
DeepSeek-V3.1: ثورةٌ في نماذج اللغات الكبيرة مفتوحة المصدر
أطلقت شركة DeepSeek الصينية، الرائدة في مجال الذكاء الاصطناعي، أحدث إصداراتها من نماذج اللغات الكبيرة: DeepSeek-V3.1. يُعتبر هذا الإصدار نقلة نوعية، إذ يبني على أساس النموذج السابق DeepSeek-V3، مُضيفاً تحسيناتٍ كبيرةً على قدرات الاستدلال، واستخدام الأدوات، وأداء البرمجة. وقد اكتسبت نماذج DeepSeek سمعةً طيبةً بسرعةٍ، نظراً لأدائها الذي يُضاهي نماذج OpenAI و Anthropic، بتكلفةٍ أقل بكثير.
مميزات DeepSeek-V3.1 المذهلة:
- وضع التفكير الهجين (Hybrid Thinking Mode): يدعم DeepSeek-V3.1 كلاً من وضعي التفكير (الاستدلال المتسلسل، الأكثر تدبراً) وعدم التفكير (التوليد المباشر، سلسلة الوعي)، ويمكن التبديل بينهما عبر قالب الدردشة. وهذا يمثل اختلافاً عن الإصدارات السابقة، ويُوفر مرونةً أكبر لتطبيقات متنوعة.
- دعم الأدوات والوكلاء (Tool and Agent Support): تم تحسين النموذج لاستدعاء الأدوات ومهام الوكيل (مثل: استخدام واجهات برمجة التطبيقات، وتنفيذ التعليمات البرمجية، والبحث). تستخدم استدعاءات الأدوات تنسيقاً مُنظماً، ويدعم النموذج وكلاء التعليمات البرمجية المخصصة ووكلاء البحث، مع توفير قوالب تفصيلية في المستودع.
- حجم هائل وكفاءة عالية في التنشيط (Massive Scale, Efficient Activation): يضم النموذج 671 مليار معلمة، مع تنشيط 37 مليار معلمة لكل رمز مميز – تصميم خليط الخبراء (MoE) الذي يخفض تكاليف الاستدلال مع الحفاظ على السعة. تبلغ نافذة السياق 128 ألف رمز مميز، وهي أكبر بكثير من معظم المنافسين.
- امتداد سياق طويل (Long Context Extension): يستخدم DeepSeek-V3.1 نهجاً ذا مرحلتين لامتداد السياق الطويل. تم تدريب المرحلة الأولى (32 ألف رمز مميز) على 630 مليار رمز مميز (10 أضعاف أكثر من V3)، والثانية (128 ألف رمز مميز) على 209 مليار رمز مميز (3.3 أضعاف أكثر من V3). تم تدريب النموذج باستخدام تقنية FP8 microscaling للحساب الكفؤ على أجهزة الجيل التالي.
- قالب الدردشة (Chat Template): يدعم القالب محادثات متعددة الأدوار مع رموز واضحة للمطالبات النظامية، واستفسارات المستخدم، وردود المساعد. يتم تشغيل وضعي التفكير وعدم التفكير بواسطة الرموز
<think>و</think>في تسلسل المطالبات.
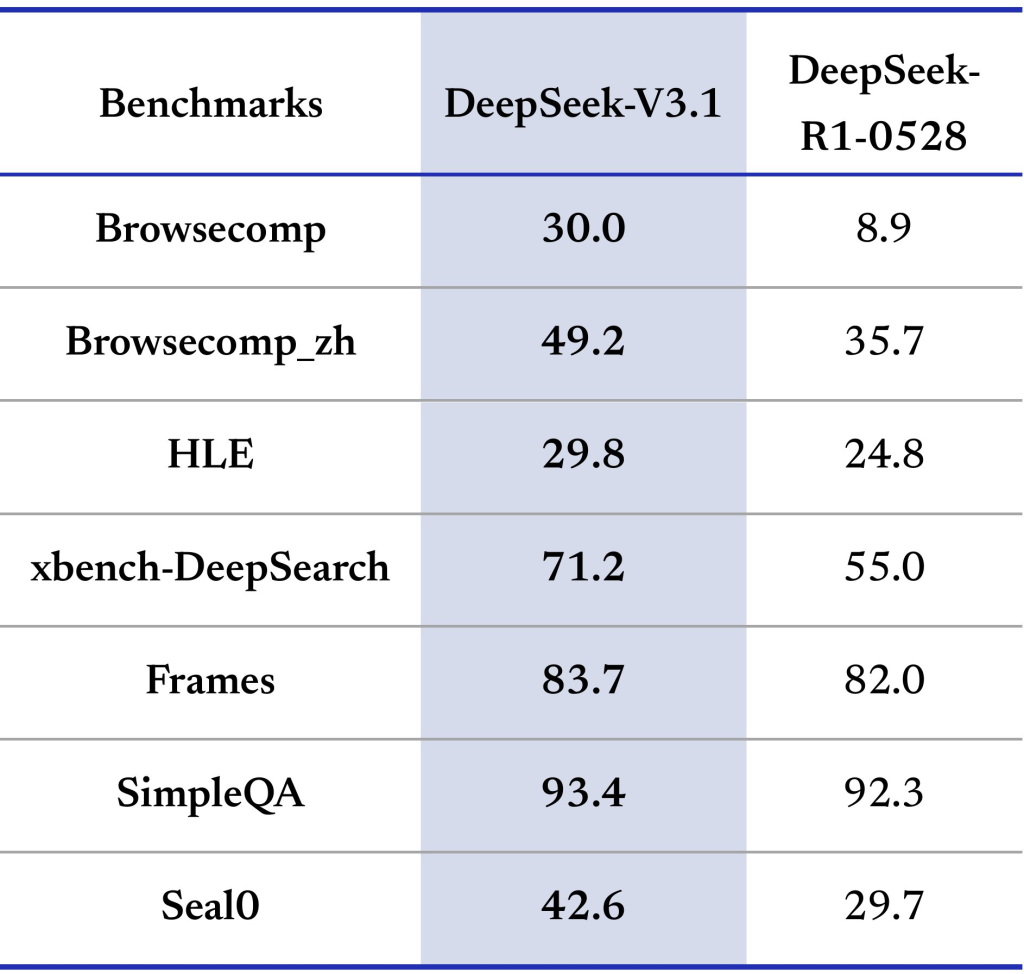
مقاييس الأداء:
تم تقييم DeepSeek-V3.1 عبر مجموعة واسعة من المقاييس (انظر الجدول أدناه)، بما في ذلك المعرفة العامة، والبرمجة، والرياضيات، واستخدام الأدوات، ومهام الوكيل. فيما يلي أبرز النقاط:
