نماذج نيموترون نانو 2 من NVIDIA: ثورة في سرعة ومعالجة نماذج الذكاء الاصطناعي
أعلنت شركة NVIDIA مؤخراً عن عائلة نماذج نيموترون نانو 2 (Nemotron Nano 2)، وهي مجموعة من نماذج اللغات الكبيرة الهجينة القائمة على بنية مamba-Transformer. تمتاز هذه النماذج ليس فقط بدقتها العالية في الاستدلال، بل أيضاً بسرعة استنتاجية تصل إلى 6 أضعاف سرعة نماذج مماثلة في الحجم. وتتميز هذه الإصدارات بقدر غير مسبوق من الشفافية في البيانات والمنهجية، حيث توفر NVIDIA معظم مجموعة البيانات التدريبية والوصفات بالإضافة إلى نقاط تفتيش النموذج للمجتمع. الأهم من ذلك، أن هذه النماذج تحتفظ بقدرة سياقية هائلة تبلغ 128,000 رمز (Token) على وحدة معالجة رسومية متوسطة المدى واحدة، مما يخفض بشكل كبير الحواجز أمام الاستدلال طويل السياق والانتشار في التطبيقات الواقعية.
أبرز مميزات نماذج نيموترون نانو 2:
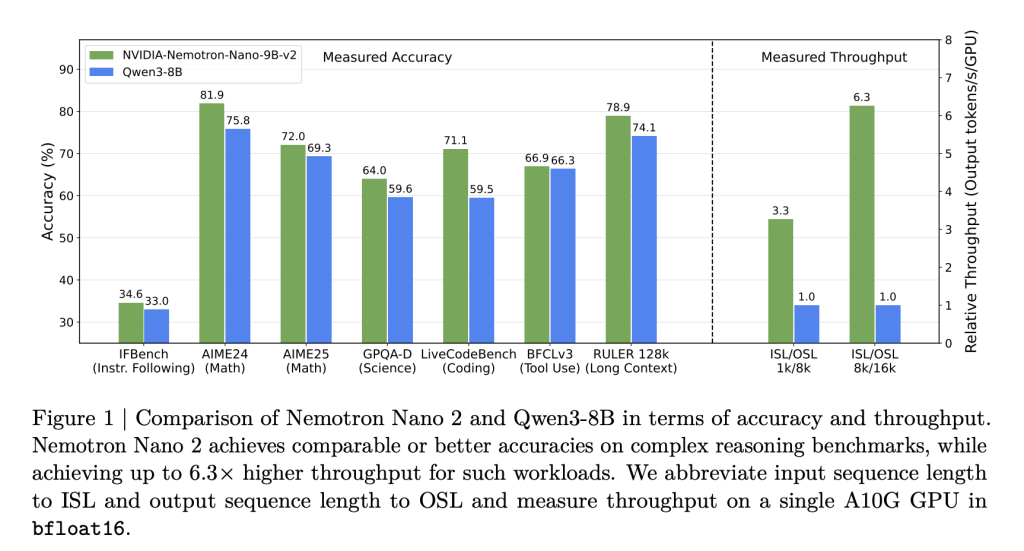
- سرعة استنتاجية عالية: تقدم نماذج نيموترون نانو 2 سرعة توليد رمز تصل إلى 6.3 أضعاف سرعة نماذج مثل Qwen3-8B في سيناريوهات تعتمد بشكل كبير على الاستدلال، وذلك بدون المساومة على الدقة.
- دقة عالية في الاستدلال: أظهرت معايير الأداء نتائج مماثلة أو أفضل من النماذج المفتوحة المصدر المنافسة، متجاوزة بشكل ملحوظ نظيراتها في الرياضيات، والترميز، واستخدام الأدوات، والمهام طويلة السياق.
