نموذج Qwen3-ASR للتعرف على الكلام: دقة متقدمة وسهولة استخدام غير مسبوقة
أعلنت شركة علي بابا عن إطلاق نموذجها الجديد للتعرف الآلي على الكلام، Qwen3-ASR Flash، والذي يُقدّم خدمة متكاملة عبر واجهة برمجة التطبيقات (API). يُبنى هذا النموذج القوي على أساس نموذج Qwen3-Omni متعدد اللغات، متجاوزًا بذلك حدود النماذج التقليدية من حيث قدرته على التعامل مع الضوضاء واللهجات المختلفة والمجالات المتخصصة، كل ذلك دون الحاجة إلى استخدام أنظمة متعددة.
المزايا الرئيسية لـ Qwen3-ASR:
-
دعم متعدد اللغات: يدعم النموذج التعرف التلقائي والترجمة الفورية لأكثر من 11 لغة، بما في ذلك الإنجليزية والصينية والعربية والألمانية والإسبانية والفرنسية والإيطالية واليابانية والكورية والبرتغالية والروسية والصينية المبسطة. هذه الميزة تجعله نموذجًا عالميًا بامتياز، دون الحاجة إلى نماذج منفصلة لكل لغة.
-
آلية حقن السياق: يتيح النموذج للمستخدمين إضافة نص تعسفي، مثل الأسماء، والمصطلحات المتخصصة، أو حتى سلاسل أحرف عشوائية، لتوجيه عملية الترجمة. هذه الميزة فعّالة بشكل خاص في السيناريوهات الغنية بالتعبيرات الاصطلاحية، والأسماء الخاصة، أو المصطلحات المتطورة.
-
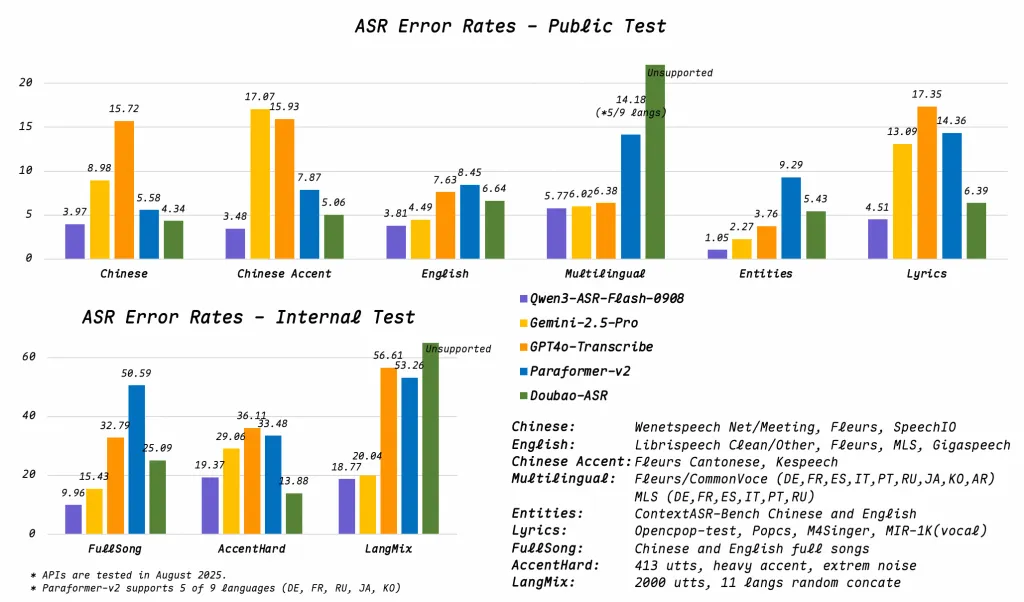
معالجة صوتية متينة: يحافظ النموذج على أدائه الممتاز حتى في البيئات الصاخبة، والتسجيلات منخفضة الجودة، والإدخال من مسافات بعيدة (مثل الميكروفونات البعيدة)، والمقاطع الصوتية المتعددة الوسائط مثل الأغاني أو موسيقى الراب. وقد أظهرت النتائج معدل خطأ في الكلمات (WER) أقل من 8%، وهو رقم مثير للإعجاب بالنظر إلى تنوع مدخلات الصوت.
