نموذج التعرف على الكلام المفتوح المصدر OLMoASR: منافس قوي لنظام Whisper من OpenAI
يُعدّ إطلاق معهد ألين للذكاء الاصطناعي (AI2) لنموذج OLMoASR، وهو مجموعة من نماذج التعرف الآلي على الكلام (ASR) مفتوحة المصدر، خطوةً ثوريةً في هذا المجال. فهذه النماذج تُنافس بقوة الأنظمة المغلقة المصدر مثل نظام Whisper من OpenAI. ولكن ما يميز OLMoASR هو الشفافية غير المسبوقة في إتاحته، حيث لم يكتفِ AI2 بنشر أوزان النموذج فقط، بل نشر أيضاً مُعرفات بيانات التدريب، وخطوات الترشيح، ووصفات التدريب، ونُسخ البرامج النصية للمعايير – وهي ممارسة نادرة في مجال ASR. هذا يجعل OLMoASR أحد أكثر المنصات شيوعاً وقابلية للتوسيع في أبحاث التعرف على الكلام.
لماذا التعرف على الكلام المفتوح المصدر؟
معظم نماذج التعرف على الكلام المتاحة اليوم – سواء من OpenAI أو Google أو Microsoft – لا يمكن الوصول إليها إلا عبر واجهات برمجة التطبيقات (APIs). وبينما توفر هذه الخدمات أداءً عالياً، إلا أنها تعمل كصناديق سوداء: بيانات التدريب غير شفافة، وطرق الترشيح غير موثقة، وبروتوكولات التقييم لا تتوافق دائماً مع معايير البحث العلمي. يُشكل هذا الافتقار للشفافية تحديات أمام إمكانية التكرار والتقدم العلمي. فالباحثون لا يستطيعون التحقق من الادعاءات، أو اختبار الاختلافات، أو تكييف النماذج مع مجالات جديدة دون إعادة بناء مجموعات بيانات ضخمة بأنفسهم. يُعالج OLMoASR هذه المشكلة من خلال فتح كامل خط الأنابيب. فالإصدار لا يقتصر على تمكين النسخ العملي فحسب، بل يتعلق أيضاً بدفع ASR نحو أساس علمي أكثر انفتاحاً.
بنية النموذج وتوسيع نطاقه
يستخدم OLMoASR بنية مُشفّر-فكّ الشفرة القائمة على المُحوّل (Transformer)، وهي النموذج السائد في أنظمة ASR الحديثة. يقوم المُشفّر باستيعاب أشكال موجات الصوت وينتج تمثيلاً كامناً. يقوم فكّ الشفرة بإنشاء رموز نصية مشروطة بمخرجات المُشفّر. يُشبه هذا التصميم نظام Whisper، لكن OLMoASR يجعل التنفيذ مفتوحاً بالكامل. تغطي عائلة النماذج ستة أحجام، كلها مُدرّبة على اللغة الإنجليزية:
- tiny.en: 39 مليون معلمة، مصمم للاستدلال الخفيف.
- base.en: 74 مليون معلمة.
- small.en: 244 مليون معلمة.
- medium.en: 769 مليون معلمة.
- large.en-v1: 1.5 مليار معلمة، مُدرّب على 440 ألف ساعة.
- large.en-v2: 1.5 مليار معلمة، مُدرّب على 680 ألف ساعة.
يسمح هذا النطاق للمطورين بالتداول بين تكلفة الاستدلال والدقة. تُناسب النماذج الأصغر الأجهزة المدمجة أو النسخ في الوقت الفعلي، بينما تُعظم النماذج الأكبر الدقة للبحث أو أحمال العمل المجمعة.
البيانات: من استخراج الويب إلى المجموعات المُعالجة
إحدى المساهمات الأساسية لـ OLMoASR هي الإصدار المفتوح لمجموعات بيانات التدريب، وليس فقط النماذج.
- OLMoASR-Pool (~3 ملايين ساعة): هذه المجموعة الضخمة تحتوي على كلام مُشرف عليه ضعيفاً مقترناً بنسخ مُستخرجة من الويب. تتضمن حوالي 3 ملايين ساعة من الصوت و 17 مليون نص. مثل مجموعة بيانات Whisper الأصلية، فهي ضعيفة، وتحتوي على عناوين غير مُحاذية، ومُكررات، وأخطاء في النسخ.
- OLMoASR-Mix (~مليون ساعة): لمعالجة مشاكل الجودة، طبّق AI2 عمليات ترشيح صارمة:
- خوارزميات المُحاذاة لضمان تطابق الصوت والنسخ.