- سياق طويل على وحدة معالجة رسومية واحدة: يُمكن استخدام تقنية التقليم الفعّالة والهندسة المعمارية الهجينة من تشغيل استنتاج 128,000 رمز على وحدة معالجة رسومية NVIDIA A10G واحدة (22 جيجابايت).
- بيانات وأوزان مفتوحة المصدر: تم إصدار معظم مجموعات البيانات قبل وبعد التدريب، بما في ذلك البيانات المتعلقة بالترميز، والرياضيات، واللغات المتعددة، والبيانات الاصطناعية للتدريب الخاضع للإشراف، وبيانات الاستدلال، برخص استخدام مرخّصة على منصة Hugging Face.
الهندسة المعمارية الهجينة: اندماج Mamba و Transformer
بُنيت نماذج نيموترون نانو 2 على بنية هجينة تجمع بين Mamba و Transformer، مستوحاة من هندسة Nemotron-H. تم استبدال معظم طبقات الاهتمام الذاتي التقليدية بطبقات Mamba-2 الفعّالة، حيث تستخدم حوالي 8% فقط من إجمالي الطبقات الاهتمام الذاتي. تم تصميم هذه الهندسة بعناية:
تفاصيل النموذج:
- يضم النموذج ذو 9 مليارات بارامتر 56 طبقة (من أصل 62 طبقة مدربة مسبقاً)، وحجم مخفي يبلغ 4480، مع اهتمام استعلامي مجمع وطبقات مساحة حالة Mamba-2 التي تُسهّل كل من القابلية للتطوير والاحتفاظ بالتسلسلات الطويلة.
ابتكارات Mamba-2:
تُدمج طبقات مساحة الحالة هذه، التي اشتهرت مؤخراً كنماذج تسلسلية عالية الإنتاجية، مع الاهتمام الذاتي المتناثر (للحفاظ على التبعيات طويلة المدى)، وشبكات التغذية الأمامية الكبيرة. يُمكن هذا الهيكل من تحقيق إنتاجية عالية في مهام الاستدلال التي تتطلب “آثار التفكير” – أجيال طويلة تستند إلى مدخلات طويلة ضمن السياق – حيث غالباً ما تتباطأ أو تنفد ذاكرة الهياكل المعمارية التقليدية القائمة على Transformer.
وصفة التدريب: تنوع البيانات الضخم والمفتوحة المصدر
تم تدريب وتقطير نماذج نيموترون نانو 2 من نموذج مُعلم ذي 12 مليار بارامتر باستخدام مجموعة بيانات واسعة وعالية الجودة. وتُعتبر شفافية البيانات غير المسبوقة من NVIDIA نقطة بارزة:
- 20 تريليون رمز في التدريب المسبق: تتضمن مصادر البيانات مجموعات بيانات مُنسّقة وصناعية من الويب، والرياضيات، والترميز، واللغات المتعددة، والأوساط الأكاديمية، ومجالات العلوم والتكنولوجيا والهندسة والرياضيات.
مجموعات البيانات الرئيسية المُصدرة:
- Nemotron-CC-v2: زحف ويب متعدد اللغات (15 لغة)، إعادة صياغة أسئلة وأجوبة صناعية، وإزالة الازدواجية.
- Nemotron-CC-Math: 133 مليار رمز من محتوى الرياضيات، مُعيار إلى LaTeX، أكثر من 52 مليار رمز من المجموعة الفرعية “الأعلى جودة”.
- Nemotron-Pretraining-Code: شفرة مصدر GitHub مُنسّقة ومرشّحة بجودة عالية؛ إزالة التلوث وإزالة الازدواجية الصارمة.
- Nemotron-Pretraining-SFT: مجموعات بيانات اصطناعية تتبع التعليمات عبر العلوم والتكنولوجيا والهندسة والرياضيات، والاستدلال، والمجالات العامة.
