
VibeVoice-1.5B: ثورةٌ جديدة في توليد الصوت الاصطناعي مفتوح المصدر
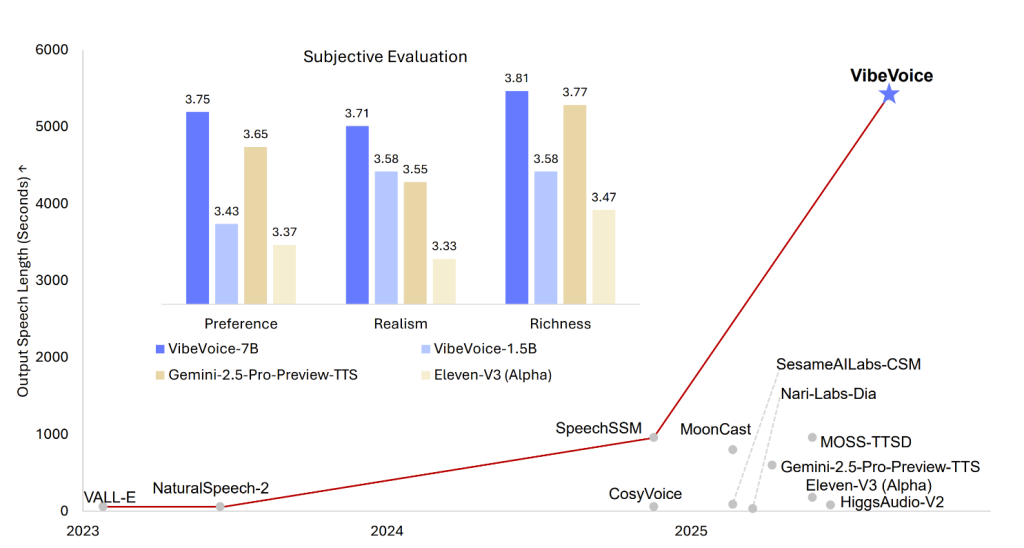
أطلقت مايكروسوفت مؤخراً نموذج VibeVoice-1.5B، وهو نموذج مفتوح المصدر لتقنية تحويل النص إلى كلام (TTS)، يُعيد تعريف حدود هذه التقنية من خلال توفير صوتٍ اصطناعيٍّ معبّرٍ، وطويل الأمد، ومتعدد المتحدثين، مرخص برخصة MIT، وقابل للتطوير، ومرن للغاية للاستخدامات البحثية. لا يعتبر هذا النموذج مجرد محرك آخر لتحويل النص إلى كلام، بل هو إطار عمل مصمم لتوليد ما يصل إلى 90 دقيقة من الصوت الطبيعي المتواصل، ودعم التوليد المتزامن لما يصل إلى أربعة متحدثين مميزين، بالإضافة إلى معالجة سيناريوهات التوليف عبر اللغات والغناء. مع بنيته المعمارية القائمة على البث المباشر، وإعلان نموذج أكبر (7B) في المستقبل القريب، يُرسّخ VibeVoice-1.5B مكانته كإنجازٍ رئيسيٍّ في مجال الصوت المحادثي المدعوم بالذكاء الاصطناعي، وتقنية البودكاست، وأبحاث الصوت الاصطناعي.
الميزات الرئيسية:
- دعم سياق ضخم ومتعدد المتحدثين: يستطيع VibeVoice-1.5B توليف ما يصل إلى 90 دقيقة من الكلام مع ما يصل إلى أربعة متحدثين مميزين في جلسة واحدة، متجاوزاً بكثير الحد الأقصى للمتحدثين (1-2) في نماذج TTS التقليدية.
- التوليد المتزامن: لا يقتصر النموذج على ربط مقاطع صوتية أحادية الصوت، بل إنه مصمم لدعم تدفقات صوتية متوازية لمتحدثين متعددين، مما يُحاكي المحادثة الطبيعية وتبادل الأدوار.
