
إتقان نماذج اللغات الكبيرة باستخدام MCP-RL و ART: غوص عميق في التقنية
يُمثل تمكين نماذج اللغات الكبيرة (LLMs) من التفاعل بسلاسة مع بيئات العالم الحقيقي الديناميكية آفاقًا جديدة في هندسة الذكاء الاصطناعي. يوفر بروتوكول سياق النموذج (MCP) بوابة موحدة تسمح لـ LLMs بالتفاعل مع أنظمة خارجية عشوائية -واجهات برمجة التطبيقات، ونظم الملفات، وقواعد البيانات، والتطبيقات، أو الأدوات- دون الحاجة إلى كتابة شفرة لاصقة مخصصة أو اختراقات تعليمات خاطئة كل مرة. ومع ذلك، لا يزال الاستفادة من هذه الأدوات برمجيًا، مع استدلال قوي عبر مهام متعددة الخطوات، تحديًا هائلاً. هنا يأتي دور المزيج الأخير من MCP-RL (حلقة تعلم تقوية تستهدف خوادم MCP) ومكتبة ART (مدرب تعزيز العامل) مفتوحة المصدر، ليحدثا نقلة نوعية: يمكنك الآن امتلاك وكيل يستكشف، ويتخصص، ويحسن ذاته لأي خدمة MCP بحد أدنى من التصميم البشري، بدون بيانات مُعلّمة، وبموثوقية متقدمة. ستوضح هذه المقالة آليات العمل الدقيقة، ومسارات التنفيذ، والتعقيدات التقنية -حتى مستوى الكود- لهذا النظام.
ما هو MCP-RL؟
MCP-RL هو بروتوكول تدريب ميتا مصمم للسماح لأي وكيل LLM بالتعلم، من خلال تعلم التعزيز (RL)، لتشغيل مجموعة الأدوات التي تعرضها خادم MCP. يُعد MCP-RL جزءًا من مشروع Agent Reinforcement Trainer (ART). بإعطاء عنوان URL للخادم فقط:
- يستعرض الوكيل الخادم، ويكتشف تلقائيًا الأدوات المتاحة (الدوال، واجهات برمجة التطبيقات، نقاط النهاية) مع مخططاتها.
- يتم تصميم المهام الاصطناعية على الفور ليشمل استخدامات الأدوات المتنوعة.
- يُقيّم نظام التسجيل النسبي (RULER) أداء الوكيل، حتى بدون بيانات ذهبية مُعلّمة، على كل مسار.
- يتم ضبط الوكيل بشكل متكرر لتحقيق أقصى قدر من نجاح المهمة.
هذا يعني أن LLM يمكنه اكتساب الكفاءة على أي خادم مدعوم بالأدوات المطابقة -واجهات برمجة تطبيقات للطقس، وقواعد بيانات، وبحث الملفات، وإصدار التذاكر، إلخ- فقط من خلال توجيه MCP-RL إلى نقطة النهاية الصحيحة.
ART: مدرب تعزيز العامل
يوفر ART (مدرب تعزيز العامل) خط أنابيب RL المُنسّق الأساسي لـ MCP-RL، ويدعم معظم النماذج المتوافقة مع vLLM/HuggingFace (مثل Qwen2.5، Qwen3، Llama، Kimi) وبيئة حوسبة موزعة أو محلية. تم تصميم ART مع:
- فصل العميل/الخادم: يتم فصل الاستنتاج وتدريب RL؛ يمكن تشغيل الوكلاء من أي عميل بينما يتم نقل التدريب تلقائيًا.
- التكامل السهل: تدخل ضئيل في قواعد البيانات الحالية؛ فقط قم بربط عميل ART بحلقة تمرير الرسائل الخاصة بـ وكيلك.
- خوارزمية GRPO: نهج مُحسّن لضبط RL الدقيق من أجل الاستقرار وكفاءة التعلم، مع الاستفادة من LoRA و vLLM للنشر القابل للتطوير.
- لا حاجة لبيانات مُعلّمة: تحل السيناريوهات الاصطناعية ونظام المكافآت النسبية (RULER) محل مجموعات البيانات المصممة يدويًا بالكامل.
