نموذج Step-Audio 2 Mini مفتوح المصدر: ثورة في معالجة الصوت بتفوقه على GPT-4o-Audio
أعلنت شركة StepFun AI مؤخراً عن إطلاق نموذجها الجديد Step-Audio 2 Mini، وهو نموذج لغوي ضخم مفتوح المصدر (LALM) يضم 8 مليارات بارامتر، متخصص في معالجة الصوت من خلال تحويل الكلام إلى كلام. يتميز هذا النموذج بتفاعله الصوتي الواقعي، المعبر، والفعال في الوقت الحقيقي، متجاوزاً بذلك أنظمة تجارية رائدة مثل GPT-4o-Audio. تم إصدار النموذج تحت ترخيص Apache 2.0، مما يجعله متاحاً للاستخدام والتطوير من قبل الجميع.
المزايا الرئيسية لـ Step-Audio 2 Mini:
-
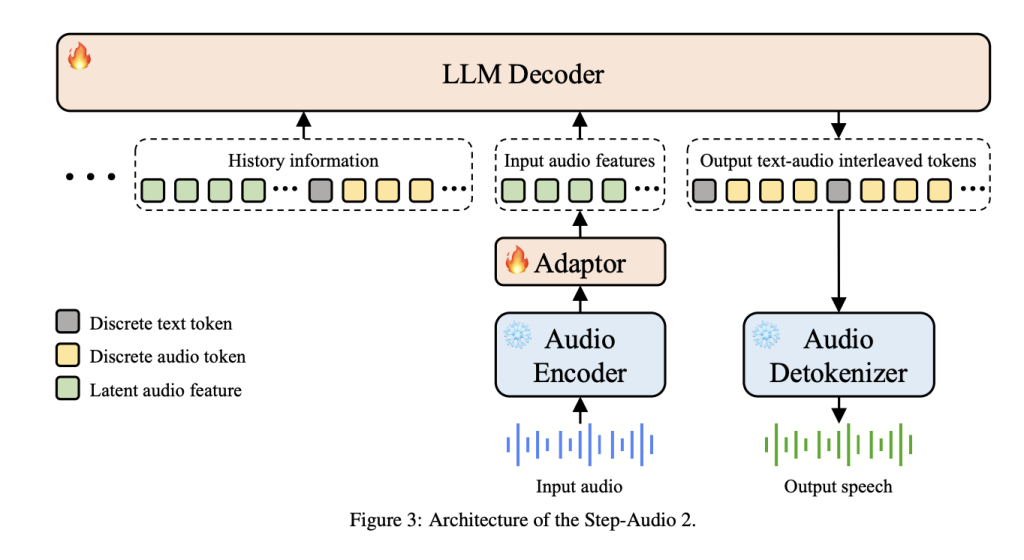
توحيد ترميز الصوت والنص: على عكس أنابيب معالجة الكلام التقليدية (ASR+LLM+TTS)، يدمج Step-Audio 2 Mini نموذجاً متعدد الوسائط للرموز المنفصلة، حيث يشترك كل من رموز النص والصوت في تيار نمذجة واحد. هذا يسمح ب:
- استنتاج سلس بين النص والصوت.
- تغيير أسلوب الصوت أثناء الاستنتاج.
- اتساق في المخرجات الدلالية، الصوتية، والعاطفية.
-
توليد معبر وواعٍ للعواطف: لا يقتصر النموذج على نسخ الكلام فقط، بل يفسر أيضاً خصائص صوتية مثل النبرة، الإيقاع، العاطفة، الصوت، والأسلوب. هذا يسمح بإجراء محادثات بنغمات عاطفية واقعية مثل الهمس، الحزن، أو الحماس. أظهرت اختبارات StepEval-Audio-Paralinguistic أن Step-Audio 2 Mini حقق دقة 83.1٪، متفوقاً بشكل كبير على GPT-4o Audio (43.5٪) و Qwen-Omni (44.2٪).
-
توليد الكلام المعزز بالاسترجاع: يدمج Step-Audio 2 Mini تقنية الاسترجاع المعزز متعدد الوسائط (RAG):
- تكامل البحث على الويب لتثبيت الحقائق.
- البحث الصوتي – وهي قدرة جديدة تسترجع الأصوات الحقيقية من مكتبة كبيرة وتدمجها في الردود، مما يسمح بتقليد صوت/أسلوب المتحدث أثناء الاستنتاج.
-
استدعاء الأدوات والاستنتاج متعدد الوسائط: يتجاوز النظام توليف الكلام من خلال دعم استدعاء الأدوات. تُظهر الاختبارات أن Step-Audio 2 Mini يضاهي نماذج اللغات الضخمة النصية في اختيار الأدوات ودقة المعلمات، بينما يتفوق بشكل فريد في استدعاءات أدوات البحث الصوتي – وهي قدرة غير متوفرة في نماذج اللغات الضخمة النصية فقط.
التدريب والبيانات:
- مجموعة بيانات نصوص + صوت: 1.356 تريليون رمز
- ساعات صوت: أكثر من 8 ملايين ساعة من الصوت الحقيقي والاصطناعي
- تنوع المتحدثين: حوالي 50 ألف صوت من مختلف اللغات واللهجات
- خط أنابيب التدريب: منهج تدريبي متعدد المراحل يشمل التعرف على الكلام، توليف الكلام، الترجمة الصوتية، وتوليف المحادثات الموصوفة عاطفياً.
مقاييس الأداء:
-
التعرف على الكلام (ASR):
- الإنجليزية: متوسط معدل خطأ الكلمات (WER) 3.14٪ (يتفوق على GPT-4o Transcribe بمتوسط 4.5٪).
- الصينية: متوسط معدل خطأ الأحرف (CER) 3.08٪ (أقل بكثير من GPT-4o و Qwen-Omni). متين عبر اللهجات واللهجات المختلفة.
-
فهم الصوت (MMAU Benchmark):
- Step-Audio 2: متوسط 78.0، متفوقاً على Omni-R1 (77.0) و Audio Flamingo 3 (73.1). أقوى في مهام الاستدلال الصوتي والكلامي.
-
الترجمة الصوتية:
- CoVoST 2 (S2TT): BLEU 39.26 (الأعلى بين النماذج المفتوحة والمغلقة).
- CVSS (S2ST): BLEU 30.87، متقدماً على GPT-4o (23.68).
-
المقاييس المحادثة (URO-Bench):
- المحادثات الصينية: الأفضل بشكل عام بـ 83.3 (أساسي) و 68.2 (محترف).
- المحادثات الإنجليزية: تنافسية مع GPT-4o (83.9 مقابل 84.5)، متقدمة بشكل كبير على النماذج المفتوحة الأخرى.
الخلاصة:
يُتيح Step-Audio 2 Mini إمكانية الوصول إلى تقنيات معالجة الصوت المتقدمة والمتعددة الوسائط للمطورين وباحثين. من خلال دمج قدرة Qwen2-Audio على الاستدلال مع خط أنابيب ترميز CosyVoice، وتعزيزها بالاسترجاع القائم على التأسيس، قدمت StepFun أحد أكثر نماذج اللغات الضخمة الصوتية المفتوحة قدرة. يمكنكم الاطلاع على الورقة البحثية والنموذج على Hugging Face.
مواضيع مشابهة:
 بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه
بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه



اترك تعليقاً