نماذج Biomni-R0 اللغوية الضخمة: ثورة في الذكاء الاصطناعي للبحوث الطبية الحيوية
يُشهد مجال الذكاء الاصطناعي في البحوث الطبية الحيوية تطوراً سريعاً، مع تزايد الطلب على نماذج قادرة على أداء مهام تتراوح بين الجينوميات والتشخيص السريري وعلم الأحياء الجزيئي. وليس من المطلوب من هذه النماذج مجرد استرجاع الحقائق، بل يُتوقع منها التفكير المنطقي في المشكلات البيولوجية المعقدة، وتفسير بيانات المرضى، واستخراج رؤى ذات مغزى من قواعد البيانات الطبية الحيوية الضخمة. وعلى عكس نماذج الذكاء الاصطناعي العامة، يجب أن تتفاعل النماذج الطبية الحيوية مع أدوات محددة للمجال، وأن تفهم التسلسلات الهرمية البيولوجية، وأن تحاكي سير العمل المماثل لسير عمل الباحثين لدعم البحوث الطبية الحيوية الحديثة بفعالية.
التحدي الرئيسي: تحقيق مستوى التفكير الخبير
لكن تحقيق الأداء على مستوى الخبراء في هذه المهام ليس بالأمر الهين. فمعظم النماذج اللغوية الكبيرة تُعاني عند التعامل مع دقة وعمق التفكير الطبي الحيوي. قد تنجح في مهام استرجاع الحقائق السطحية أو التعرف على الأنماط، لكنها غالباً ما تفشل عندما تواجهها مهام تتطلب تفكيراً متعدد الخطوات، أو تشخيص أمراض نادرة، أو تحديد أولويات الجينات، وهي مجالات تتطلب ليس فقط الوصول إلى البيانات، بل أيضاً الفهم السياقي والحكم الخاص بالمجال. وهذا القصور خلق فجوة واضحة: كيف ندرب نماذج الذكاء الاصطناعي الطبية الحيوية التي تستطيع التفكير والتصرف مثل خبراء المجال؟
قصور الأساليب التقليدية
في حين أن بعض الحلول تعتمد على التعلم الخاضع للإشراف على مجموعات بيانات طبية حيوية مُنسقة، أو توليد مُعزز بالاسترجاع لتأسيس الاستجابات في الأدبيات أو قواعد البيانات، إلا أن هذه الأساليب لها عيوبها. فهي غالباً ما تعتمد على مطالبات ثابتة وسلوكيات مُحددة مسبقاً تفتقر إلى القدرة على التكيف. علاوة على ذلك، فإن العديد من هذه النماذج تكافح لتنفيذ الأدوات الخارجية بفعالية، وتنهار سلاسل استنتاجاتها عندما تواجهها هياكل طبية حيوية غير مألوفة. يجعل هذا الهشاشة غير مناسبة للبيئات الديناميكية أو عالية المخاطر، حيث لا يمكن التفاوض على قابلية التفسير والدقة.
Biomni-R0: نموذج جديد قائم على التعلم المعزز
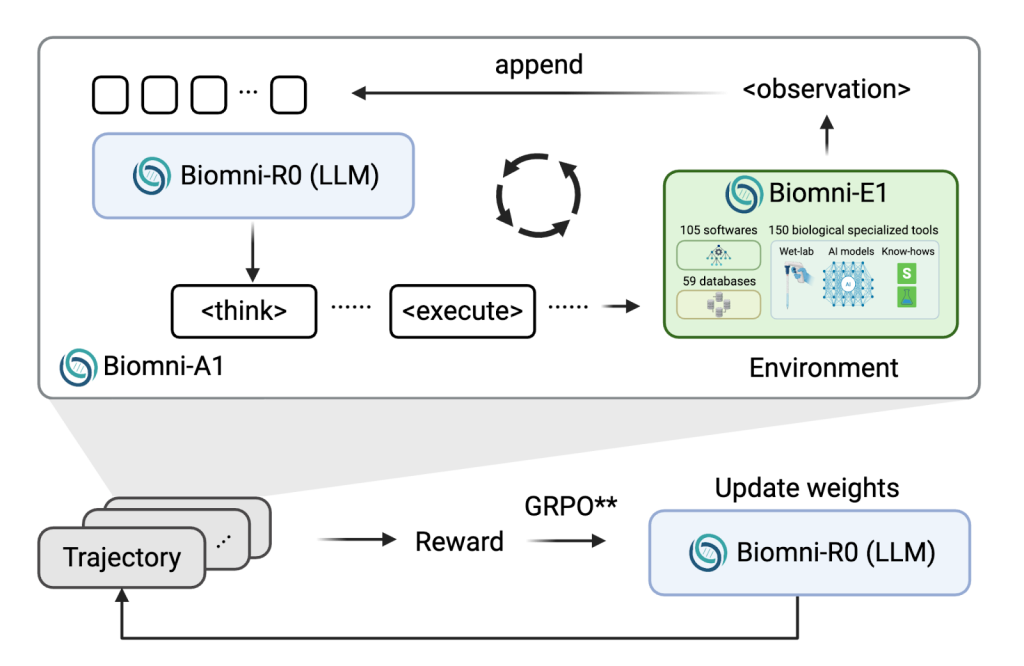
قدم باحثون من جامعة ستانفورد وجامعة كاليفورنيا، بيركلي، عائلة جديدة من النماذج تسمى Biomni-R0، تم بناؤها بتطبيق التعلم المعزز (RL) على أساس وكيل طبي حيوي. تم تدريب هذين النموذجين، Biomni-R0-8B و Biomni-R0-32B، في بيئة تعلم معزز مصممة خصيصاً للتفكير الطبي الحيوي، باستخدام كل من المهام المُعلّمة من قبل الخبراء وهيكل مكافآت جديد. يجمع التعاون بين منصة وكيل Biomni وبيئة ستانفورد وبنية SkyRL للتعلم المعزز من جامعة كاليفورنيا، بيركلي، بهدف دفع النماذج الطبية الحيوية لتجاوز قدرات الإنسان.