استعراض الشفرة: تخصص LLMs باستخدام MCP-RL
يكمن جوهر سير العمل في مقتطف الشفرة التالي من وثائق ART:
from art.rewards import ruler_score_group
# تحديد عنوان URL لخادم MCP (مثال: خدمة الطقس الوطنية)
MCP_SERVER_URL = "https://server.smithery.ai/@smithery-ai/national-weather-service/mcp"
# توليد دفعة من السيناريوهات الاصطناعية التي تغطي أدوات الخادم
scenarios = await generate_scenarios(num_scenarios=24, server_url=MCP_SERVER_URL)
# تشغيل عمليات نشر الوكيل بالتوازي، وجمع مسارات الاستجابة
# كل مسار = (رسائل النظام، المستخدم، المساعد...)
# تعيين المكافآت لكل مجموعة باستخدام التسجيل النسبي لـ RULER
scored_groups = []
for group in groups:
judged_group = await ruler_score_group(group)
scored_groups.append(judged_group)
# إرسال المسارات المجمعة لضبط RL الدقيق (GRPO)
await model.train(scored_groups)شرح:
- توليد السيناريوهات: لا حاجة لمهام مصممة يدويًا.
generate_scenariosتقوم بتصميم تلقائي لمطالبات/مهام متنوعة بناءً على الأدوات المكتشفة من خادم MCP. - تنفيذ النشر: يعمل الوكيل، ويستدعي مكالمات الأدوات عبر MCP، ويحصل على مسارات لاستخدام الأدوات خطوة بخطوة والمخرجات.
- تسجيل RULER: بدلاً من مكافأة ثابتة، يستخدم RULER التقييم النسبي داخل كل دفعة لقياس المكافآت تلقائيًا، مع معالجة الصعوبة المتغيرة وجدة المهمة بشكل قوي.
- حلقة التدريب: يتم إرسال دفعات من المسارات والمكافآت إلى خادم ART، حيث يتم إعادة تدريب محولات LoRA بشكل تدريجي باستخدام خوارزمية تدرج السياسات GRPO. تتكرر الحلقة -تجعل كل دورة الوكيل أكثر كفاءة في دمج أدوات الخادم لحل المهام الاصطناعية.
تحت الغطاء: كيف يُعمّم MCP-RL
- اكتشاف الأدوات: تعرض واجهة MCP عادةً مخططات متوافقة مع OpenAPI، والتي يقوم الوكيل بتحليلها لسرد جميع الإجراءات القابلة للاتصال وتوقيعاتها -بدون افتراضات حول تفاصيل المجال.
- توليد السيناريوهات: يمكن استخدام قوالب أو مطالبات نموذج لغة قليلة اللقطات لبدء المهام التي تقتبس الاستخدامات التمثيلية (تركيبات واجهة برمجة التطبيقات الذرية أو المعقدة).
- المُلاحظات بدون بيانات ذهبية: يتمثل ابتكار RULER في المقارنة بين الدُفعات، مما يعطي درجات أعلى للسلوكيات الأكثر نجاحًا داخل المجموعة الحالية -هذا يتكيف ذاتيًا عبر المهام الجديدة أو البيئات الصاخبة.
- الجسر من المهام الاصطناعية إلى المهام الحقيقية: بمجرد أن يصبح الوكيل بارعًا في المهام المُنشأة، فإنه يُعمّم على متطلبات المستخدم الفعلية، نظرًا لأن تغطية استخدام الأدوات مصممة لتكون واسعة وقابلة للجمع.
التأثير في العالم الحقيقي والمعايير
