نماذج LFM2-VL: سرعة فائقة وكفاءة عالية في معالجة الصور والنصوص
أطلقت شركة Liquid AI عائلة جديدة من نماذج الذكاء الاصطناعي المتقدمة والمعروفة باسم LFM2-VL، وهي مصممة خصيصاً لتقديم أداء سريع ودقيق في معالجة الصور والنصوص على الأجهزة الذكية المختلفة، مثل الهواتف الذكية، والحواسيب المحمولة، والأجهزة القابلة للارتداء، والأنظمة المدمجة. وتتميز هذه النماذج بكفاءتها العالية وقدرتها على العمل بسرعة فائقة دون المساومة على دقة النتائج.
مميزات نماذج LFM2-VL:
- سرعة استنتاجية غير مسبوقة: تتميز نماذج LFM2-VL بسرعة استنتاجية تصل إلى ضعف سرعة نماذج الصور والنصوص الحالية، مع الحفاظ على أداء تنافسي في المهام المختلفة مثل وصف الصور، والإجابة على الأسئلة المرئية، والتفكير متعدد الوسائط.
- كفاءة عالية في استخدام الموارد: يأتي النموذج في نسختين: LFM2-VL-450M و LFM2-VL-1.6B. النسخة الأولى (450 مليون باراميتر) مصممة للبيئات ذات الموارد المحدودة، بينما النسخة الثانية (1.6 مليار باراميتر) توفر قدرات أكبر مع الحفاظ على حجمها الصغير بما يكفي للعمل على وحدة معالجة رسوميات واحدة أو على الهواتف الذكية المتطورة.
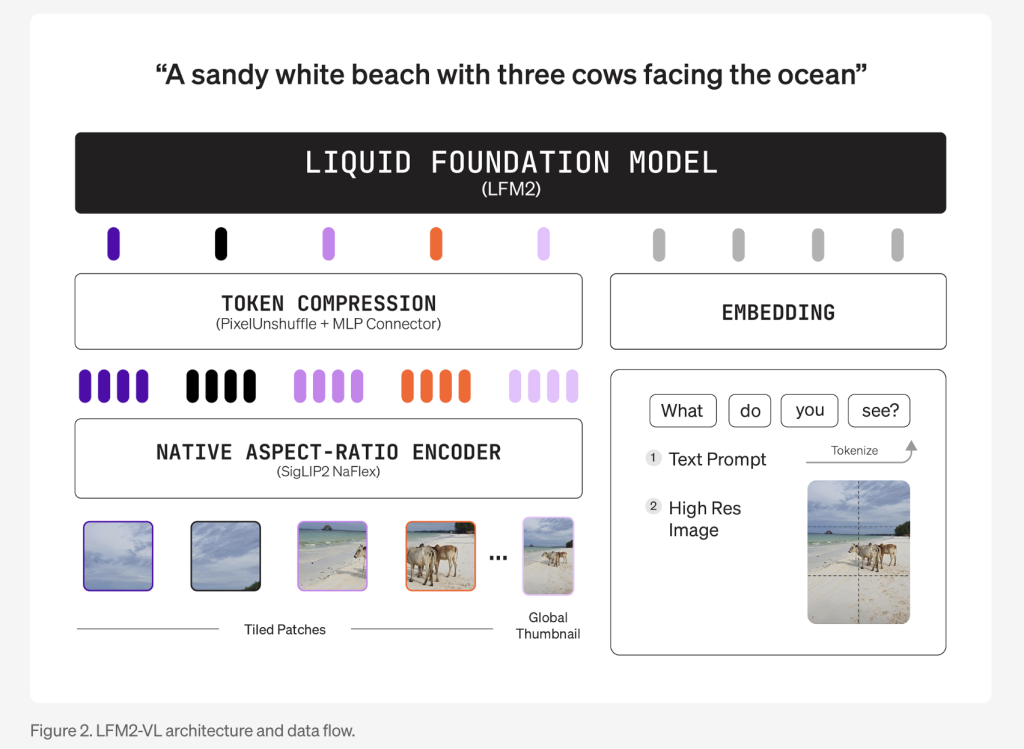
- هندسة معمارية نمطية: تعتمد نماذج LFM2-VL على هندسة معمارية نمطية تجمع بين:
- نموذج لغوي أساسي (LFM2-1.2B أو LFM2-350M).
- مُشفّر بصري SigLIP2 NaFlex (400 مليون أو 86 مليون باراميتر).
- مُسقط متعدد الوسائط مع تقنية “إلغاء تشويش البكسل” لتقليل عدد رموز الصورة بشكل ديناميكي من أجل معالجة أسرع.
