نموذج جما 3 (270 مليون معلمة): ثورة الكفاءة في ضبط النماذج اللغوية الكبيرة
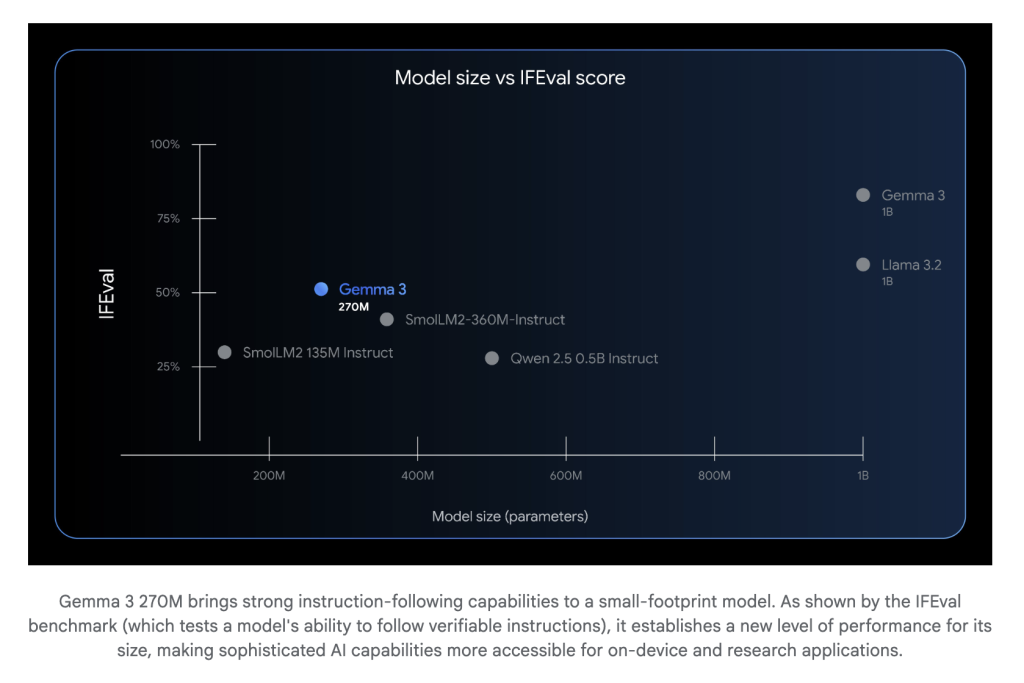
قدمَت جوجل للذكاء الاصطناعي نموذجًا لغويًا جديدًا يُدعى “جما 3” (Gemma 3) يحتوي على 270 مليون معلمة، مُصمم خصيصًا لضبطه بدقة وفعالية عالية على مهام محددة. يتميز هذا النموذج الصغير الحجم بقدرته الرائعة على فهم التعليمات وتنظيم النصوص، مما يجعله جاهزًا للاستخدام والتخصيص الفوري بحد أدنى من التدريب الإضافي.
فلسفة التصميم: “الأداة المناسبة للمهمة المناسبة”
على عكس النماذج اللغوية الضخمة التي تهدف إلى الفهم العام، صُمم نموذج جما 3 (270 مليون معلمة) للاستخدامات المحددة حيث تتفوق الكفاءة على القوة الخام. يُعد هذا الأمر بالغ الأهمية في سيناريوهات مثل:
- الذكاء الاصطناعي على الأجهزة: تشغيل النموذج مباشرة على الهواتف الذكية والأجهزة المحمولة دون الحاجة إلى اتصال دائم بالإنترنت.
- الاستدلال المحافظ على الخصوصية: معالجة البيانات الحساسة محليًا دون الحاجة لنقلها إلى السحابة.
- المهام عالية الحجم والمدروسة جيدًا: مثل تصنيف النصوص، واستخراج الكيانات، والتحقق من الامتثال.
الميزات الأساسية
- مسرد ضخم (256,000 رمز): يخصص نموذج جما 3 حوالي 170 مليون معلمة لطبقة التضمين، مما يدعم مسردًا ضخمًا يتكون من 256,000 رمز. يسمح هذا بمعالجة الرموز النادرة والمتخصصة، مما يجعله مناسبًا بشكل استثنائي لتكييف المجالات، أو المصطلحات الخاصة بالصناعات، أو مهام اللغة المخصصة.
- كفاءة طاقة عالية للغاية للذكاء الاصطناعي على الأجهزة: تُظهر المقاييس الداخلية أن النسخة المُكمّاة بـ INT4 تستهلك أقل من 1% من بطارية هاتف Pixel 9 Pro خلال 25 محادثة نموذجية، مما يجعلها النسخة الأكثر كفاءة في استهلاك الطاقة من عائلة جما حتى الآن. يمكن للمطورين الآن نشر نماذج فعالة على الأجهزة المحمولة، وأجهزة الحافة، والبيئات المضمنة دون التضحية بسرعة الاستجابة أو عمر البطارية.
- جاهز للإنتاج مع التدريب المُدرك للكمّنة (QAT) بـ INT4: يأتي نموذج جما 3 مع نقاط تفتيش تدريب مُدركة للكمّنة، بحيث يمكنه العمل بدقة 4 بت مع خسارة ضئيلة في الجودة. يُمكّن هذا عمليات النشر الإنتاجية على الأجهزة ذات الذاكرة والقدرة الحاسوبية المحدودة، مما يسمح بالاستدلال المحلي المشفر وزيادة ضمانات الخصوصية.
- فهم التعليمات جاهز للاستخدام: يتوفر نموذج جما 3 مُدربًا مسبقًا ومُدربًا على التعليمات، بحيث يفهم التعليمات والطلبات المُنشأة بشكل فوري، ويمكن للمطورين زيادة تخصيص سلوكه باستخدام عدد قليل من أمثلة الضبط الدقيق.
