
دينو v3: ثورة جديدة في رؤية الحاسوب بفضل التعلم الذاتي الخالي من البيانات المُعلّمة
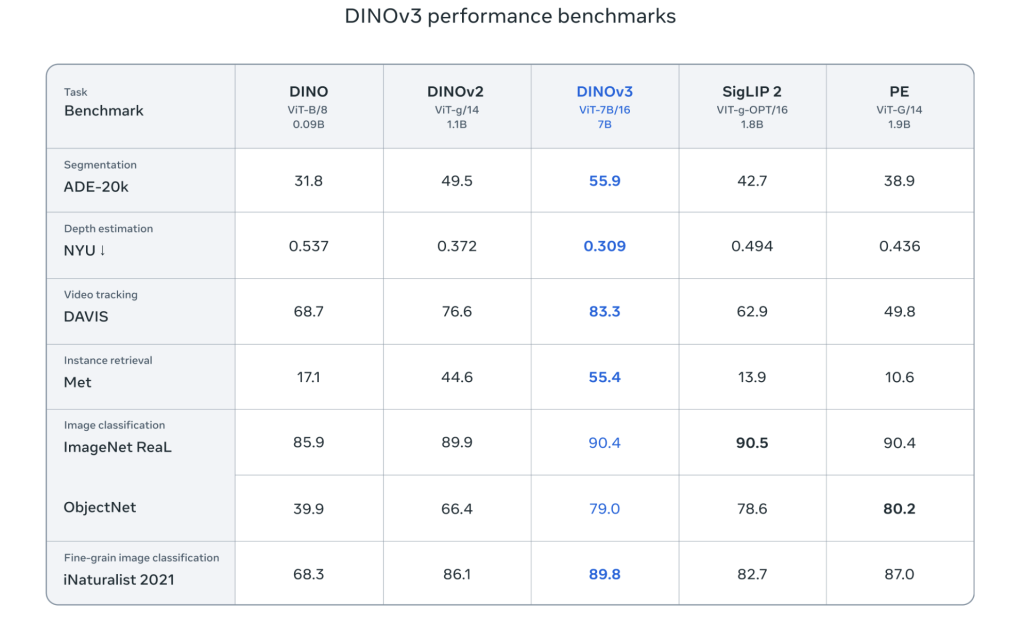
أعلنت ميتا AI مؤخراً عن إطلاق نموذجها الجديد الرائد في مجال رؤية الحاسوب، دينو v3، والذي يضع معايير جديدة للبراعة والدقة في مهام التنبؤ الكثيفة، وكل ذلك دون الحاجة إلى بيانات مُعلّمة. يعتمد دينو v3 على تقنية التعلم الذاتي الخالي من الإشراف (SSL) على نطاق غير مسبوق، حيث تم تدريبه على 1.7 مليار صورة باستخدام بنية معمارية تضم 7 مليارات بارامتر. ولأول مرة، يتفوق عمود رؤية واحد ثابت (Frozen Backbone) على الحلول المتخصصة في المجالات المختلفة عبر العديد من مهام الرؤية، مثل كشف الأجسام، والتقسيم الدلالي، وتتبع الفيديو، دون الحاجة إلى أي ضبط دقيق للتكيف.
الابتكارات والنقاط البارزة:
- التعلم الذاتي الخالي من الإشراف: تم تدريب دينو v3 بالكامل دون استخدام بيانات مُعلّمة يدوياً، مما يجعله مثاليًا للمجالات التي تفتقر فيها البيانات المُعلّمة أو تكون مكلفة، مثل صور الأقمار الصناعية، والتطبيقات الطبية الحيوية، واستشعار عن بعد.
- عمود رؤية قابل للتطوير: يتميز دينو v3 بعمود رؤية عالمي وثابت، ينتج ميزات صور عالية الدقة قابلة للاستخدام مباشرةً مع مُكيّفات خفيفة الوزن لتطبيقات متنوعة. يتفوق هذا النموذج على أفضل المعايير في كل من النماذج المتخصصة في المجالات والنماذج السابقة القائمة على التعلم الذاتي الخالي من الإشراف في المهام الكثيفة.