استراتيجية التدريب وتصميم النظام
قدم البحث عملية تدريب من مرحلتين. أولاً، استخدموا ضبطاً دقيقاً خاضعاً للإشراف (SFT) على مسارات عالية الجودة تم أخذ عينات منها من Claude-4 Sonnet باستخدام أخذ العينات بالرفض، مما عزز فعلياً قدرة الوكيل على اتباع تنسيقات استدلال منظمة. بعد ذلك، قاموا بضبط النماذج بدقة باستخدام التعلم المعزز، مع التركيز على نوعين من المكافآت: واحدة للصحة (مثل اختيار الجين أو التشخيص الصحيح)، وأخرى لتنسيق الاستجابة (مثل استخدام علامات و المنظمة بشكل صحيح). لضمان الكفاءة الحسابية، قام الفريق بتطوير جدولة تنفيذ غير متزامنة قللت من الاختناقات الناجمة عن تأخيرات الأدوات الخارجية. كما قاموا بتوسيع طول السياق إلى 64000 رمز، مما سمح للوكيل بإدارة محادثات استدلال طويلة متعددة الخطوات بفعالية.
نتائج تتفوق على النماذج الرائدة
كانت مكاسب الأداء كبيرة. حقق Biomni-R0-32B درجة 0.669، وهي قفزة من 0.346 للنموذج الأساسي. حتى Biomni-R0-8B، الإصدار الأصغر، سجل 0.588، متفوقاً على النماذج العامة مثل Claude 4 Sonnet و GPT-5، وكلاهما أكبر بكثير. على أساس كل مهمة، سجل Biomni-R0-32B أعلى درجة في 7 من أصل 10 مهام، بينما تصدر GPT-5 في مهمتين، و Claude 4 في مهمة واحدة فقط. كانت إحدى النتائج الأكثر لفتاً للنظر في تشخيص الأمراض النادرة، حيث وصل Biomni-R0-32B إلى 0.67، مقارنة بـ 0.03 لـ Qwen-32B، وهو تحسن بأكثر من 20 مرة. وبالمثل، في تحديد أولويات متغيرات GWAS، زادت درجة النموذج من 0.16 إلى 0.74، مما يدل على قيمة الاستدلال الخاص بالمجال.
التصميم من أجل القابلية للتطوير والدقة
يتطلب تدريب النماذج الطبية الحيوية الكبيرة التعامل مع عمليات نشر كثيفة الموارد تتضمن تنفيذ أدوات خارجية، واستعلامات قواعد البيانات، وتقييم التعليمات البرمجية. لإدارة هذا، قام النظام بفك اقتران تنفيذ البيئة من استنتاج النموذج، مما يسمح بتوسيع أكثر مرونة ويقلل من وقت وحدة معالجة الرسومات الخامل. كفل هذا الابتكار استخداماً فعالاً للموارد، حتى مع الأدوات التي لديها أوقات انتظار متفاوتة. كما أثبتت تسلسلات الاستدلال الأطول فائدتها. أنتجت النماذج المدربة بواسطة التعلم المعزز استجابات أطول ومنظمة باستمرار، والتي ارتبطت ارتباطاً وثيقاً بأداء أفضل، مما يبرز أن العمق والهيكل في الاستدلال هما مؤشران رئيسيان لفهم الخبراء في الطب الحيوي.
النقاط الرئيسية
- يجب أن تقوم النماذج الطبية الحيوية بالاستدلال العميق، وليس مجرد الاسترجاع، عبر الجينوميات والتشخيص وعلم الأحياء الجزيئي.
- تكمن المشكلة الرئيسية في تحقيق أداء على مستوى الخبراء، خاصة في المجالات المعقدة مثل الأمراض النادرة وتحديد أولويات الجينات.
- غالباً ما تفتقر الأساليب التقليدية، بما في ذلك الضبط الدقيق الخاضع للإشراف والنماذج القائمة على الاسترجاع، إلى المرونة وقابلية التكيف.
- يستخدم Biomni-R0، الذي طورته ستانفورد وبركلي، التعلم المعزز مع مكافآت تعتمد على الخبراء وتنسيق مخرجات منظمة.
- أثبتت خط أنابيب التدريب المكون من مرحلتين، SFT متبوعاً بـ RL، فعاليتها العالية في تحسين الأداء وجودة الاستدلال.
- يقدم Biomni-R0-8B نتائج قوية مع بنية أصغر، بينما يضع Biomni-R0-32B معايير جديدة، متفوقاً على Claude 4 و GPT-5 في 7 من أصل 10 مهام.
- مكّن التعلم المعزز الوكيل من إنشاء مسارات استدلال أطول وأكثر تماسكاً، وهي سمة رئيسية لسلوك الخبراء.
- يضع هذا العمل الأساس لوكلاء طبيين حيويين فائقين، قادرين على أتمتة سير عمل البحث المعقد بدقة.
(يمكن إضافة روابط هنا لمزيد من التفاصيل التقنية، وصفحات GitHub، وتويتر، وغيرها)
مواضيع مشابهة:
 بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه
بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه



اترك تعليقاً