خوارزميات جوجل الذكية لحماية الخصوصية في اختيار التقسيمات بتقنية التعلم الآلي
تُعدُّ الخصوصية التفاضلية (DP) المعيار الذهبي لحماية معلومات المستخدمين في أنظمة التعلم الآلي وتحليلات البيانات الضخمة. وتُشكّل عملية اختيار التقسيمات مهمةً بالغة الأهمية ضمن الخصوصية التفاضلية، حيث تهدف إلى استخراج أكبر مجموعة ممكنة من العناصر الفريدة من مجموعات بيانات ضخمة يساهم فيها المستخدمون (مثل الاستعلامات أو رموز المستندات)، مع الحفاظ على ضمانات الخصوصية الصارمة. يُقدّم فريق من الباحثين من معهد ماساتشوستس للتكنولوجيا (MIT) وبحث جوجل للذكاء الاصطناعي خوارزميات جديدة لاختيار التقسيمات مع الحفاظ على الخصوصية التفاضلية، وهي تقنية تهدف إلى تعظيم عدد العناصر الفريدة المختارة من اتحاد مجموعات البيانات، مع الحفاظ على خصوصية المستخدم على مستوى الفرد.
مشكلة اختيار التقسيمات في الخصوصية التفاضلية
تطرح مشكلة اختيار التقسيمات السؤال التالي: كيف يمكننا الكشف عن أكبر عدد ممكن من العناصر المميزة من مجموعة البيانات، دون المخاطرة بخصوصية أي فرد؟ يجب أن تظل العناصر المعروفة لمستخدم واحد فقط سرية؛ ولا يمكن الكشف إلا عن تلك العناصر التي تحظى بدعم كافٍ من “مصادر متعددة”. وتُشكّل هذه المشكلة أساس تطبيقات مهمة مثل:
- استخراج المفردات و n-grams الخاصة بمهام معالجة اللغة الطبيعية.
- تحليل البيانات الفئوية وحساب الهستوجرام.
- التعلم المحافظ على الخصوصية للرموز على عناصر مقدمة من المستخدم.
- إخفاء الاستعلامات الإحصائية (مثل الاستعلامات على محركات البحث أو قواعد البيانات).
النهج التقليدية وحدودها
عادةً ما تتضمن الحلول التقليدية (المستخدمة في مكتبات مثل PyDP وأدوات جوجل للخصوصية التفاضلية) ثلاث خطوات:
- الوزن: يحصل كل عنصر على “درجة”، عادةً ما تكون تردده بين المستخدمين، مع وضع حد صارم لمساهمة كل مستخدم.
- إضافة الضوضاء: لإخفاء نشاط المستخدم الدقيق، يتم إضافة ضوضاء عشوائية (عادةً غاوسية) إلى وزن كل عنصر.
- العتبة: يتم إصدار العناصر التي تتجاوز درجتها الضوضائية عتبة محددة – مُحسوبة من معلمات الخصوصية (ε، δ).
هذه الطريقة بسيطة وقابلة للتوزيع بشكل كبير، مما يسمح لها بالتوسع إلى مجموعات بيانات عملاقة باستخدام أنظمة مثل MapReduce وHadoop أو Spark. ومع ذلك، فهي تعاني من عدم كفاءة أساسية: تتراكم العناصر الشائعة وزنًا زائدًا لا يُساعد على تعزيز الخصوصية، بينما غالبًا ما تُغفل العناصر الأقل شيوعًا ولكنها قد تكون قيّمة لأن الوزن الزائد لا يتم إعادة توجيهه لمساعدتها على تجاوز العتبة.
الوزن التكيفي وخوارزمية MaxAdaptiveDegree (MAD)
يُقدّم بحث جوجل أول خوارزمية اختيار تقسيمات قابلة للتكيف ومتوازية – MaxAdaptiveDegree (MAD) – وامتداد متعدد الجولات MAD2R، المصمم لمجموعات بيانات ضخمة للغاية (مئات المليارات من الإدخالات).
المساهمات التقنية الرئيسية:
- إعادة الوزن التكيفي: تحدد MAD العناصر التي يزيد وزنها بكثير عن عتبة الخصوصية، وتعيد توجيه الوزن الزائد لتعزيز العناصر الأقل تمثيلًا. يزيد هذا “الوزن التكيفي” من احتمالية الكشف عن العناصر النادرة ولكن القابلة للمشاركة، وبالتالي تعظيم فائدة الإخراج.
- ضمانات الخصوصية الصارمة: تحافظ آلية إعادة التوجيه على نفس متطلبات الحساسية والضوضاء مثل الوزن المنتظم الكلاسيكي، مما يضمن الخصوصية التفاضلية (ε، δ) على مستوى المستخدم ضمن نموذج DP المركزي.
- القابليّة للتوسّع: تتطلب MAD و MAD2R عملًا خطيًا فقط في حجم مجموعة البيانات وعددًا ثابتًا من الجولات المتوازية، مما يجعلها متوافقة مع أنظمة معالجة البيانات الضخمة الموزعة. لا تحتاج إلى وضع جميع البيانات في الذاكرة وتدعم التنفيذ الفعال متعدد الأجهزة.
- التحسين متعدد الجولات (MAD2R): من خلال تقسيم ميزانية الخصوصية بين الجولات واستخدام الأوزان الضوضائية من الجولة الأولى للتحيز في الجولة الثانية، يعزز MAD2R الأداء بشكل أكبر، مما يسمح باستخراج المزيد من العناصر الفريدة بأمان – خاصة في التوزيعات طويلة الذيل النموذجية للبيانات الواقعية.
كيفية عمل MAD – التفاصيل الخوارزمية
- الوزن المنتظم الأولي: يشارك كل مستخدم عناصره بدرجة أولية موحدة، مما يضمن حدود الحساسية.
