نماذج غرانيت المُدمجة من IBM: ثورة في استرجاع المعلومات
تُضيف IBM بصمةً قويةً في عالم أنظمة الذكاء الاصطناعي مفتوحة المصدر، وذلك من خلال إصدارها الأخير من نماذج “غرانيت” المُدمجة. تُقدم هذه النماذج حلولاً متقدمةً وفعّالةً في مجال استرجاع المعلومات، مما يجعلها مثاليةً لأنظمة توليد النصوص المُعززة باسترجاع المعلومات (RAG).
نظرة عامة على نماذج غرانيت المُدمجة
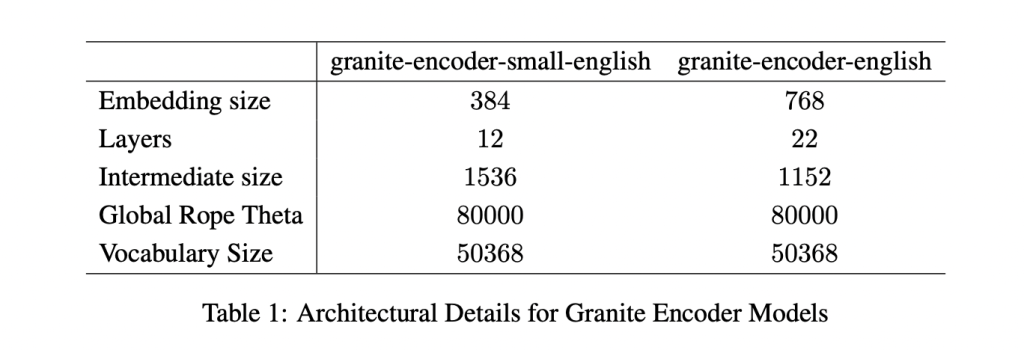
أصدرت IBM نموذجين مُدمجين جديدين هما: granite-embedding-english-r2 و granite-embedding-small-english-r2. يتميز هذان النموذجان بكفاءتهما العالية وحجمهما المُدمج، بالإضافة إلى ترخيصهما تحت رخصة Apache 2.0، مما يسمح باستخدامهما تجاريًا دون قيود.
الاختلافات بين النموذجين:
granite-embedding-english-r2: يحتوي على 149 مليون معلمة، وحجم مُدمج 768، مبني على مُشفّر ModernBERT مكون من 22 طبقة.granite-embedding-small-english-r2: يحتوي على 47 مليون معلمة، وحجم مُدمج 384، مبني على مُشفّر ModernBERT مكون من 12 طبقة.
على الرغم من اختلاف أحجام هذين النموذجين، إلا أنهما يدعمان طول سياق أقصى يصل إلى 8192 رمزًا، وهو تحسين كبير مقارنةً بأجيال غرانيت السابقة. تُعد هذه الميزة مثاليةً للتعامل مع الوثائق الطويلة والمهام المعقدة لاسترجاع المعلومات في بيئات العمل المؤسسية.
العمارة الداخلية لنماذج غرانيت
يعتمد كلا النموذجين على بنية ModernBERT الأساسية، والتي تتضمن العديد من التحسينات، منها:
- التبديل بين الانتباه العام والمحلي: لتحقيق التوازن بين الكفاءة والاعتماد على العلاقات طويلة المدى.
- التضمين الموضعي الدائري (RoPE): مُحسّن لعملية الاستيفاء الموضعي، مما يسمح بنوافذ سياقية أطول.
- FlashAttention 2: لتحسين استخدام الذاكرة والإنتاجية أثناء الاستنتاج.
كما تم تدريب هذين النموذجين باستخدام خط أنابيب متعدد المراحل، بدءًا من التدريب المُقنّع للغة على مجموعة بيانات ضخمة تتكون من تريليوني رمز، مأخوذة من الويب، وويكيبيديا، وPubMed، وBookCorpus، بالإضافة إلى وثائق تقنية داخلية من IBM. تلا ذلك توسيع السياق من 1000 إلى 8000 رمز، والتعلم التبايني مع التقطير من نموذج Mistral-7B، والضبط المحدد للمجال لمهام استرجاع المحادثات، والبيانات الجدولية، والرموز البرمجية.
أداء نماذج غرانيت على معايير الأداء
تُظهر نماذج غرانيت R2 نتائج قوية عبر معايير استرجاع المعلومات المُستخدمة على نطاق واسع. فقد تفوقت granite-embedding-english-r2 على نماذج مُشابهة الحجم مثل BGE Base و E5 و Arctic Embed في اختباري MTEB-v2 و BEIR. أما النموذج الأصغر، granite-embedding-small-english-r2، فقد حقق دقة قريبة من نماذج أكبر منه بحجم يتراوح بين ضعفين وثلاثة أضعاف، مما يجعله مثاليًا للمهام الحساسة للوقت.
كما حققت النماذج أداءً جيدًا في المجالات المتخصصة، مثل:
- استرجاع الوثائق الطويلة: حيث يُعد دعم سياق 8000 رمز أمرًا بالغ الأهمية.
- استرجاع البيانات الجدولية: حيث يُطلب المنطق المُبني على الهياكل.
- استرجاع الرموز البرمجية: مع التعامل مع استعلامات النص إلى الرمز والرمز إلى النص.
سرعة وكفاءة نماذج غرانيت
تُعد الكفاءة من أبرز سمات هذين النموذجين. فعلى معالج رسومات Nvidia H100، يُشفّر granite-embedding-small-english-r2 ما يقارب 200 وثيقة في الثانية، وهو أسرع بكثير من BGE Small و E5 Small. كما يصل granite-embedding-english-r2 إلى 144 وثيقة في الثانية، متفوقًا على العديد من البدائل القائمة على ModernBERT. الأهم من ذلك، أن هذه النماذج تعمل بكفاءة على وحدات المعالجة المركزية (CPUs)، مما يسمح للمؤسسات بتشغيلها في بيئات أقل اعتمادًا على معالجات الرسومات.
خاتمة
تُمثل نماذج غرانيت المُدمجة من IBM حلًا مثاليًا للمؤسسات التي تبحث عن حلول فعّالة في مجال استرجاع المعلومات. فهي تجمع بين التصميم المُدمج، ودعم السياق الطويل، ودقة استرجاع المعلومات العالية، والإنتاجية المُحسّنة لكل من معالجات الرسومات ووحدات المعالجة المركزية، بالإضافة إلى ترخيص Apache 2.0 الذي يسمح باستخدامها تجاريًا دون قيود.
لمزيد من المعلومات، يُرجى زيارة: رابط الورقة البحثية و [رابط صفحة GitHub](رابط صفحة GitHub)
مواضيع مشابهة:
 DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
 بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena
بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena


اترك تعليقاً