نموذج اللغة الانحدارية الجديد من جوجل: ثورة في التنبؤ بأداء الأنظمة الصناعية
يُقدّم هذا المقال شرحًا تفصيليًا لنموذج اللغة الانحدارية (RLM) الجديد من جوجل، والذي يُحدث ثورة في طريقة التنبؤ بأداء الأنظمة الصناعية المعقدة. يُتيح هذا النموذج القائم على نماذج اللغات الكبيرة (LLMs) التنبؤ بدقة عالية بأداء هذه الأنظمة مباشرةً من بيانات نصية خام، دون الحاجة إلى هندسة ميزات معقدة أو استخدام صيغ جدولية تقليدية.
التحديات التقليدية في التنبؤ بأداء الأنظمة الصناعية
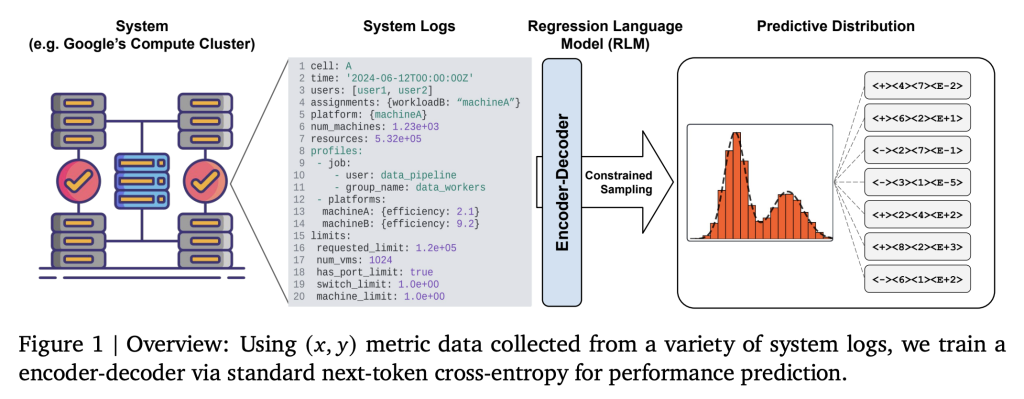
كان التنبؤ بأداء الأنظمة الصناعية واسعة النطاق، مثل مجموعات الحوسبة “بورغ” في جوجل، يتطلب تقليديًا هندسة ميزات محددة للمجال وبيانات جدولية، مما يجعل التوسع والتكيف أمرًا صعبًا. فلم يكن من السهل معالجة سجلات الأحداث، وملفات التكوين، ومجموعات الأجهزة المتغيرة، وبيانات المهام المتداخلة باستخدام نماذج الانحدار التقليدية. نتيجة لذلك، غالبًا ما تصبح سير العمل الخاصة بالتحسين والمحاكاة هشة، ومكلفة، وبطيئة، خاصة عند إدخال أنواع جديدة من الأحمال أو الأجهزة.
الفكرة الرئيسية: الانحدار من النص إلى النص
يعيد نموذج اللغة الانحدارية (RLM) من جوجل صياغة عملية الانحدار كمهمة توليد نصية: يتم تسلسل جميع بيانات حالة النظام (التكوين، السجلات، ملفات تعريف الأحمال، أوصاف الأجهزة) إلى تنسيقات نصية منظمة مثل YAML أو JSON، وتُستخدم كمدخلات للنموذج. ثم يُخرج نموذج الانحدار القيمة العددية المستهدفة (مثل مقاييس الكفاءة، مثل ملايين التعليمات في الثانية لكل وحدة حوسبة من جوجل، MIPS لكل GCU) كاستجابة نصية.
المزايا الرئيسية لنهج النص إلى النص:
- لا حاجة للميزات الجدولية المُعرفة مسبقاً: يُلغي هذا النهج الحاجة إلى مجموعات ميزات مُعرفة مسبقاً، والتحويل، ومخططات التشفير الجامدة.
- التطبيق العالمي: يمكن تمثيل أي حالة نظام كسلسلة نصية؛ يتم دعم الميزات غير المتجانسة، والمتداخلة، أو المتطورة ديناميكيًا بشكلٍ طبيعي.
التفاصيل التقنية: البنية والتدريب
يستخدم النهج نموذج LLM مُشفّر-فكّاك صغير نسبيًا (60 مليون معلمة) يُدرب باستخدام خسارة الانتروبيا المتقاطعة للرمز التالي على التمثيلات النصية للمدخلات والمخرجات. لا يتم تدريب النموذج مسبقًا على نماذج اللغات العامة – يمكن أن يبدأ التدريب من التهيئة العشوائية، مع التركيز مباشرةً على ربط حالات النظام بالنتائج العددية.