- تشذيب الوزن الزائد وإعادة توجيهه: يتم تقليم الوزن الزائد للعناصر التي تتجاوز “عتبة تكيّفية” وإعادة توجيهها بالتناسب إلى المستخدمين المساهمين، الذين يعيدون توزيعها على عناصرهم الأخرى.
- ضبط الوزن النهائي: يتم إضافة وزن موحد إضافي لتعويض أخطاء التخصيص الأولية الصغيرة.
- إضافة الضوضاء والإخراج: يتم إضافة ضوضاء غاوسية؛ ويتم إخراج العناصر التي تتجاوز العتبة الضوضائية. في MAD2R، يتم استخدام مخرجات الجولة الأولى والأوزان الضوضائية لتحسين العناصر التي يجب التركيز عليها في الجولة الثانية، مع ضمان عدم وجود فقدان للخصوصية وتعظيم فائدة الإخراج.
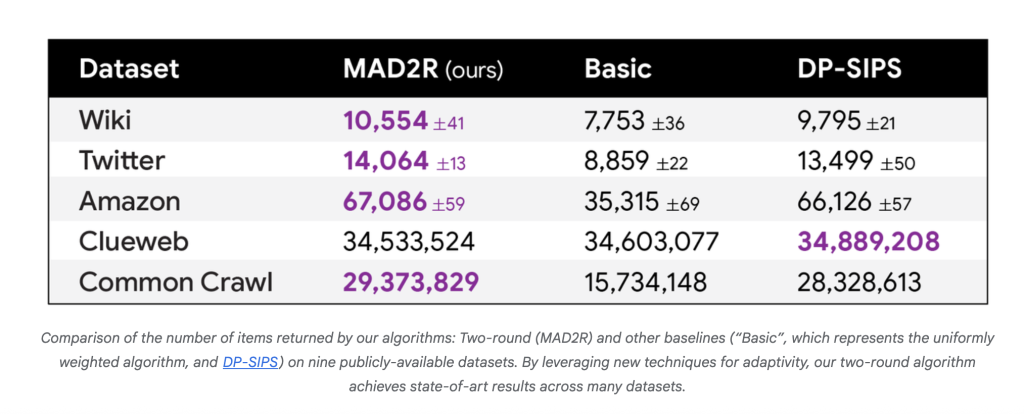
النتائج التجريبية: الأداء المتقدم
أظهرت التجارب المكثفة عبر تسع مجموعات بيانات (من Reddit و IMDb و Wikipedia و Twitter و Amazon، وصولاً إلى Common Crawl مع ما يقرب من تريليون إدخال):
- تفوق MAD2R على جميع المقاييس الأساسية المتوازية (Basic، DP-SIPS) في سبع مجموعات بيانات من أصل تسع مجموعات من حيث عدد العناصر التي تم إخراجها عند معلمات خصوصية ثابتة.
- في مجموعة بيانات Common Crawl، استخرج MAD2R 16.6 مليون عنصر من 1.8 مليار عنصر فريد (0.9٪)، لكنها غطت 99.9٪ من المستخدمين و 97٪ من جميع أزواج المستخدم/العنصر في البيانات – مما يدل على فائدة عملية رائعة مع الحفاظ على الخصوصية.
- بالنسبة لمجموعات البيانات الأصغر، يقترب أداء MAD من أداء الخوارزميات التسلسلية غير القابلة للتوسع، وبالنسبة لمجموعات البيانات الضخمة، يفوز بوضوح من حيث السرعة والفائدة.
مثال ملموس: فجوة الفائدة
لننظر في سيناريو يحتوي على عنصر “ثقيل” (مشترك بشكل شائع جدًا) والعديد من العناصر “الخفيفة” (مشتركة من قبل عدد قليل من المستخدمين). يعطي اختيار DP الأساسي وزنًا زائدًا للعنصر الثقيل دون رفع العناصر الخفيفة بما يكفي لتجاوز العتبة. يُعيد MAD تخصيص الوزن بشكل استراتيجي، مما يزيد من احتمالية إخراج العناصر الخفيفة وينتج عنه ما يصل إلى 10٪ من العناصر الفريدة المكتشفة مقارنة بالنهج القياسي.
الخلاصة
بفضل الوزن التكيفي والتصميم المتوازي، يرفع فريق البحث اختيار تقسيمات DP إلى مستويات جديدة من حيث القابلية للتوسع والفائدة. تضمن هذه التطورات أن الباحثين والمهندسين يمكنهم الاستفادة الكاملة من البيانات الخاصة، واستخراج المزيد من الإشارات دون المساس بخصوصية المستخدم الفردية.
مواضيع مشابهة:
 توليد محولات LoRA من النص: ثورة في تكييف نماذج اللغات الكبيرة
نماذج MiniCPM4 اللغوية: كفاءة عالية على الأجهزة الطرفية
بناء مُجرف ويب متقدم باستخدام BrightData و Gemini من جوجل لاستخراج البيانات بذكاء اصطناعي
نموذج عالمي برمجي متعدد الوحدات يتفوق على تقنيات التعلم المعزز في لعبة “مونتي زوما الانتقام”
توليد محولات LoRA من النص: ثورة في تكييف نماذج اللغات الكبيرة
نماذج MiniCPM4 اللغوية: كفاءة عالية على الأجهزة الطرفية
بناء مُجرف ويب متقدم باستخدام BrightData و Gemini من جوجل لاستخراج البيانات بذكاء اصطناعي
نموذج عالمي برمجي متعدد الوحدات يتفوق على تقنيات التعلم المعزز في لعبة “مونتي زوما الانتقام”



اترك تعليقاً