- متغيرات النموذج للنشر: لا تُطلق ميتا فقط عمود الرؤية الضخم ViT-G، بل تُطلق أيضاً إصدارات مُقطّرة (ViT-B، ViT-L) ومتغيرات ConvNeXt لدعم مجموعة واسعة من سيناريوهات النشر، بدءاً من الأبحاث واسعة النطاق ووصولاً إلى الأجهزة الطرفية ذات الموارد المحدودة.
- الإصدار التجاري والمفتوح المصدر: يتم توزيع دينو v3 بموجب ترخيص تجاري، بالإضافة إلى رمز التدريب والتقييم الكامل، وأعمدة الرؤية المُدرّبة مسبقاً، ومُكيّفات المهام، ودفاتر ملاحظات توضيحية لتعزيز البحث والابتكار وتكامل المنتجات التجارية.
التأثير في العالم الحقيقي:
بدأت منظمات مثل معهد الموارد العالمية (WRI) و مختبر الدفع النفاث التابع لناسا (JPL) بالفعل في استخدام دينو v3: فقد حسّن بشكل كبير دقة مراقبة الغابات (بتقليل خطأ ارتفاع مظلة الأشجار من 4.1 متر إلى 1.2 متر في كينيا) ودعم رؤية روبوتات استكشاف المريخ بأقل قدر ممكن من الحوسبة.
التعميم ونقص البيانات المُعلّمة:
باستخدام التعلم الذاتي الخالي من الإشراف على نطاق واسع، يقلص دينو v3 الفجوة بين نماذج الرؤية العامة والنماذج المتخصصة في المهام. فهو يلغي الاعتماد على التعليقات التوضيحية أو الإعدادات على الويب، مستفيداً من البيانات غير المُعلّمة للتعلم العالمي للميزات، مما يُمكّن التطبيقات في المجالات التي تعاني من نقص في البيانات المُعلّمة.
مقارنة إمكانيات دينو v3:
| الخاصية | دينو/دينو v2 | دينو v3 (جديد) |
|---|---|---|
| بيانات التدريب | حتى 142 مليون صورة | 1.7 مليار صورة |
| عدد المعلمات | حتى 1.1 مليار | 7 مليارات |
| ضبط عمود الرؤية | مطلوب | غير مطلوب |
| مهام التنبؤ الكثيفة | أداء قوي | يتفوق على المتخصصين |
| متغيرات النموذج | ViT-S/B/L/g | ViT-B/L/G, ConvNeXt |
| الإصدار المفتوح | نعم | ترخيص تجاري، مجموعة كاملة |
الخلاصة:
يمثل دينو v3 قفزة كبيرة في مجال رؤية الحاسوب: فعمود الرؤية العالمي الثابت ونهج التعلم الذاتي الخالي من الإشراف يُمكّنان الباحثين والمطورين من معالجة المهام التي تفتقر إلى البيانات المُعلّمة، ونشر نماذج عالية الأداء بسرعة، والتكيف مع مجالات جديدة ببساطة عن طريق تبديل مُكيّفات خفيفة الوزن. يتضمن إصدار ميتا كل ما هو مطلوب للاستخدام الأكاديمي أو الصناعي، مما يعزز التعاون الواسع في مجتمع الذكاء الاصطناعي ورؤية الحاسوب. تتوفر حزمة دينو v3 – النماذج والرموز – الآن للأبحاث التجارية والنشر، مما يُمثّل فصلاً جديداً لأنظمة رؤية الذكاء الاصطناعي القوية وقابلة للتطوير. يمكنكم الاطلاع على الورقة البحثية، والنماذج على Hugging Face، وصفحة GitHub.




اترك تعليقاً