
مجموعة بيانات “جرناري” ونماذج معالجة الصوت المتطورة من NVIDIA: ثورة في الذكاء الاصطناعي متعدد اللغات
أعلنت شركة NVIDIA مؤخراً عن إطلاق مجموعة بيانات “جرناري” (Granary)، وهي أكبر مجموعة بيانات مفتوحة المصدر للصوت بلغات أوروبا، بالإضافة إلى نموذجين متطورين هما: Canary-1b-v2 و Parakeet-tdt-0.6b-v3. يمثل هذا الإطلاق نقلة نوعية في مجال التعرف الآلي على الكلام والترجمة الآلية للصوت، خاصةً للغات الأوروبية الأقل تمثيلًا.
جرناري: أساس الذكاء الاصطناعي متعدد اللغات
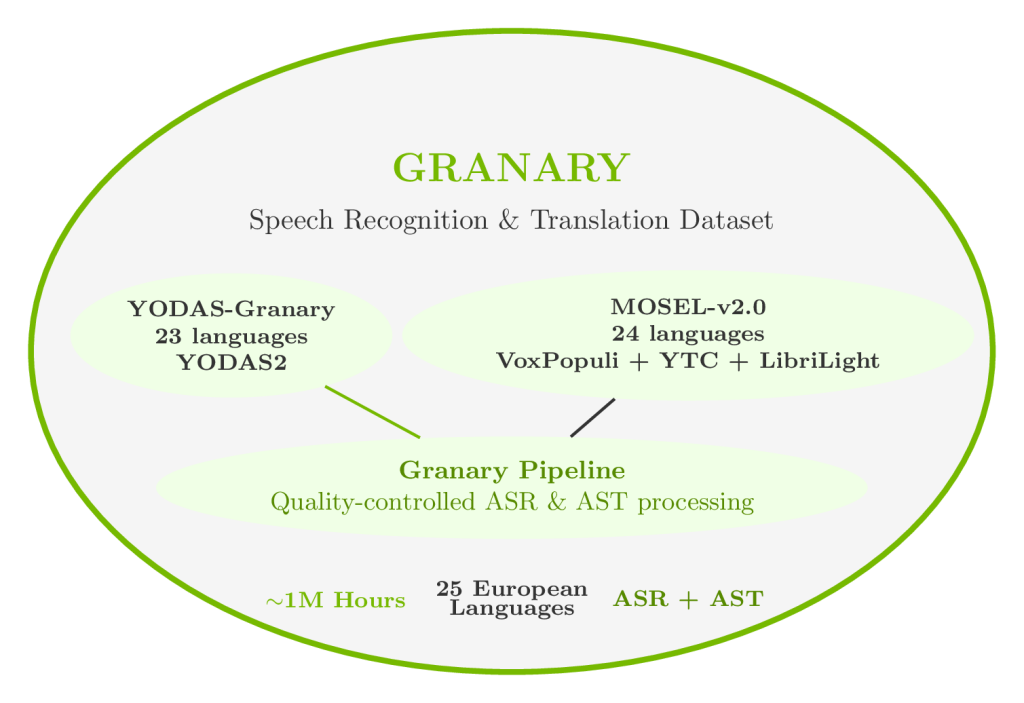
تُعدّ جرناري، التي طُورت بالتعاون مع جامعة كارنيغي ميلون ومؤسسة برونو كيسلر، مجموعة بيانات ضخمة ومتعددة اللغات تحتوي على حوالي مليون ساعة من البيانات الصوتية، منها ٦٥٠ ألف ساعة مخصصة للتعرف على الكلام، و ٣٥٠ ألف ساعة للترجمة الآلية. تغطي المجموعة ٢٥ لغة أوروبية، بما في ذلك جميع اللغات الرسمية للاتحاد الأوروبي تقريبًا، بالإضافة إلى الروسية والأوكرانية، مع التركيز بشكل خاص على اللغات ذات البيانات المحدودة، مثل الكرواتية والإستونية والمالطية.
مميزات جرناري الرئيسية:
- أكبر مجموعة بيانات مفتوحة المصدر للصوت بلغات أوروبا (٢٥ لغة).
- خط أنابيب لتصنيف البيانات (Pseudo-labeling): يتمّ معالجة البيانات الصوتية العامة غير المصنفة باستخدام معالج بيانات الصوت من NVIDIA NeMo، مما يُضيف بنية ويُعزز الجودة، ويُقلل من الحاجة إلى التصنيف اليدوي المكلف.
- تدعم كل من التعرف الآلي على الكلام والترجمة الآلية للصوت: مصممة لمهام النسخ والترجمة.
- الوصول المفتوح: متاحة لمجتمع المطورين العالمي لتدريب نماذج الإنتاج بمرونة.
بفضل البيانات النظيفة وعالية الجودة، تسمح جرناري بتقارب النماذج بشكل أسرع بكثير. أظهرت الأبحاث أن المطورين يحتاجون إلى نصف كمية بيانات جرناري للوصول إلى دقة الأهداف مقارنة بمجموعات البيانات المنافسة، مما يجعلها قيّمة بشكل خاص للغات ذات الموارد المحدودة ولإنشاء النماذج الأولية بسرعة.