جوانب تقنية هامة:
- التجزئة العددية المخصصة: يتم تجزئة النتائج بكفاءة (مثل ترميز الأس-الإشارة-الأس لـ P10) لتمثيل القيم ذات الفاصلة العائمة ضمن مفردات النموذج.
- التكيف السريع: يمكن ضبط نماذج RLM المدربة مسبقًا بسرعة على مهام جديدة باستخدام عدد قليل من الأمثلة (500 مثال فقط)، والتكيف مع تكوينات العناقيد الجديدة أو الأشهر في غضون ساعات، وليس أسابيع.
- توسيع طول التسلسل: يمكن للنماذج معالجة نصوص مدخلات طويلة جدًا (آلاف الرموز)، مما يضمن مراقبة الحالات المعقدة بشكل كامل.
الأداء: النتائج على مجموعة بورغ
عند اختبار نموذج RLM على مجموعة بورغ، حقق دقة عالية وصلت إلى 0.99 من معامل ارتباط سبيرومان (متوسط 0.9) بين MIPS المُتنبأ به و MIPS الحقيقي لكل GCU، مع انخفاض خطأ تربيعي متوسط بنسبة 100 مرة مقارنة بالأساسيات الجدولية. تقوم النماذج بكمية عدم اليقين بشكلٍ طبيعي من خلال أخذ عينات متعددة للمخرجات لكل مدخل، مما يدعم محاكاة النظام الاحتمالية وسير عمل التحسين البايزي.
قياس عدم اليقين:
يُحدد نموذج RLM كل من عدم اليقين العشوائي (الجوهرية) وعدم اليقين المعرفي (المجهولات بسبب المراقبة المحدودة)، على عكس معظم مُعادلات الانحدار الصندوق الأسود.
التطبيقات والملخص
يُقدم نموذج RLM إمكانيات هائلة في العديد من المجالات:
- مُجمّعات الحوسبة السحابية: التنبؤ الدقيق بالاداء وتحسين البنية التحتية الديناميكية واسعة النطاق.
- الصناعة وإنترنت الأشياء: مُحاكيات عالمية للتنبؤ بالنتائج عبر خطوط الأنابيب الصناعية المتنوعة.
- التجارب العلمية: النمذجة الشاملة حيث تكون حالات المدخلات معقدة، موصوفة نصيًا، ومتنوعة عددياً.
يُزيل هذا النهج الجديد – الذي يعالج الانحدار كنمذجة لغوية – الحواجز طويلة الأمد في محاكاة النظام، ويُمكن التكيف السريع مع بيئات جديدة، ويدعم التنبؤ القوي المُدرك لعدم اليقين، وكلها أمور بالغة الأهمية للذكاء الاصطناعي الصناعي من الجيل التالي.
روابط إضافية:
- رابط البحث العلمي (قم بتحديث الرابط ببيانات صحيحة إن وجدت)
- [صفحة جيثب](رابط جيثب) (قم بتحديث الرابط ببيانات صحيحة إن وجدت)
- [تويتر](رابط تويتر) (قم بتحديث الرابط ببيانات صحيحة إن وجدت)
- [ريديت](رابط ريديت) (قم بتحديث الرابط ببيانات صحيحة إن وجدت)
- [النشرة البريدية](رابط النشرة) (قم بتحديث الرابط ببيانات صحيحة إن وجدت)
مواضيع مشابهة:
 دليل برمجي لبناء وكيل ReAct يستدعي الأدوات ويدمج منطق برولوج مع جيميني وLangGraph
دليل برمجي لبناء وكيل ReAct يستدعي الأدوات ويدمج منطق برولوج مع جيميني وLangGraph
 إطار عمل REST: اختبار ضغط نماذج الاستدلال الضخمة لتقييم قدراتها على حلّ مشكلات متعددة
وضع مايكروسوفت إيدج معيارًا جديدًا لتصفح الإنترنت في عصر الذكاء الاصطناعي
مقارنة شاملة لأفضل نماذج اللغات الكبيرة في البرمجة لعام 2025
إطار عمل REST: اختبار ضغط نماذج الاستدلال الضخمة لتقييم قدراتها على حلّ مشكلات متعددة
وضع مايكروسوفت إيدج معيارًا جديدًا لتصفح الإنترنت في عصر الذكاء الاصطناعي
مقارنة شاملة لأفضل نماذج اللغات الكبيرة في البرمجة لعام 2025



اترك تعليقاً