نموذج لغة كبير بدون مشاركة البيانات: فلِكس أولمو يُثبت إمكانية ذلك
يُعَد تطوير نماذج اللغات الكبيرة (LLMs) عمليةً تتطلب تاريخيًا الوصول المركزي إلى مجموعات بيانات واسعة، وكثير منها حساس أو محمي بحقوق الطبع والنشر أو يخضع لقيود في الاستخدام. يُحد هذا القيد بشدة من مشاركة المنظمات الغنية بالبيانات التي تعمل في بيئات خاضعة للتنظيم أو بيئات خاصة. يُقدّم فلِكس أولمو – الذي طوره باحثون في معهد ألين للذكاء الاصطناعي ومتعاونون – إطارًا مُدرّجًا للتدريب والاستنتاج يُمكّن من تطوير نماذج LLMs تحت قيود إدارة البيانات.
تحديات نماذج اللغات الكبيرة التقليدية
تعتمد خطوط أنابيب تدريب نماذج LLMs الحالية على تجميع جميع بيانات التدريب في مجموعة بيانات واحدة، مما يفرض قرارًا ثابتًا بشأن الإدراج ويستبعد إمكانية الانسحاب بعد التدريب. هذا النهج غير متوافق مع:
- الأنظمة التنظيمية: (مثل HIPAA، GDPR، قوانين سيادة البيانات).
- مجموعات البيانات المرخصة: (مثل مجموعات البيانات غير التجارية أو مجموعات البيانات التي تخضع لقيود في الإسناد).
- البيانات الحساسة للسياق: (مثل شفرة المصدر الداخلية، والسجلات الطبية).
فلِكس أولمو: حلٌّ مبتكر
يُعالج فلِكس أولمو هدفين رئيسيين:
- التدريب اللامركزي والمدمج: السماح بتدريب وحدات مستقلة على مجموعات بيانات منفصلة مُخزّنة محليًا.
- المرونة في وقت الاستنتاج: تمكين آليات اختيارية حتمية للانضمام/الانسحاب لمساهمات مجموعة البيانات دون إعادة تدريب.
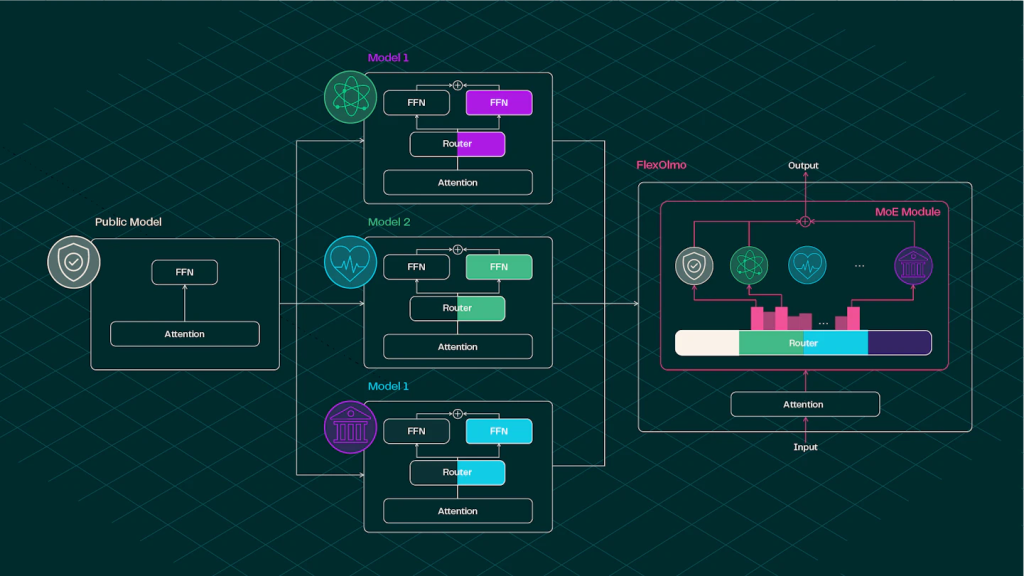
بنية النموذج: الوحدات الخبيرة عبر خليط الخبراء (MoE)
يعتمد فلِكس أولمو على بنية “خليط الخبراء” (MoE)، حيث تتوافق كل وحدة خبيرة مع وحدة شبكة تغذية أمامية (FFN) مُدرّبة بشكل مستقل. يُستخدم نموذج عام ثابت (يُشار إليه بـ Mpub) كمرساة مشتركة. يُدرّب كل مالك بيانات وحدة خبيرة Mi باستخدام مجموعة البيانات الخاصة به Di، بينما تظل جميع طبقات الانتباه وغيرها من المعلمات غير الخبيرة مجمدة.