Canary-1b-v2: التعرف الآلي على الكلام والترجمة متعددة اللغات (٢٤ لغة مع الإنجليزية)
Canary-1b-v2 هو نموذج مُشفّر-مُشفّر (Encoder-Decoder) يحتوي على مليار معامل، تم تدريبه على بيانات جرناري، ويُوفر نسخًا وترجمة عالية الجودة بين الإنجليزية و ٢٤ لغة أوروبية مدعومة. تم تصميمه لتحقيق الدقة والقدرات متعددة المهام:
- اللغات المدعومة: ٢٥ لغة أوروبية، مما يُضاعف تغطية Canary من ٤ لغات.
- الأداء المتطور: دقة مُقاربة لنماذج أكبر بثلاث مرات، ولكن سرعة الاستنتاج أسرع بعشرة أضعاف.
- القدرة على تعدد المهام: قوي في كل من مهام التعرف الآلي على الكلام والترجمة الآلية للصوت.
- الميزات: علامات الترقيم التلقائية، والكتابة بأحرف كبيرة، والوقت المخصص لكل كلمة ومقطع – حتى النتائج المُترجمة الموقوتة.
- الهندسة المعمارية: مُشفّر FastConformer مع مُشفّر Transformer؛ مُفردات موحدة لجميع اللغات عبر مُعالج SentencePiece.
- المتانة: يحافظ على أداء قوي في ظل الظروف الصاخبة ويقاوم الهلوسات في الإخراج.
أبرز نتائج التقييم:
- معدل خطأ الكلمات (WER) في التعرف الآلي على الكلام: ٧.١٥٪ (مجموعة بيانات AMI)، ١٠.٨٢٪ (مجموعة بيانات LibriSpeech Clean).
- نقاط COMET في الترجمة الآلية للصوت: ٧٩.٣ (من اللغات الأخرى إلى الإنجليزية)، ٨٤.٥٦ (من الإنجليزية إلى اللغات الأخرى).
الاستخدام: متاح بموجب ترخيص CC BY 4.0 ؛ مُحسّن لأنظمة NVIDIA المُسرّعة بمعالجات الرسوميات، مما يُمكّن من التدريب السريع والاستنتاج للاستخدام الإنتاجي القابل للتطوير.
Parakeet-tdt-0.6b-v3: التعرف الآلي على الكلام متعدد اللغات في الوقت الفعلي
Parakeet-tdt-0.6b-v3 هو نموذج للتعرف الآلي على الكلام متعدد اللغات يحتوي على ٦٠٠ مليون معامل، مصمم لإنتاجية عالية أو نسخ كميات كبيرة من البيانات الصوتية بجميع اللغات الـ ٢٥ المدعومة. يُوسّع عائلة Parakeet (التي كانت تركز سابقاً على اللغة الإنجليزية) لتشمل التغطية الأوروبية الكاملة.
- الكشف التلقائي عن اللغة: ينسخ البيانات الصوتية المدخلة دون الحاجة إلى مطالبات إضافية.
- القدرة على العمل في الوقت الفعلي: ينسخ مقاطع صوتية تصل إلى ٢٤ دقيقة بكفاءة في عملية استنتاج واحدة.
- سريع، قابل للتطوير، وجاهز للاستخدام التجاري: يُعطي الأولوية لانخفاض زمن الوصول، ومعالجة الدُفعات، والنتائج الدقيقة، مع تحديد الوقت لكل كلمة وعلامات الترقيم وكتابة الأحرف الكبيرة.
- المتانة: موثوق حتى في المحتوى المعقد (الأرقام، الكلمات) وظروف الصوت الصعبة.
تأثير تطوير الذكاء الاصطناعي للصوت
تساهم مجموعة بيانات جرناري ومجموعة النماذج من NVIDIA في تسريع عملية إتاحة الذكاء الاصطناعي للصوت في أوروبا، مما يُمكّن من التطوير القابل للتطوير لـ:
- روبوتات الدردشة متعددة اللغات.
- وكلاء خدمة العملاء الصوتيين.
- خدمات الترجمة الفورية تقريبًا.
يمكن للمطورين والباحثين والشركات الآن إنشاء تطبيقات شاملة وعالية الجودة تدعم التنوع اللغوي، مع إمكانية الوصول المفتوح إلى هذه النماذج ومجموعات البيانات الرائعة.
يمكنكم الاطلاع على جرناري، و NVIDIA Canary-1b-v2، و NVIDIA Parakeet-tdt-0.6b-v3. لا تترددوا في زيارة صفحة GitHub الخاصة بنا للحصول على الدروس التعليمية، والرموز، ودفاتر الملاحظات. كما يُمكنكم متابعتنا على تويتر، والانضمام إلى مجتمعنا المكون من أكثر من ١٠٠ ألف عضو في ريديت، والاشتراك في قائمتنا البريدية.






اترك تعليقاً