بيانات ما بعد التدريب:
تتضمن أكثر من 80 مليار رمز من الضبط الدقيق الخاضع للإشراف (SFT)، وتعزيز التعلم من خلال التفاعل البشري (RLHF)، واستدعاء الأدوات، ومجموعات بيانات متعددة اللغات – معظمها مفتوح المصدر للتكرار المباشر.
المحاذاة والتقطير والضغط: إطلاق العنان للاستدلال طويل السياق وبتكلفة فعّالة
تعتمد عملية ضغط النموذج من NVIDIA على أطر عمل “Minitron” و Mamba للتقليم:
- يُقلل تقطير المعرفة من النموذج المُعلم ذي 12 مليار بارامتر إلى 9 مليارات بارامتر، مع تقليم دقيق للطبقات، وأبعاد شبكات التغذية الأمامية، وعرض التضمين.
- التدريب الخاضع للإشراف متعدد المراحل وتعزيز التعلم: يشمل تحسين استدعاء الأدوات (BFCL v3)، واتباع التعليمات (IFEval)، وتعزيز DPO و GRPO، والتحكم في “ميزانية التفكير” (دعم ميزانيات رموز الاستدلال القابلة للتحكم في الاستنتاج).
- بحث هندسي معماري مُستهدف للذاكرة: من خلال البحث المعماري، تم تصميم النماذج المُقلمة خصيصاً بحيث يتناسب كل من النموذج وذاكرة التخزين المؤقت الرئيسية – ويبقى أداءه – ضمن ذاكرة وحدة معالجة رسومية A10G بطول سياق 128 ألف رمز. النتيجة: سرعات استنتاج تصل إلى 6 أضعاف سرعة المنافسين المفتوحين المصدر في سيناريوهات ذات رموز إدخال/إخراج كبيرة، دون المساومة على دقة المهمة.
معايير الأداء: قدرات استدلال متفوقة وقدرات متعددة اللغات
في التقييمات المباشرة، تتفوق نماذج نيموترون نانو 2:
| المهمة/المعيار | Nemotron-Nano-9B-v2 | Qwen3-8B | Gemma3-12B |
|---|---|---|---|
| MMLU (عام) | 74.5 | 76.4 | 73.6 |
| MMLU-Pro (5-shot) | 59.4 | 56.3 | 45.1 |
| GSM8K CoT (رياضيات) | 91.4 | 84.0 | 74.5 |
| MATH | 80.5 | 55.4 | 42.4 |
| HumanEval+ | 58.5 | 57.6 | 36.7 |
| RULER-128K (سياق طويل) | 82.2 | – | 80.7 |
| Global-MMLU-Lite (متوسط متعدد اللغات) | 69.9 | 72.8 | 71.9 |
| MGSM رياضيات متعدد اللغات (متوسط) | 84.8 | 64.5 | 57.1 |
الإنتاجية (رموز/ثانية/وحدة معالجة رسومية) عند إدخال 8000 رمز/إخراج 16000 رمز:
- Nemotron-Nano-9B-v2: تصل إلى 6.3 أضعاف Qwen3-8B في آثار الاستدلال. تحافظ على سياق يصل إلى 128 ألف رمز بحجم دفعة = 1 – وهو أمر غير عملي سابقاً على وحدات معالجة رسومية متوسطة المدى.
الخلاصة
يُمثل إصدار NVIDIA لنماذج نيموترون نانو 2 لحظة مهمة في أبحاث نماذج اللغات الكبيرة المفتوحة المصدر: فهو يعيد تعريف ما هو ممكن على وحدة معالجة رسومية واحدة فعّالة من حيث التكلفة – سواء من حيث السرعة أو سعة السياق – بينما يرفع مستوى الشفافية في البيانات وإمكانية التكرار. من المتوقع أن تُسرّع هندستها المعمارية الهجينة، وتفوقها في الإنتاجية، ومجموعات البيانات المفتوحة عالية الجودة الابتكار في جميع أنحاء نظام الذكاء الاصطناعي.






اترك تعليقاً