المكونات المعمارية الرئيسية:
- التنشيط المتناثر: يتم تنشيط مجموعة فرعية فقط من وحدات الخبراء لكل رمز إدخال.
- توجيه الخبراء: يتم التحكم في تعيين الرمز للخبير بواسطة مصفوفة توجيه مُشتقة من تضمينات مُستقاة من المجال، مما يلغي الحاجة للتدريب المشترك.
- تنظيم التحيز: يتم إدخال حد تحيز سلبي لمعايرة الاختيار عبر الخبراء المُدرّبين بشكل مستقل، مما يمنع الإفراط في اختيار أي خبير واحد.
يُحافظ هذا التصميم على التشغيل البيني بين الوحدات مع تمكين الإدراج الانتقائي أثناء الاستنتاج.
التحسين غير المتزامن والمعزول
يتم تدريب كل وحدة خبيرة Mi عبر إجراء مُقيّد لضمان المحاذاة مع Mpub. على وجه التحديد:
- يتم إجراء التدريب على مثيل هجين من MoE يتضمن Mi و Mpub.
- يتم تجميد وحدة الخبير Mpub وطبقات الانتباه المُشتركة.
- يتم تحديث شبكات FFNs التي تتوافق مع Mi وتضمينات الموجه ri فقط.
- لتهيئة ri، يتم تضمين مجموعة من العينات من Di باستخدام مُشفّر مُدرّب مسبقًا، ويشكّل متوسطها تضمين الموجه. يمكن أن يُحسّن الضبط الخفيف الاختياري للموجه الأداء باستخدام بيانات وسيطة من مجموعة البيانات العامة.
بناء مجموعة البيانات: FLEXMIX
تُقسم مجموعة بيانات التدريب، FLEXMIX، إلى:
- مزيج عام: يتكون من بيانات الويب العامة.
- سبع مجموعات مغلقة: تُحاكي مجالات غير قابلة للمشاركة: الأخبار، ريديت، الشفرة، النصوص الأكاديمية، النصوص التعليمية، الكتابة الإبداعية، والرياضيات.
يتم تدريب كل خبير على مجموعة فرعية منفصلة، دون وجود وصول مشترك للبيانات. يُقارب هذا الإعداد الاستخدام في العالم الحقيقي حيث لا تستطيع المنظمات تجميع البيانات بسبب القيود القانونية أو الأخلاقية أو التشغيلية.
التقييم ومقارنات الأساس
تم تقييم فلِكس أولمو على 31 مهمة قياسية عبر 10 فئات، بما في ذلك فهم اللغة العامة (مثل MMLU، AGIEval)، و(QA) التوليدي (مثل GEN5)، وتوليد الشفرة (مثل Code4)، والتفكير الرياضي (مثل Math2).
تتضمن أساليب الأساس:
- حساء النموذج: حساب متوسط أوزان النماذج المُحسّنة بشكل فردي.
- Branch-Train-Merge (BTM): تجميع مُرجّح لاحتمالات الإخراج.
- BTX: تحويل النماذج الكثيفة المُدرّبة بشكل مستقل إلى MoE عبر زرع المعلمات.
- التوجيه القائم على المطالبات: استخدام مُصنّفات مُدرّبة على التعليمات لتوجيه الاستعلامات إلى الخبراء.
مقارنةً بهذه الأساليب، حقق فلِكس أولمو:
- تحسينًا نسبيًا متوسطًا بنسبة 41٪ على النموذج العام الأساسي.
- تحسينًا بنسبة 10.1٪ على أقوى أساسيات الدمج (BTM).
تُلاحظ المكاسب بشكل خاص في المهام المُتوافقة مع المجالات المغلقة، مما يؤكد فائدة الخبراء المتخصصين.
التحليل المعماري
تكشف العديد من التجارب المُتحكمة عن مساهمة القرارات المعمارية:
- يؤدي إزالة التنسيق بين الخبير والعام أثناء التدريب إلى انخفاض الأداء بشكل كبير.
- تُقلل تضمينات الموجه المُهيأة عشوائيًا من الفصل بين الخبراء.
