهيكل التخطيطي (لتوليد JSON باستخدام نماذج Pydantic)، وتدريب استخدام الأدوات للسلوك الوكيل.
تُنشئ عملية أخذ العينات بالرفض مجموعة كبيرة من مسارات الاستنتاج المُتحقّق منها، مع مسارات حلول فريدة متعددة لنفس النتيجة المُتحقّق منها. يضمن هذا النهج تعلم النموذج لأنماط استنتاج قوية بدلاً من حفظ قوالب حلول محددة.
التحكم في الطول: حل مشكلة التوليد الطويل جدًا
تُعالج إحدى المساهمات الأكثر ابتكارًا في هرمس 4 مشكلة الاستنتاج الطويل جدًا – حيث تُنشئ نماذج الاستنتاج سلاسل تفكير طويلة بشكل مفرط دون إنهاء. اكتشف فريق البحث أن نموذجهم البالغ 14 مليار بارامتر وصل إلى الحد الأقصى لطول السياق بنسبة 60% من الوقت على LiveCodeBench عندما يكون في وضع الاستنتاج. يتضمن حلّهم الفائق الفعالية مرحلة ضبط دقيق مُشرف ثانية تُعلّم النماذج إيقاف الاستنتاج عند 30000 رمز بالضبط:
- توليد آثار استنتاج من السياسة الحالية.
- إدراج رموز
</think>عند 30000 رمز بالضبط. - التدريب فقط على قرار الإنهاء، وليس سلسلة الاستنتاج.
- تطبيق تحديثات التدرج فقط على رموز
</think>و<eos>.
يحقق هذا النهج نتائج رائعة: انخفاض بنسبة 78.4% في التوليد الطويل جدًا على AIME’24، و65.3% على AIME’25، و79.8% على LiveCodeBench، مع تكلفة دقة نسبية تتراوح بين 4.7% و 12.7% فقط. من خلال التركيز على إشارات التعلم بالكامل على قرار الإنهاء، تتجنب هذه الطريقة مخاطر انهيار النموذج أثناء تعليم “سلوك العد” الفعال.
الأداء المرجعي والمحاذاة المحايدة
تُظهر هرمس 4 أداءً متطورًا بين نماذج الوزن المفتوح. يُحقق النموذج ذو 405 مليار بارامتر 96.3% على MATH-500 (وضع الاستنتاج)، و81.9% على AIME’24، و78.1% على AIME’25، و70.5% على GPQA Diamond، و61.3% على LiveCodeBench. يُعد أداءها على RefusalBench ملحوظًا بشكل خاص، حيث حققت 57.1% في وضع الاستنتاج – وهي أعلى نتيجة بين النماذج المُقيّمة، متجاوزةً GPT-4o (17.67%) و Claude Sonnet 4 (17%). يُظهر هذا استعداد النموذج للتعامل مع المواضيع المثيرة للجدل مع الحفاظ على الحدود المناسبة، مما يعكس فلسفة المحاذاة المحايدة لشركة Nous Research.
البنية التقنية والتدريب
يعتمد تدريب هرمس 4 على TorchTitan مُعدّل عبر 192 وحدة معالجة رسوميات NVIDIA B200. يتعامل النظام مع توزيع طول العينة غير المتجانسة للغاية من خلال التعبئة الفعالة (تحقيق كفاءة دفعة >99.9%)، والانتباه المرن، وقناع الخسارة المتطور حيث تساهم فقط رموز دور المُساعد في خسارة الانتروبيا المتقاطعة. يتبع التدريب جدول معدل تعلم جيبّي مع 300 خطوة إحماء و 9000 خطوة إجمالية بطول سياق 16384 رمزًا مع حجم دفعة عالمي يبلغ 384 عينة، مع الجمع بين التوازي للدُفعات، والتوازي للموتر، والتوازي الكامل للبيانات المُجزأة.
الخلاصة
تُمثل هرمس 4 تقدمًا هامًا في تطوير الذكاء الاصطناعي مفتوح المصدر، مُثبتةً أن إمكانيات الاستنتاج المتقدمة يمكن تحقيقها من خلال منهجيات شفافة وقابلة للتكرار دون الاعتماد على بيانات تدريب خاصة أو عمليات تطوير مغلقة. من خلال الجمع بين توليد البيانات الاصطناعية القائمة على الرسوم البيانية المبتكرة، وأخذ العينات بالرفض على نطاق واسع، وآليات التحكم في الطول الأنيقة، ابتكرت Nous Research نماذج لا تُطابق فقط أداء أنظمة الملكية الرائدة، بل تحافظ أيضًا على المحاذاة المحايدة وقابلية التوجيه التي تجعلها أدوات مفيدة حقًا بدلاً من المساعدين المقيدين.
مواضيع مشابهة:
 بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه
بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه



اترك تعليقاً