- إزالة المُكررات المُبهمة لإزالة الأمثلة المُكررة أو منخفضة التنوع.
- قواعد التنظيف لإزالة الأسطر المُكررة والنصوص غير المُطابقة.
النتيجة هي مجموعة بيانات عالية الجودة، حجمها مليون ساعة، تعزز التعميم بدون بيانات مُسبقة – وهو أمر بالغ الأهمية للمهام الواقعية حيث قد تختلف البيانات عن توزيعات التدريب. تُحاكي هذه الاستراتيجية ذات المستويين للبيانات الممارسات في تدريب نماذج اللغة الضخمة: استخدام نصوص ضخمة ضعيفة الحجم، ثم تنقيحها بمجموعات فرعية مُصفّاة لتحسين الجودة.
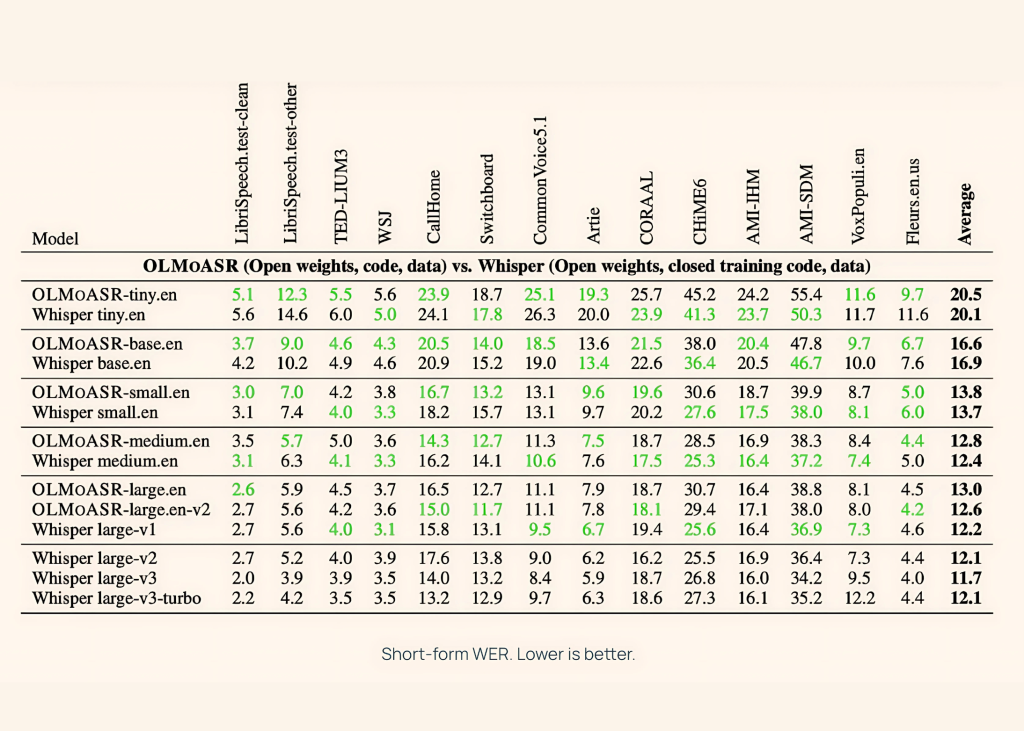
معايير الأداء
قارن AI2 أداء OLMoASR مع Whisper عبر مهام الكلام قصير المدى وطويل المدى، باستخدام مجموعات بيانات مثل LibriSpeech، وTED-LIUM3، وSwitchboard، وAMI، وVoxPopuli.
-
النموذج المتوسط (769 مليون معلمة):
- 12.8% معدل خطأ الكلمات (WER) في الكلام قصير المدى.
- 11.0% WER في الكلام طويل المدى.
- هذا يُقارب تقريباً Whisper-medium.en، الذي يحقق 12.4% و 10.5% على التوالي.
-
النموذج الكبير (1.5 مليار معلمة):
- large.en-v1 (440 ألف ساعة): 13.0% WER قصير المدى مقابل 12.2% لـ Whisper large-v1.
- large.en-v2 (680 ألف ساعة): 12.6% WER، مُقترباً من أقل من 0.5%.
-
النموذج الصغير: حتى الإصدارات الصغيرة (tiny و base) تُظهر أداءً تنافسياً:
- tiny.en: ~20.5% WER قصير المدى، ~15.6% WER طويل المدى.
