
تقليل بيانات تدريب نماذج اللغة الكبيرة بمقدار 10,000 ضعف: ثورة جوجل في تعلم الآلة
أعلنت جوجل مؤخراً عن طريقة ثورية لضبط نماذج اللغات الكبيرة (LLMs)، مما يقلل من كمية بيانات التدريب المطلوبة بمقدار يصل إلى 10,000 ضعف، مع الحفاظ على جودة النموذج أو حتى تحسينها. تعتمد هذه الطريقة على تقنية “التعلم النشط” (Active Learning)، حيث تركز جهود وضع العلامات من قبل الخبراء على الأمثلة الأكثر إفادة، وهي “حالات الحد” التي تصل فيها عدم يقين النموذج إلى ذروته.
التحديات التقليدية في ضبط نماذج اللغات الكبيرة
عادةً ما يتطلب ضبط نماذج اللغات الكبيرة للمهام التي تتطلب فهماً سياقياً وثقافياً عميقاً – مثل سلامة محتوى الإعلانات أو عملية الإشراف عليها – مجموعات بيانات ضخمة وعالية الجودة. معظم البيانات حميدة، مما يعني أنه بالنسبة لاكتشاف انتهاكات السياسات، لا تهم إلا نسبة صغيرة من الأمثلة، مما يزيد من تكلفة وتعقيد عملية إعداد البيانات. كما أن الأساليب القياسية تكافح للحفاظ على مستوى الأداء عندما تتغير السياسات أو الأنماط الإشكالية، مما يتطلب إعادة تدريب مكلفة.
إنجاز جوجل في التعلم النشط: كيف تعمل هذه التقنية؟
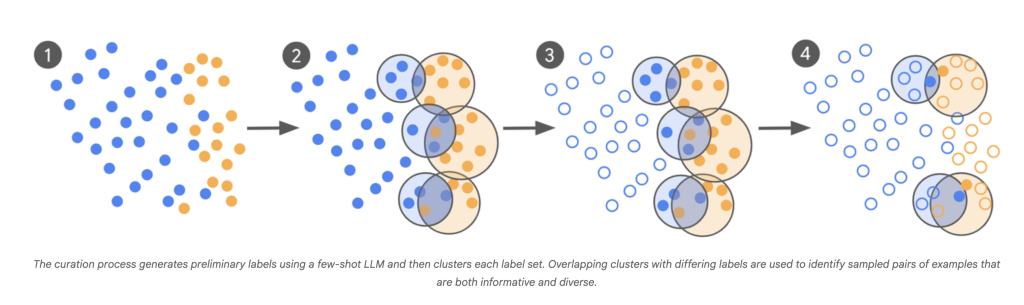
تعتمد هذه الطريقة على الخطوات التالية:
- النموذج ككشاف (LLM-as-Scout): يستخدم نموذج اللغة الكبير لفحص مجموعة ضخمة من البيانات (مئات المليارات من الأمثلة) وتحديد الحالات التي يكون فيها أقل يقيناً.
- وضع علامات مستهدفة من قبل الخبراء: بدلاً من وضع علامات على آلاف الأمثلة العشوائية، يقوم الخبراء البشريون بوضع علامات فقط على تلك العناصر الحدودية والمحيرة.
- إعداد البيانات بشكل متكرر: تتكرر هذه العملية، مع إعلام كل دفعة جديدة من الأمثلة “الإشكالية” بنقاط الارتباك في النموذج الأخير.
- التقارب السريع: يتم ضبط النماذج بشكل دقيق في جولات متعددة، وتستمر عملية التكرار حتى يتوافق مخرجات النموذج بشكل وثيق مع حكم الخبراء – يقاس ذلك باستخدام معامل كوهين كابا (Cohen’s Kappa)، والذي يقارن الاتفاق بين المراجعين بما يتجاوز الصدفة.
أثر هذه التقنية
- انخفاض احتياجات البيانات بشكل كبير: في التجارب التي أجريت على نماذج Gemini Nano-1 و Nano-2، وصل التوافق مع الخبراء البشريين إلى مستوى التكافؤ أو أفضل باستخدام 250-450 مثالاً مختاراً بعناية بدلاً من حوالي 100,000 علامة عشوائية تم جمعها من مصادر متعددة – وهو انخفاض بمقدار ثلاثة إلى أربعة أوامر من حيث الحجم.
- ارتفاع جودة النموذج: بالنسبة للمهام الأكثر تعقيداً والنماذج الأكبر، وصلت تحسينات الأداء إلى 55-65٪ مقارنة بالأساس، مما يدل على توافق أكثر موثوقية مع خبراء السياسات.
- كفاءة وضع العلامات: لتحقيق مكاسب موثوقة باستخدام مجموعات بيانات صغيرة، كانت جودة العلامات العالية ضرورية باستمرار (معامل كوهين كابا > 0.8).
أهمية هذه الطريقة
تقلب هذه الطريقة النموذج التقليدي. فبدلاً من إغراق النماذج في كميات هائلة من البيانات الضوضاء والمتكررة، فإنها تستفيد من قدرة نماذج اللغات الكبيرة على تحديد الحالات الغامضة، ومن خبرة الخبراء البشريين حيث تكون مدخلاتهم ذات قيمة أكبر. الفوائد هائلة:
- خفض التكاليف: عدد أقل بكثير من الأمثلة التي يجب وضع علامات عليها، مما يقلل بشكل كبير من نفقات العمل ورأس المال.
- التحديثات الأسرع: القدرة على إعادة تدريب النماذج على عدد قليل من الأمثلة تجعل التكيف مع أنماط الاستخدام الجديدة أو تغييرات السياسات أو التحولات المجالية سريعاً وممكناً.
- الأثر المجتمعي: القدرة المحسنة على الفهم السياقي والثقافي تزيد من سلامة وموثوقية الأنظمة الآلية التي تعالج المحتوى الحساس.
الخلاصة
تمكن منهجية جوجل الجديدة من ضبط نماذج اللغات الكبيرة على المهام المعقدة والمتطورة باستخدام مئات (وليس مئات الآلاف) من العلامات المستهدفة عالية الدقة، مما يمهد الطريق لتطوير نماذج أكثر رشاقة وسرعة وكفاءة من حيث التكلفة. يمكنكم الاطلاع على المقالة التقنية من مدونة جوجل.





اترك تعليقاً