نظرة على بنية النموذج
| المكون | المواصفات |
|---|---|
| إجمالي المعلمات | 270 مليون معلمة |
| معلمات التضمين | ~170 مليون معلمة |
| كتل المحوّل (Transformer) | ~100 مليون معلمة |
| حجم المسرد | 256,000 رمز |
| نافذة السياق | 32 ألف رمز (للحجمين 1 مليار و 270 مليون) |
| أوضاع الدقة | BF16, SFP8, INT4 (QAT) |
| الحد الأدنى لاستخدام الذاكرة العشوائية (Q4_0) | ~240 ميجابايت |
ضبط النموذج: سير العمل وأفضل الممارسات
صُمّم نموذج جما 3 للضبط الدقيق والسريع على مجموعات بيانات مُركزة. يتضمن سير العمل الرسمي، الموضح في دليل Google’s Hugging Face Transformers:
- إعداد مجموعة البيانات: غالبًا ما تكون مجموعات البيانات الصغيرة والمدروسة جيدًا كافية. على سبيل المثال، قد يتطلب تعليم نمط محادثة أو تنسيق بيانات محدد ما بين 10 إلى 20 مثالًا فقط.
- تهيئة المُدرب: باستخدام SFTTrainer من Hugging Face TRL ومحسّنات قابلة للتكوين (AdamW، مُجدول ثابت، إلخ)، يمكن ضبط النموذج وتقييمه، مع مراقبة الإفراط في التجهيز أو نقص التجهيز بمقارنة منحنيات فقدان التدريب والتحقق.
- التقييم: تُظهر اختبارات الاستدلال بعد التدريب قدرة هائلة على التكيّف مع الشخصيات والتنسيقات. يصبح الإفراط في التجهيز، وهو عادةً مشكلة، مفيدًا هنا، حيث يضمن “نسيان” النماذج للمعرفة العامة من أجل الأدوار المتخصصة للغاية (مثل شخصيات ألعاب تقمص الأدوار، أو تدوين يوميات مخصص، أو الامتثال القطاعي).
- النشر: يمكن نشر النماذج على Hugging Face Hub، وتشغيلها على الأجهزة المحلية، أو السحابة، أو Google’s Vertex AI مع تحميل فوري تقريبًا وأقل قدر ممكن من الموارد الحاسوبية.
التطبيقات في العالم الحقيقي
استخدمت شركات مثل Adaptive ML و SK Telecom نماذج جما (بحجم 4 مليار معلمة) لتفوق الأنظمة الخاصة الأكبر حجمًا في معالجة المحتوى متعدد اللغات، مما يُظهر ميزة تخصيص جما. تُمكّن النماذج الأصغر حجمًا مثل نموذج 270 مليون معلمة المطورين من:
- الحفاظ على العديد من النماذج المتخصصة لمهام مختلفة، مما يقلل من التكلفة ومتطلبات البنية التحتية.
- تمكين النماذج الأولية السريعة والتكرار بفضل حجمها وفعاليتها الحسابية.
- ضمان الخصوصية من خلال تنفيذ الذكاء الاصطناعي حصريًا على الجهاز، دون الحاجة إلى نقل البيانات الحساسة للمستخدم إلى السحابة.
الخاتمة
يمثل نموذج جما 3 (270 مليون معلمة) تحولًا جذريًا نحو الذكاء الاصطناعي الفعال القابل للضبط الدقيق، مما يُمكّن المطورين من نشر نماذج عالية الجودة لفهم التعليمات تلبي الاحتياجات المُركزة للغاية. إن مزيج حجمه الصغير، وكفاءة استهلاكه للطاقة، ومرونته مفتوحة المصدر، يجعله ليس مجرد إنجاز تقني، بل حلاً عمليًا للجيل القادم من التطبيقات المُدارة بالذكاء الاصطناعي.
يمكنكم الاطلاع على التفاصيل التقنية هنا [رابط للتفاصيل التقنية] والنموذج على Hugging Face [رابط للنموذج على Hugging Face]. لا تترددوا في زيارة صفحة GitHub الخاصة بنا للحصول على البرامج التعليمية، والأكواد، ودفاتر الملاحظات [رابط لصفحة GitHub]. تابعونا أيضًا على Twitter [رابط لحساب Twitter] ولا تنسوا الانضمام إلى مجتمعنا ML SubReddit الذي يضم أكثر من 100 ألف عضو [رابط لمجتمع ML SubReddit] والاشتراك في قائمتنا البريدية [رابط لقائمة البريدية]. دعمنا على GitHub [رابط لدعم GitHub].
مواضيع مشابهة:
 إندماج الرؤية واللغة: تقنية X-Fusion تُضيف قدرات بصرية لنماذج اللغة الكبيرة دون المساومة على أدائها اللغوي
دليل برمجي لتمكين ذاكرة mem0 مع روبوت Anthropic Claude: محادثات غنية بالسياق
بناء روبوت محادثة ذكي باستخدام MCP-Use و Langchain-Groq
بناء محرك استجابة سريعة للأسئلة باستخدام بيانات الويب و تقنية Together AI
إندماج الرؤية واللغة: تقنية X-Fusion تُضيف قدرات بصرية لنماذج اللغة الكبيرة دون المساومة على أدائها اللغوي
دليل برمجي لتمكين ذاكرة mem0 مع روبوت Anthropic Claude: محادثات غنية بالسياق
بناء روبوت محادثة ذكي باستخدام MCP-Use و Langchain-Groq
بناء محرك استجابة سريعة للأسئلة باستخدام بيانات الويب و تقنية Together AI



اترك تعليقاً