نموذج Qwen3-ASR: ثورة في دقة وسرعة الترجمة الصوتية
يُعلن فريق Qwen التابع لشركة علي بابا عن إطلاق نموذج Qwen3-ASR Flash، وهو نموذج متكامل للتعرف الآلي على الكلام (ASR) متوفر كخدمة API، مبني على قوة الذكاء الاصطناعي لنموذج Qwen3-Omni. يُسهّل هذا النموذج عملية النسخ الآلي متعدد اللغات، حتى في البيئات الصاخبة أو المتخصصة، دون الحاجة إلى استخدام أنظمة متعددة.
الميزات الرئيسية لـ Qwen3-ASR:
-
التعرف على اللغات المتعددة: يدعم النموذج الكشف التلقائي والنسخ لـ 11 لغة، بما في ذلك الإنجليزية والصينية، بالإضافة إلى العربية، الألمانية، الإسبانية، الفرنسية، الإيطالية، اليابانية، الكورية، البرتغالية، الروسية، والصينية المبسطة. هذه الميزة تجعل Qwen3-ASR مناسباً للاستخدام العالمي دون الحاجة إلى نماذج منفصلة.
-
آلية حقن السياق: يمكن للمستخدمين لصق أي نص – أسماء، مصطلحات خاصة بمجال معين، أو حتى سلاسل غير منطقية – لتوجيه عملية النسخ. هذه الميزة فعالة بشكل خاص في السيناريوهات الغنية بالتعابير الاصطلاحية، والأسماء الخاصة، أو المصطلحات المتغيرة.
-
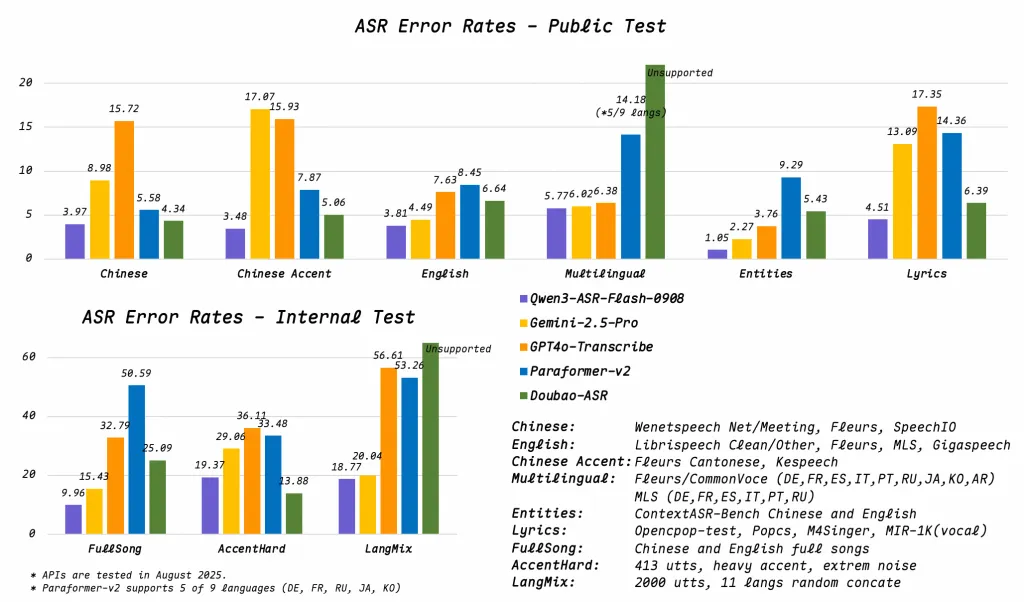
معالجة الصوت القوية: يحافظ النموذج على أدائه العالي في البيئات الصاخبة، والتسجيلات منخفضة الجودة، والإدخال من مسافات بعيدة (مثل الميكروفونات البعيدة)، والصوتيات المتعددة الوسائط مثل الأغاني أو موسيقى الراب. يُبلغ معدل خطأ الكلمات (WER) أقل من 8%، وهو رقم مثير للإعجاب تقنيًا لمثل هذه المدخلات المتنوعة.