| المقاييس | DeepSeek-V3.1 (بدون تفكير) | DeepSeek-V3.1 (مع تفكير) | المنافسون (R1-0528) |
|---|---|---|---|
| MMLU-Redux (EM) | 91.8 | 93.7 | 93.4 |
| MMLU-Pro (EM) | 83.7 | 84.8 | 85.0 |
| GPQA-Diamond (Pass@1) | 74.9 | 80.1 | 81.0 |
| LiveCodeBench (Pass@1) | 56.4 | 74.8 | 73.3 |
| AIMÉ 2025 (Pass@1) | 49.8 | 88.4 | 87.5 |
| SWE-bench (وضع الوكيل) | 54.5 | – | 30.5 |
يُلاحظ أن وضع التفكير يُطابق أو يتجاوز باستمرار إصدارات الحالة الفنية السابقة، خاصةً في البرمجة والرياضيات. أما وضع عدم التفكير فهو أسرع، ولكنه أقل دقة قليلاً، مما يجعله مثالياً للتطبيقات الحساسة للوقت.
تكامل الأدوات ووكلاء التعليمات البرمجية:
- استدعاء الأدوات (Tool Calling): يتم دعم استدعاءات الأدوات المُنظمة في وضع عدم التفكير، مما يسمح بعمليات سير عمل قابلة للكتابة باستخدام واجهات برمجة التطبيقات والخدمات الخارجية.
- وكلاء التعليمات البرمجية (Code Agents): يمكن للمطورين إنشاء وكلاء تعليمات برمجية مخصصة باتباع قوالب المسار المُقدمة، والتي تُفصّل بروتوكول التفاعل لتوليد التعليمات البرمجية وتنفيذها و تصحيح الأخطاء.
- يمكن لـ DeepSeek-V3.1 استخدام أدوات بحث خارجية للحصول على معلومات محدثة، وهي ميزة أساسية لتطبيقات الأعمال، والتمويل، والبحوث التقنية.
التوزيع:
- مفتوح المصدر، ترخيص MIT: تتوفر جميع أوزان النموذج والتعليمات البرمجية مجاناً على Hugging Face و ModelScope بموجب ترخيص MIT، مما يشجع على كل من البحث والاستخدام التجاري.
- الاستدلال المحلي: هيكل النموذج متوافق مع DeepSeek-V3، وتتوفر تعليمات تفصيلية للنشر المحلي. يتطلب التشغيل موارد وحدة معالجة الرسومات (GPU) كبيرة نظرًا لحجم النموذج، ولكن النظام البيئي المفتوح وأدوات المجتمع تقلل من حواجز التبني.
الخلاصة:
يمثل DeepSeek-V3.1 علامة فارقة في نشر الذكاء الاصطناعي المتقدم، حيث يُظهر أن نماذج اللغات الكبيرة مفتوحة المصدر، وفعالة من حيث التكلفة، وقادرة للغاية. يُعد مزيج الاستدلال القابل للتطوير، وتكامل الأدوات، والأداء الاستثنائي في مهام البرمجة والرياضيات، خياراً عملياً لكل من البحث وتطوير الذكاء الاصطناعي التطبيقي.
لمعرفة المزيد:
مواضيع مشابهة:
 DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
 بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena
بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena



اترك تعليقاً