- إعداد بسيط: قابل للنشر مع أي خادم MCP -فقط نقطة النهاية، بدون كود داخلي أو وصول مطلوب.
- غرض عام: يمكن تدريب الوكلاء على استخدام مجموعات أدوات عشوائية -الطقس، وتحليل الشفرة، وبحث الملفات، إلخ.
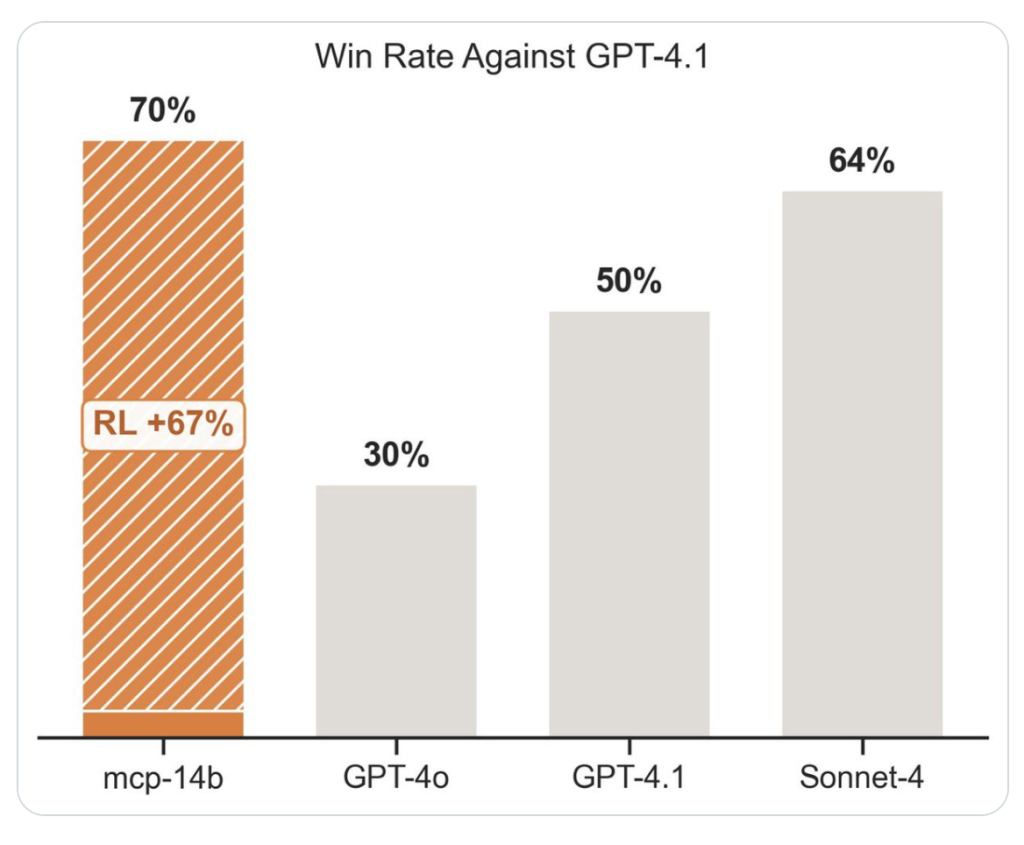
- نتائج متقدمة: مطابقة أو تفوقت على خطوط أساس وكلاء متخصصين في 2/3 من المعايير العامة.
- صفر بيانات مُعلّمة: يوفر النهج مسارًا قابلًا للتطوير لـ RL الوكيل في الوقت الفعلي، قابل للتطبيق حتى عندما يكون من المستحيل الحصول على عروض توضيحية من الخبراء.
نظرة عامة على البنية
| المكون | الوصف |
|---|---|
| عميل ART | ينسق عمليات نشر الوكيل، يرسل/يستقبل الرسائل، دفعات المكافآت |
| خادم ART | يتعامل مع الاستنتاج وحلقة تدريب RL، يدير نقاط تفتيش LoRA |
| خادم MCP | يعرض مجموعة الأدوات، التي يستفسر عنها الوكيل أثناء كل مهمة |
| محرك السيناريو | يُنشئ تلقائيًا مطالبات مهام متنوعة اصطناعية |
| مُقيّم RULER | تعيين مكافأة نسبية لكل مجموعة من المسارات |
التكامل العملي
- التثبيت:
pip install openpipe-art - المرونة: يعمل ART مع الحوسبة المحلية أو السحابية، عبر vLLM أو الخلفيات المتوافقة.
- أدوات التصحيح: مدمج مع W&B، Langfuse، OpenPipe للملاحظة.
- إمكانية التخصيص: يمكن للمستخدمين المتقدمين ضبط توليد السيناريوهات، وتشكيل المكافآت، وأحجام الدُفعات، وتكوينات LoRA.
الخلاصة
يُلغي مزيج MCP-RL و ART سنوات من تصميم أتمتة RL، مما يسمح لك بتحويل أي LLM إلى وكيل يستخدم الأدوات، ويُحسّن ذاته، وهو مستقل عن المجال وبدون بيانات تدريب مُعلّمة. سواء كانت بيئتك واجهات برمجة تطبيقات عامة أو خوادم مؤسسية مخصصة، يتعلم الوكيل أثناء العمل ويحقق أداءً قابلاً للتطوير وقويًا. للمزيد من التفاصيل، ودفاتر ملاحظات الأمثلة العملية، والمعايير المُحدّثة، تفضل بزيارة مستودع ART وأمثلة التدريب الخاصة بـ [MCP-RL].
مواضيع مشابهة:
 دليل برمجي خطوة بخطوة لدمج أدوات البحث والتوصية في الوقت الحقيقي من Dappier AI مع واجهة برمجة تطبيقات دردشة OpenAI
من إليزا إلى نمذجة المحادثة: تطور أنظمة وباراديغمات الذكاء الاصطناعي المحادثي
دليل برمجي خطوة بخطوة لدمج أدوات البحث والتوصية في الوقت الحقيقي من Dappier AI مع واجهة برمجة تطبيقات دردشة OpenAI
من إليزا إلى نمذجة المحادثة: تطور أنظمة وباراديغمات الذكاء الاصطناعي المحادثي
 أداة Llama Prompt Ops: تحسين استجابات نماذج Llama بسهولة
أداة Llama Prompt Ops: تحسين استجابات نماذج Llama بسهولة
 هل يمكن الكشف الآلي عن الهلوسة في نماذج اللغات الكبيرة؟ دراسة نظرية وتطبيقية
هل يمكن الكشف الآلي عن الهلوسة في نماذج اللغات الكبيرة؟ دراسة نظرية وتطبيقية



اترك تعليقاً