- base.en: ~16.6% WER قصير المدى، ~12.9% WER طويل المدى.
يُتيح هذا للمطورين المرونة في اختيار النماذج بناءً على متطلبات الحوسبة وزمن الوصول.
كيفية الاستخدام؟
تستغرق عملية نسخ الصوت بضع أسطر من التعليمات البرمجية فقط:
import olmoasr
model = olmoasr.load_model("medium", inference=True)
result = model.transcribe("audio.mp3")
print(result)تتضمن المخرجات كل من النسخ والجزء المُحاذى للوقت، مما يجعلها مفيدة لإضافة التسميات التوضيحية، ونسخ الاجتماعات، أو خطوط أنابيب معالجة اللغة الطبيعية (NLP) الأخرى.
الضبط الدقيق وتكييف المجال
بما أن AI2 يوفر رمز التدريب الكامل والوصفات، يمكن ضبط OLMoASR بدقة للمجالات المتخصصة:
- التعرف على الكلام الطبي – تكييف النماذج على مجموعات بيانات مثل MIMIC-III أو التسجيلات الخاصة بالمستشفيات.
- النسخ القانوني – التدريب على الصوت من قاعات المحاكم أو الإجراءات القانونية.
- اللهجات منخفضة الموارد – الضبط الدقيق على اللهجات التي لم يتم تغطيتها جيداً في OLMoASR-Mix.
هذه القدرة على التكيف أمر بالغ الأهمية: غالباً ما ينخفض أداء ASR عند استخدام النماذج في مجالات متخصصة ذات مصطلحات خاصة بالمجال. تجعل خطوط الأنابيب المفتوحة تكييف المجال أمراً بسيطاً.
التطبيقات
يفتح OLMoASR فرصاً مثيرة في الأبحاث الأكاديمية وتطوير الذكاء الاصطناعي في العالم الحقيقي:
- البحث التعليمي: يمكن للباحثين استكشاف العلاقات المعقدة بين بنية النموذج، وجودة مجموعة البيانات، وتقنيات الترشيح لفهم آثارها على أداء التعرف على الكلام.
- تفاعل الإنسان مع الكمبيوتر: يكتسب المطورون حرية تضمين إمكانيات التعرف على الكلام مباشرةً في أنظمة الذكاء الاصطناعي التفاعلية، ومنصات نسخ الاجتماعات في الوقت الفعلي، وتطبيقات إمكانية الوصول – كل ذلك دون الاعتماد على واجهات برمجة التطبيقات الخاصة أو الخدمات الخارجية.
- تطوير الذكاء الاصطناعي متعدد الوسائط: عند دمجه مع نماذج اللغة الضخمة، يُمكن OLMoASR من إنشاء مساعدين متعددي الوسائط متقدمين يمكنهم معالجة المدخلات المنطوقة بسلاسة وإنشاء استجابات ذكية مُدركة للسياق.
- مقارنة معايير البحث: تضع إتاحة بيانات التدريب ومعايير التقييم المفتوحة OLMoASR كنقطة مرجعية مُعيارية، مما يسمح للباحثين بمقارنة الأساليب الجديدة مع خط أساس مُتناسق وقابل للتكرار في دراسات ASR المستقبلية.
الخلاصة
يُقدم إصدار OLMoASR نموذجاً يُظهر كيف يمكن تطوير نماذج التعرف على الكلام عالية الجودة وإصدارها بطريقة تُعطي الأولوية للشفافية وإمكانية التكرار. وبينما تقتصر النماذج حالياً على اللغة الإنجليزية ولا تزال تتطلب قدرات حوسبة كبيرة للتدريب، إلا أنها توفر أساساً متيناً للتكييف والتوسيع. يُحدد هذا الإصدار نقطة مرجعية واضحة للأعمال المستقبلية في ASR المفتوحة، ويُسهل على الباحثين والمطورين دراسة نماذج التعرف على الكلام وتقييمها وتطبيقها في مجالات مختلفة.
يمكنكم الاطلاع على النموذج على Hugging Face، وصفحة GitHub، والتفاصيل الفنية. لا تترددوا في زيارة صفحة GitHub لدينا للحصول على الدروس التعليمية، والرموز، ودفاتر الملاحظات. كما يُمكنكم متابعتنا على تويتر، والانضمام إلى مجتمعنا على Reddit، والاشتراك في قائمتنا البريدية.
مواضيع مشابهة:
 بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه
بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه



اترك تعليقاً