نموذج VaultGemma: ثورة جوجل في الذكاء الاصطناعي الخاص
قدم فريق جوجل للذكاء الاصطناعي و DeepMind مؤخراً نموذج اللغة الكبير VaultGemma 1B، وهو الأكبر من نوعه مفتوح المصدر تم تدريبه بالكامل باستخدام الخصوصية التفاضلية (DP). يمثل هذا التطور خطوة رئيسية نحو بناء نماذج ذكاء اصطناعي قوية وفي نفس الوقت تحافظ على خصوصية البيانات.
لماذا نحتاج إلى الخصوصية التفاضلية في نماذج اللغات الكبيرة؟
تُعاني نماذج اللغات الكبيرة المدربة على مجموعات بيانات ضخمة من هجمات الحفظ، حيث يمكن استخراج معلومات حساسة أو معلومات شخصية قابلة للتعريف من النموذج. وقد أظهرت الدراسات أن بيانات التدريب الحرفية قد تعود للظهور، خاصة في الإصدارات مفتوحة المصدر. توفر الخصوصية التفاضلية ضمانًا رياضيًا يمنع أي مثال تدريب واحد من التأثير بشكل كبير على النموذج. وعلى عكس الأساليب التي تطبق الخصوصية التفاضلية فقط أثناء عملية ضبط النموذج الدقيق، يضمن VaultGemma التدريب الخاص الكامل، مما يضمن حماية الخصوصية من البداية.
بنية نموذج VaultGemma
يشبه VaultGemma من الناحية المعمارية نماذج Gemma السابقة، ولكنه مُحسّن للتدريب الخاص. تتميز مواصفاته بما يلي:
- حجم النموذج: 1 مليار معلمة، 26 طبقة.
- نوع المحول: مُشفّر فقط (Decoder-only).
- الدوال التنشيطية: GeGLU مع بعد تغذية أمامية (Feedforward dimension) يبلغ 13,824.
- الانتباه: انتباه متعدد الاستعلامات (MQA) مع نطاق عالمي (Global span) يبلغ 1024 رمزًا.
- التطبيع: RMSNorm في تكوين ما قبل التطبيع (Pre-norm).
- أداة تقسيم الكلمات: SentencePiece مع قاموس (Vocabulary) يتكون من 256 ألف رمز.
يُلاحظ تغييرًا هامًا يتمثل في تقليل طول التسلسل إلى 1024 رمزًا، مما يقلل من تكاليف الحوسبة ويُمكّن من استخدام أحجام دفعات أكبر ضمن قيود الخصوصية التفاضلية.
بيانات التدريب المستخدمة
تم تدريب VaultGemma على نفس مجموعة البيانات التي تحتوي على 13 تريليون رمز المستخدمة في Gemma 2، والتي تتكون بشكل أساسي من نصوص إنجليزية من مستندات الويب، والرموز، والمقالات العلمية. خضعت مجموعة البيانات لعدة مراحل تصفية ل:
- إزالة المحتوى غير الآمن أو الحساس.
- تقليل تعرض المعلومات الشخصية.
- منع تلوث بيانات التقييم.
هذا يضمن السلامة والإنصاف في عملية قياس الأداء.
تطبيق الخصوصية التفاضلية
استخدم VaultGemma خوارزمية DP-SGD (الهبوط التدريجي العشوائي الخاص بالخصوصية التفاضلية) مع قصّ التدرجات (Gradient clipping) وإضافة ضوضاء غاوسية. تم بناء التنفيذ على JAX Privacy وأدخلت تحسينات لتحقيق قابلية التوسع:
- قصّ لكل مثال بشكل متجهي لتحقيق كفاءة متوازية.
- تراكم التدرجات لمحاكاة دفعات كبيرة.
- أخذ عينات فرعية من بواسون المختصر (Truncated Poisson Subsampling) مدمج في مُحمّل البيانات لأخذ عينات فعّالة أثناء التنفيذ.
حقق النموذج ضمانًا رسميًا للخصوصية التفاضلية (ε ≤ 2.0، δ ≤ 1.1e−10) على مستوى التسلسل (1024 رمزًا).
قوانين التوسع للتدريب الخاص
يتطلب تدريب نماذج كبيرة تحت قيود الخصوصية التفاضلية استراتيجيات توسع جديدة. قام فريق VaultGemma بتطوير قوانين توسع خاصة بالخصوصية التفاضلية مع ثلاثة ابتكارات:
- نمذجة معدل التعلم الأمثل باستخدام الملاءمة التربيعية عبر عمليات التدريب.