- معالجة الصور بدقة أصلية: تُعالَج الصور بدقة أصلية تصل إلى 512×512 بكسل دون تشويه ناتج عن تغيير الحجم. أما الصور الأكبر، فتُقسّم إلى أجزاء غير متداخلة بحجم 512×512 بكسل، مما يحافظ على التفاصيل ونسبة العرض إلى الارتفاع. يقوم النموذج 1.6B أيضاً بتشفير صورة مصغرة مُصغّرة للصورة الكاملة لفهم السياق العام.
- استنتاج مرن: يمكن للمستخدمين ضبط التوازن بين السرعة والجودة أثناء الاستنتاج من خلال تعديل الحد الأقصى لرموز الصورة وعدد الأجزاء، مما يسمح بالتكيف في الوقت الحقيقي مع قدرات الجهاز واحتياجات التطبيق.
- عملية التدريب: تم تدريب النماذج أولاً على العمود الفقري LFM2، ثم تم تدريبها بشكل مشترك لدمج قدرات الرؤية واللغة باستخدام تعديل تدريجي لنسب بيانات النص إلى الصورة، وأخيراً تم ضبطها بدقة لفهم الصور باستخدام حوالي 100 مليار رمز متعدد الوسائط.
الأداء القياسي:
تقدم نماذج LFM2-VL نتائج تنافسية في المعايير العامة مثل RealWorldQA و MM-IFEval و OCRBench، متنافسة مع نماذج أكبر مثل InternVL3 و SmolVLM2، لكن مع مساحة ذاكرة أصغر وسرعة معالجة أعلى بكثير، مما يجعلها مثالية لتطبيقات الحافة والأجهزة المحمولة.
الوصول إلى النماذج:
كلا حجمي النموذج متاحان للتحميل مجاناً على Hugging Face برخصة Apache 2.0، مما يسمح بالاستخدام الحر للأبحاث والاستخدام التجاري من قبل الشركات. يجب على الشركات الكبيرة الاتصال بـ Liquid AI للحصول على ترخيص تجاري. تتضمن النماذج تكاملاً سلساً مع Hugging Face Transformers وتدعم الكميّة لزيادة الكفاءة على أجهزة الحافة.
حالات الاستخدام والتكامل:
صُممت نماذج LFM2-VL للمطورين والشركات التي تسعى إلى نشر ذكاء اصطناعي متعدد الوسائط سريع ودقيق وكفؤ مباشرة على الأجهزة، مما يقلل من الاعتماد على السحابة ويمكّن تطبيقات جديدة في الروبوتات وإنترنت الأشياء والكاميرات الذكية والمساعدين الشخصيين على الهاتف المحمول والمزيد. تشمل أمثلة التطبيقات:
- كتابة تعليقات على الصور في الوقت الحقيقي.
- البحث المرئي.
- روبوتات الدردشة التفاعلية متعددة الوسائط.
البدء بالعمل:
- التحميل: تتوفر كلا النموذجين الآن على مجموعة Liquid AI على Hugging Face.
- التشغيل: يتم توفير شفرة استنتاج نموذجية لأنظمة أساسية مثل llama.cpp، مع دعم مستويات كمية مختلفة لتحقيق الأداء الأمثل على أجهزة مختلفة.
- التخصيص: تدعم الهندسة المعمارية التكامل مع منصة LEAP من Liquid AI لمزيد من التخصيص ونشر الحافة على منصات متعددة.
باختصار، تُعد نماذج LFM2-VL من Liquid AI معياراً جديداً لكفاءة نماذج الصور والنصوص مفتوحة المصدر على الحافة. مع دعم الدقة الأصلية، والتوازن القابل للتعديل بين السرعة والجودة، والتركيز على النشر في العالم الحقيقي، تُمكّن هذه النماذج المطورين من بناء الجيل التالي من التطبيقات القائمة على الذكاء الاصطناعي في أي مكان وعلى أي جهاز.
مواضيع مشابهة:
 دليل برمجي خطوة بخطوة لدمج أدوات البحث والتوصية في الوقت الحقيقي من Dappier AI مع واجهة برمجة تطبيقات دردشة OpenAI
من إليزا إلى نمذجة المحادثة: تطور أنظمة وباراديغمات الذكاء الاصطناعي المحادثي
دليل برمجي خطوة بخطوة لدمج أدوات البحث والتوصية في الوقت الحقيقي من Dappier AI مع واجهة برمجة تطبيقات دردشة OpenAI
من إليزا إلى نمذجة المحادثة: تطور أنظمة وباراديغمات الذكاء الاصطناعي المحادثي
 أداة Llama Prompt Ops: تحسين استجابات نماذج Llama بسهولة
أداة Llama Prompt Ops: تحسين استجابات نماذج Llama بسهولة
 هل يمكن الكشف الآلي عن الهلوسة في نماذج اللغات الكبيرة؟ دراسة نظرية وتطبيقية
هل يمكن الكشف الآلي عن الهلوسة في نماذج اللغات الكبيرة؟ دراسة نظرية وتطبيقية



اترك تعليقاً