- يؤدي تعطيل حد التحيز إلى تشويه اختيار الخبير، خاصة عند دمج أكثر من خبيرين.
تُظهر أنماط التوجيه على مستوى الرموز تخصص الخبير في طبقات محددة. على سبيل المثال، يُنشّط إدخال الرياضيات خبير الرياضيات في الطبقات الأعمق، بينما تعتمد الرموز التمهيدية على النموذج العام. يُبرز هذا السلوك تعبيرية النموذج مقارنةً باستراتيجيات التوجيه ذات الخبير الواحد.
الانسحاب وإدارة البيانات
ميزة رئيسية في فلِكس أولمو هي القدرة على الانسحاب الحتمي. يؤدي إزالة خبير من مصفوفة الموجه إلى إزالة تأثيره تمامًا في وقت الاستنتاج. تُظهر التجارب أن إزالة خبير الأخبار يُقلل الأداء في NewsG ولكنه لا يؤثر على المهام الأخرى، مما يؤكد التأثير الموضعي لكل خبير.
الاعتبارات المتعلقة بالخصوصية
تم تقييم مخاطر استخراج بيانات التدريب باستخدام أساليب الهجوم المعروفة. تشير النتائج إلى:
- معدل استخراج 0.1٪ لنموذج عام فقط.
- 1.6٪ لنموذج كثيف مُدرّب على مجموعة بيانات الرياضيات.
- 0.7٪ لفلِكس أولمو مع تضمين خبير الرياضيات.
في حين أن هذه المعدلات منخفضة، يمكن تطبيق تدريب الخصوصية التفاضلية (DP) بشكل مستقل على كل خبير للحصول على ضمانات أقوى. لا تمنع البنية استخدام أساليب DP أو أساليب التدريب المشفر.
القابلية للتطوير
تم تطبيق منهجية فلِكس أولمو على أساس قوي موجود (OLMo-2 7B)، مُدرّب مسبقًا على 4T رموز. أدى دمج خبيرين إضافيين (الرياضيات، الشفرة) إلى تحسين متوسط أداء المعيار من 49.8 إلى 52.8، دون إعادة تدريب النموذج الأساسي. يُظهر هذا القابلية للتطوير والتوافق مع خطوط أنابيب التدريب الحالية.
الخاتمة
يُقدّم فلِكس أولمو إطارًا أساسيًا لبناء نماذج LLMs مُدرّجة تحت قيود إدارة البيانات. يُدعم تصميمه التدريب الموزّع على مجموعات البيانات المُحافظة محليًا ويُمكّن من تضمين/استبعاد تأثير مجموعة البيانات في وقت الاستنتاج. تُؤكد النتائج التجريبية قدرته التنافسية مقابل الأساسيات الأحادية والأساسيات القائمة على التجميع. تُعتبر البنية قابلة للتطبيق بشكل خاص على البيئات التي تحتوي على:
- متطلبات تحديد موقع البيانات.
- سياسات استخدام البيانات الديناميكية.
- قيود الامتثال التنظيمي.
يُوفر فلِكس أولمو مسارًا قابلًا للتطبيق لبناء نماذج لغة عالية الأداء مع الالتزام بحدود الوصول إلى البيانات في العالم الحقيقي.
مواضيع مشابهة:
 دليل برمجي خطوة بخطوة لدمج أدوات البحث والتوصية في الوقت الحقيقي من Dappier AI مع واجهة برمجة تطبيقات دردشة OpenAI
من إليزا إلى نمذجة المحادثة: تطور أنظمة وباراديغمات الذكاء الاصطناعي المحادثي
دليل برمجي خطوة بخطوة لدمج أدوات البحث والتوصية في الوقت الحقيقي من Dappier AI مع واجهة برمجة تطبيقات دردشة OpenAI
من إليزا إلى نمذجة المحادثة: تطور أنظمة وباراديغمات الذكاء الاصطناعي المحادثي
 أداة Llama Prompt Ops: تحسين استجابات نماذج Llama بسهولة
أداة Llama Prompt Ops: تحسين استجابات نماذج Llama بسهولة
 هل يمكن الكشف الآلي عن الهلوسة في نماذج اللغات الكبيرة؟ دراسة نظرية وتطبيقية
هل يمكن الكشف الآلي عن الهلوسة في نماذج اللغات الكبيرة؟ دراسة نظرية وتطبيقية



اترك تعليقاً