- التوليف عبر اللغات والغناء: على الرغم من أنه تم تدريبه بشكل أساسي على اللغتين الإنجليزية والصينية، إلا أن النموذج قادر على التوليف عبر اللغات، ويمكنه حتى توليد الغناء – وهي ميزات نادراً ما تُظهرها نماذج TTS مفتوحة المصدر السابقة.
- رخصة MIT: مفتوح المصدر بالكامل وصديق للاستخدام التجاري، مع التركيز على البحث والشفافية وإمكانية التكرار.
- قابل للتطوير للبث المباشر والصوت طويل الأمد: تم تصميم البنية المعمارية لكفاءة توليف الصوت طويل المدى، وتتوقع نموذجاً قادراً على البث المباشر 7B قريباً، مما يوسع إمكانيات TTS عالية الدقة في الوقت الحقيقي.
- العاطفة والتعبير: يتميز النموذج بالتحكم في العواطف والتعبير الطبيعي، مما يجعله مناسبًا لتطبيقات مثل البودكاست أو سيناريوهات المحادثة.
البنية المعمارية والغطس التقني:
يعتمد VibeVoice على نموذج لغوي كبير (LLM) يبلغ حجمه 1.5 مليار معلمة (Qwen2.5-1.5B)، والذي يتكامل مع مُشفّرين جديدين – صوتي ودلالي – وكلاهما مصمم للعمل بمعدل إطار منخفض (7.5 هرتز) من أجل الكفاءة الحسابية والاتساق عبر التسلسلات الطويلة.
- المُشفّر الصوتي: متغير σ-VAE مع بنية مُشفّر-مُشفّر معكوسة (كل منهما ~340 مليون معلمة)، يحقق تقليل حجم العينة بمقدار 3200 مرة من الصوت الخام عند 24 كيلوهرتز.
- المُشفّر الدلالي: تم تدريبه عبر مهمة وكيل ASR، وهذه البنية المُشفّرة فقط تعكس تصميم المُشفّر الصوتي (باستثناء مكونات VAE).
- رأس مُشفّر الانتشار: وحدة انتشار مشروطة خفيفة الوزن (~123 مليون معلمة) تتنبأ بالخصائص الصوتية، مستفيدة من توجيه Classifier-Free (CFG) و DPM-Solver لجودة إدراكية عالية.
- منهج طول السياق: يبدأ التدريب بـ 4000 رمز ويزداد تدريجياً حتى 65000 رمز – مما يُمكّن النموذج من توليد مقاطع صوتية طويلة ومتماسكة للغاية.
- نمذجة التسلسل: يفهم LLM تدفق الحوار لتبادل الأدوار، بينما يقوم رأس الانتشار بتوليد تفاصيل صوتية دقيقة – فصل الدلالة والتوليف مع الحفاظ على هوية المتحدث على المدى الطويل.
قيود النموذج والاستخدام المسؤول:
- اللغتان الإنجليزية والصينية فقط: تم تدريب النموذج فقط على هاتين اللغتين؛ قد ينتج عن اللغات الأخرى مخرجات غير مفهومة أو مسيئة.
- لا يوجد كلام متداخل: على الرغم من أنه يدعم تبادل الأدوار، إلا أن VibeVoice-1.5B لا يُنمذج الكلام المتداخل بين المتحدثين.
- الكلام فقط: لا يُولّد النموذج أصوات خلفية أو مؤثرات صوتية أو موسيقى – الإخراج الصوتي هو الكلام فقط.
- المخاطر القانونية والأخلاقية: تحظر مايكروسوفت صراحةً استخدام النموذج في تقليد الأصوات أو نشر المعلومات المضللة أو تجاوز عمليات المصادقة. يجب على المستخدمين الامتثال للقوانين والكشف عن المحتوى المُولّد بالذكاء الاصطناعي.