-
بساطة نموذج واحد: يلغي تعقيد الحفاظ على نماذج مختلفة للغات أو سياقات الصوت – نموذج واحد مع خدمة API لإدارة كل شيء. تتنوع حالات الاستخدام لتشمل منصات التعليم الإلكتروني (التسجيل المحاضرات، التدريس متعدد اللغات)، ووسائل الإعلام (الترجمة، الصوتيات)، وخدمة العملاء (نظام الرد الآلي متعدد اللغات أو نسخ المحادثات).
تقييم تقني:
الكشف عن اللغة + النسخ:
يسمح الكشف التلقائي عن اللغة للنموذج بتحديد اللغة قبل النسخ – وهي ميزة حيوية في البيئات متعددة اللغات أو التقاط الصوت السلبي. هذا يقلل من الحاجة إلى تحديد اللغة يدويًا ويُحسّن من سهولة الاستخدام.
حقن وِسم السياق:
يُوجّه لصق النص كـ “سياق” عملية التعرف نحو المفردات المتوقعة. تقنيًا، يمكن أن يعمل هذا من خلال ضبط البادئة أو حقن البادئة – تضمين السياق في تيار الإدخال للتأثير على فك التشفير. إنها طريقة مرنة للتكيف مع المفردات الخاصة بمجال معين دون إعادة تدريب النموذج.
معدل خطأ الكلمات (WER) < 8% في سيناريوهات معقدة:
إن الحفاظ على معدل خطأ الكلمات (WER) أقل من 8% عبر الموسيقى، موسيقى الراب، الضوضاء الخلفية، والصوت منخفض الدقة، يضع Qwen3-ASR في مصاف أفضل أنظمة التعرف المفتوحة. للمقارنة، تستهدف النماذج القوية في الكلام المقروء النظيف معدل خطأ كلمات (WER) من 3 إلى 5%، ولكن الأداء يتدهور بشكل ملحوظ عادةً في السياقات الصاخبة أو الموسيقية.
التغطية متعددة اللغات:
يدعم النموذج 11 لغة، بما في ذلك اللغة الصينية ذات الكتابة الأيديغرافية واللغات ذات الصوتيات المتنوعة مثل العربية واليابانية، مما يشير إلى بيانات تدريب متعددة اللغات كبيرة وسعة نمذجة لغوية متعددة. إن معالجة كل من اللغات النغمية (الماندرين) وغير النغمية ليست مهمة بسيطة.
بنية نموذج واحد:
أنيق من الناحية التشغيلية: نشر نموذج واحد لجميع المهام. هذا يقلل من عبء العمليات – لا حاجة لتبديل أو اختيار النماذج ديناميكيًا. كل شيء يعمل في خط أنابيب ASR موحد مع كشف اللغة المدمج.
النشر والتجربة:
يوفر مساحة Hugging Face لـ Qwen3-ASR واجهة حية: قم بتحميل الصوت، أدخل السياق اختياريًا، واختر لغة أو استخدم الكشف التلقائي. وهو متوفر كخدمة API.
الخلاصة:
يُعد Qwen3-ASR Flash (متوفر كخدمة API) حلاً تقنيًا مُقنعًا وسهل النشر للتعرف على الكلام. يقدم مزيجًا نادرًا: دعم متعدد اللغات، ونسخ دقيق مع مراعاة السياق، والتعرف على الكلام المقاوم للضوضاء – كل ذلك في نموذج واحد. تفضل بزيارة خدمة API، والتفاصيل التقنية، وعرض تجريبي على Hugging Face. لا تتردد في زيارة صفحة GitHub للحصول على الدروس التعليمية، والرموز، ودفاتر الملاحظات. كما يمكنك متابعتنا على تويتر، والانضمام إلى مجتمعنا ML SubReddit الذي يضم أكثر من 100 ألف عضو، والاشتراك في نشرتنا الإخبارية.
مواضيع مشابهة:
 بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه
بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه



اترك تعليقاً