-
بساطة النموذج الواحد: يلغي النموذج تعقيد الحفاظ على نماذج مختلفة للغات أو سياقات الصوت المختلفة، حيث يعتبر نموذج واحد عبر واجهة برمجة التطبيقات هو الحل الأمثل لجميع هذه المهام.
تطبيقات نموذج Qwen3-ASR:
تتنوع استخدامات Qwen3-ASR لتشمل العديد من المجالات، مثل:
- منصات التعليم الإلكتروني: تسجيل المحاضرات، والدروس التعليمية متعددة اللغات.
- وسائل الإعلام: إضافة الترجمة، وخدمات الصوت.
- خدمة العملاء: أنظمة الاستجابة الصوتية التفاعلية متعددة اللغات، وترجمة المحادثات.
تقييم تقني للنموذج:
الكشف عن اللغة والترجمة:
تتيح ميزة الكشف التلقائي عن اللغة للنموذج تحديد اللغة قبل الترجمة، وهو أمر بالغ الأهمية في البيئات التي تحتوي على لغات مختلطة أو في عمليات التقاط الصوت السلبي. هذا يقلل من الحاجة إلى تحديد اللغة يدويًا ويحسن من سهولة الاستخدام.
حقن رمز السياق:
تتمثل هذه الميزة في إمكانية لصق النصوص كـ “سياق” لتوجيه عملية التعرف على الكلمات المتوقعة. يمكن أن يعمل هذا تقنيًا عبر ضبط البادئة أو حقن البادئة – تضمين السياق في تدفق الإدخال للتأثير على عملية فك التشفير. وهي طريقة مرنة للتكيف مع المفردات الخاصة بمجال معين دون إعادة تدريب النموذج.
معدل خطأ الكلمات (WER) أقل من 8% في سيناريوهات معقدة:
يُعدّ معدل خطأ الكلمات (WER) أقل من 8% عبر الموسيقى، و موسيقى الراب، والضوضاء الخلفية، والصوت منخفض الدقة، ميزةً تفوق العديد من أنظمة التعرف المفتوحة المصدر. للمقارنة، تستهدف النماذج القوية في الكلام المُقروء النظيف معدل خطأ يبلغ من 3 إلى 5%، لكن الأداء يتدهور بشكل كبير عادةً في السياقات الصاخبة أو الموسيقية.
التغطية متعددة اللغات:
يدعم النموذج 11 لغة، بما في ذلك اللغة الصينية الكتابية واللغات التي تختلف في بنيتها الصوتية مثل العربية واليابانية، مما يشير إلى وجود بيانات تدريب متعددة اللغات كبيرة وسعة نمذجة لغوية متقدمة. إن معالجة كل من اللغات النغمية (مثل الماندرين) واللغات غير النغمية أمرٌ ليس بالسهل.
هندسة النموذج الواحد:
يُعدّ استخدام نموذج واحد لجميع المهام أمرًا أنيقًا من الناحية التشغيلية، حيث يقلل من عبء العمليات – لا حاجة لتبديل أو اختيار النماذج ديناميكيًا. كل شيء يعمل في خط أنابيب ASR موحد مع ميزة الكشف عن اللغة المدمجة.
النشر والتجربة:
يُتاح الوصول إلى واجهة Qwen3-ASR عبر مساحة Hugging Face، حيث يمكن للمستخدمين تحميل ملفات الصوت، وإدخال السياق اختياريًا، واختيار لغة أو استخدام ميزة الكشف التلقائي. كما يتوفر النموذج كخدمة عبر واجهة برمجة التطبيقات (API).
الخاتمة:
يُعدّ Qwen3-ASR Flash (المتوفّر كخدمة API) حلاً قويًا من الناحية التقنية وسهل النشر للتعرف على الكلام. فهو يوفر مزيجًا نادرًا: دعم متعدد اللغات، وترجمة دقيقة مع مراعاة السياق، والتعرف على الكلام في البيئات الصاخبة – كل ذلك في نموذج واحد.
مواضيع مشابهة:
 DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
 بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena
بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena



اترك تعليقاً