- غير مناسب للتطبيقات الاحترافية في الوقت الحقيقي: على الرغم من كفاءته، إلا أن هذا الإصدار ليس مُحسّنًا لتطبيقات منخفضة زمن الوصول أو التفاعلية أو البث المباشر؛ هذا هو الهدف من النسخة 7B القادمة.
الخاتمة:
يُمثل VibeVoice-1.5B من مايكروسوفت إنجازاً هاماً في مجال تقنية TTS المفتوحة المصدر: قابل للتطوير، ومعبّر، ومتعدد المتحدثين، مع بنية خفيفة الوزن تعتمد على الانتشار، مما يُفتح المجال أمام توليف الصوت المحادثي طويل الأمد للباحثين ومطوري البرمجيات مفتوحة المصدر. في حين يقتصر الاستخدام حاليًا على البحث ويقتصر على اللغتين الإنجليزية والصينية، إلا أن إمكانيات النموذج – ووعد الإصدارات القادمة – تُشير إلى تحول جذري في كيفية توليد الذكاء الاصطناعي للتفاعل مع الكلام الاصطناعي. بالنسبة للفِرق التقنية، ومُنشئي المحتوى، وهواة الذكاء الاصطناعي، يُعتبر VibeVoice-1.5B أداةً لا بد من استكشافها للجيل التالي من تطبيقات الصوت الاصطناعي – متوفر الآن على Hugging Face و GitHub، مع وثائق واضحة ورخصة مفتوحة. مع توجه المجال نحو تقنية TTS أكثر تعبيراً وتفاعلاً وشفافية أخلاقياً، يُعتبر أحدث عرض لمايكروسوفت معلماً بارزاً في مجال توليد الكلام الاصطناعي مفتوح المصدر.
أسئلة شائعة:
- ما الذي يجعل VibeVoice-1.5B مختلفًا عن نماذج تحويل النص إلى كلام الأخرى؟
يُمكن لـ VibeVoice-1.5B توليد ما يصل إلى 90 دقيقة من الصوت المعبر ومتعدد المتحدثين (حتى أربعة متحدثين)، ويدعم التوليف عبر اللغات والغناء، وهو مفتوح المصدر بالكامل بموجب رخصة MIT – مما يدفع حدود توليد الصوت المحادثي طويل الأمد المدعوم بالذكاء الاصطناعي.
- ما هي المواصفات الموصى بها لتشغيل النموذج محلياً؟
تُظهر اختبارات المجتمع أن توليد حوار متعدد المتحدثين باستخدام نقطة فحص 1.5B يستهلك حوالي 7 غيغابايت من ذاكرة الوصول العشوائي لوحدة معالجة الرسومات (VRAM)، لذا فإن بطاقة استهلاكية بسعة 8 غيغابايت (مثل RTX 3060) تكون كافية عموماً للاستدلال.
- ما هي اللغات وأنماط الصوت التي يدعمها النموذج حاليًا؟
تم تدريب VibeVoice-1.5B فقط على اللغتين الإنجليزية والصينية، ويمكنه إجراء سرد عبر اللغات (مثل: موجه إنجليزي → كلام صيني) بالإضافة إلى توليف الغناء الأساسي. يُنتج الكلام فقط – بدون أصوات خلفية – ولا يُنمذج المتحدثين المتداخلين؛ تبادل الأدوار متسلسل. يمكنك مراجعة التقرير التقني والنموذج على Hugging Face والرموز. لا تتردد في زيارة صفحة GitHub الخاصة بنا للحصول على البرامج التعليمية والرموز ودفاتر الملاحظات. كما يمكنك متابعتنا على Twitter، والانضمام إلى مجتمعنا ML SubReddit الذي يضم أكثر من 100000 عضو، والاشتراك في نشرتنا الإخبارية.
مواضيع مشابهة:
 بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه
بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه



اترك تعليقاً