- استقراء بارامتري لقيم الخسارة لتقليل الاعتماد على نقاط التفتيش الوسيطة.
- ملاءمة شبه بارامترية للتعميم عبر حجم النموذج وخطوات التدريب ونسب الضوضاء/الدفعات.
مكنت هذه المنهجية من التنبؤ الدقيق بالخسارة التي يمكن تحقيقها واستخدام الموارد بكفاءة على مجموعة معالجات TPUv6e.
إعدادات التدريب
تم تدريب VaultGemma على 2048 شريحة TPUv6e باستخدام تقسيم GSPMD وتجميع MegaScale XLA. كانت إعدادات التدريب كما يلي:
- حجم الدفعة: ~518 ألف رمز.
- تكرارات التدريب: 100,000.
- مضاعف الضوضاء: 0.614.
كانت الخسارة المُحَقّقة ضمن 1% من التوقعات من قانون التوسع الخاص بالخصوصية التفاضلية، مما يُثبت صحة هذا النهج.
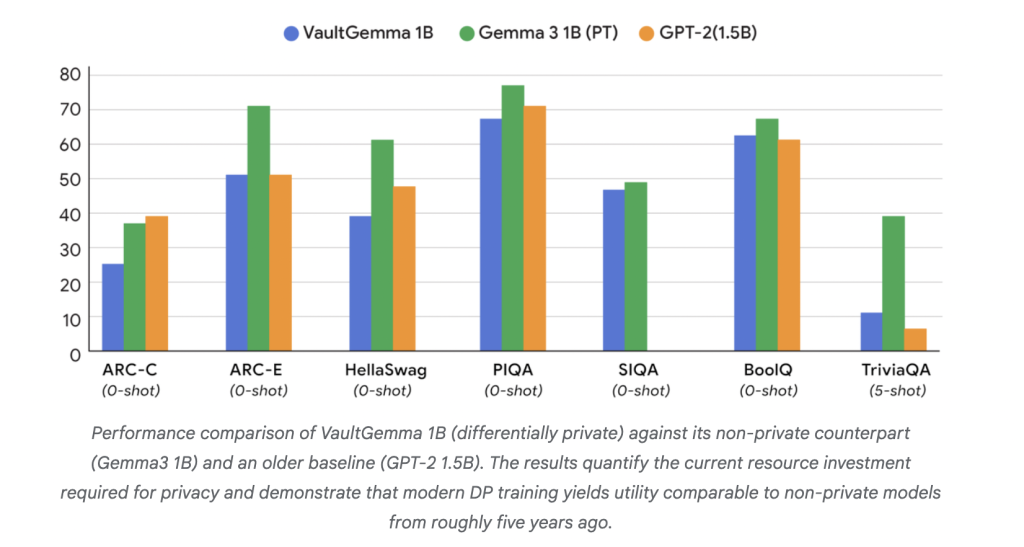
أداء VaultGemma مقارنة بالنماذج غير الخاصة
على مقاييس الأداء الأكاديمية، يتأخر VaultGemma عن نظرائه غير الخاصة ولكنه يُظهر فائدة قوية:
- ARC-C: 26.45 مقابل 38.31 (Gemma-3 1B).
- PIQA: 68.0 مقابل 70.51 (GPT-2 1.5B).
- TriviaQA (5-shot): 11.24 مقابل 39.75 (Gemma-3 1B).
تشير هذه النتائج إلى أن النماذج المدربة باستخدام الخصوصية التفاضلية قابلة للمقارنة حاليًا مع النماذج غير الخاصة من حوالي خمس سنوات مضت. والأهم من ذلك، أكدت اختبارات الحفظ عدم وجود تسرب بيانات تدريب يمكن اكتشافه في VaultGemma، على عكس نماذج Gemma غير الخاصة.
الخلاصة
يُثبت VaultGemma 1B أن نماذج اللغات الكبيرة يمكن تدريبها بضمانات صارمة للخصوصية التفاضلية دون جعلها غير عملية للاستخدام. بينما لا تزال هناك فجوة في الفائدة مقارنة بنظيراتها غير الخاصة، فإن إصدار كل من النموذج ومنهجية تدريبه يوفر للمجتمع أساسًا قويًا لتطوير الذكاء الاصطناعي الخاص. يُشير هذا العمل إلى تحول نحو بناء نماذج ليست فقط قادرة، بل آمنة وشفافة وتحافظ على الخصوصية بشكل جوهري.






اترك تعليقاً