تقنية NVIDIA Sortformer: ثورة في تمييز المتحدثين في الوقت الفعلي
تُعلن NVIDIA عن إطلاق تقنية Streaming Sortformer، وهي نقلة نوعية في مجال تمييز المتحدثين في الوقت الفعلي. تُحدد هذه التقنية وتُسمي المشاركين في الاجتماعات والمكالمات والتطبيقات الصوتية على الفور، حتى في البيئات الصاخبة التي تضم العديد من المتحدثين. تم تصميم النموذج للاستدلال ذي التأخير المنخفض المدعوم بوحدة معالجة الرسومات (GPU)، وهو مُحسّن للعمل باللغتين الإنجليزية والصينية الماندرين، ويمكنه تتبع ما يصل إلى أربعة متحدثين في وقت واحد بدقة تصل إلى مستوى الميلي ثانية. يمثل هذا الابتكار خطوة كبيرة إلى الأمام في مجال الذكاء الاصطناعي المُحاور، مما يُمكّن جيلًا جديدًا من تطبيقات الإنتاجية والامتثال والتفاعل الصوتي.
الميزات الرئيسية لـ Streaming Sortformer
-
التتبع متعدد المتحدثين في الوقت الفعلي: على عكس أنظمة التمييز التقليدية التي تتطلب معالجة دفعات البيانات أو أجهزة متخصصة باهظة الثمن، يقوم Streaming Sortformer بتمييز الإطار على مستوى الإطار في الوقت الفعلي. هذا يعني أن كل جملة مُعلّمة بعلامة مُتحدث (مثل spk_0، spk_1) وعلامة توقيت دقيقة أثناء سير المحادثة. يتميز النموذج بتأخير منخفض، حيث يُعالج الصوت في أجزاء صغيرة متداخلة – وهي ميزة أساسية للنسخ الحي، والمساعدين الذكيين، وتحليلات مراكز الاتصال حيث تُعد كل ميلي ثانية مهمة.
-
تصنيف 2-4+ متحدثين على الفور: يتتبع النموذج بثبات ما يصل إلى أربعة مشاركين لكل محادثة، ويُعيّن علامات مُتناسقة مع دخول كل متحدث إلى التدفق.
-
الاستدلال المُعجل بمعالجة الرسومات (GPU): تم تحسينه بالكامل لوحدات معالجة الرسومات من NVIDIA، ويتكامل بسلاسة مع منصتي NVIDIA NeMo و NVIDIA Riva لنشر قابل للتطوير على مستوى الإنتاج.
-
دعم متعدد اللغات: على الرغم من أنه مُحسّن للغة الإنجليزية، إلا أن النموذج يُظهر نتائج قوية على بيانات اجتماعات اللغة الصينية الماندرين، وحتى على مجموعات بيانات غير إنجليزية مثل CALLHOME، مما يُشير إلى توافق لُغوي واسع يتجاوز أهدافه الأساسية.
-
الدقة والموثوقية: يُقدّم النموذج معدل خطأ في التمييز (DER) تنافسي، متفوقًا على البدائل الحديثة مثل EEND-GLA و LS-EEND في معايير الأداء الواقعية.
تُجعل هذه الإمكانات Streaming Sortformer مفيدًا على الفور لنقل الاجتماعات الحية، وسجلات امتثال مراكز الاتصال، وتناوب دور الروبوتات الصوتية، وتحرير الوسائط، وتحليلات المؤسسات – كلها سيناريوهات يكون فيها معرفة “من قال ماذا، ومتى” أمرًا ضروريًا.
بنية الابتكار في Streaming Sortformer
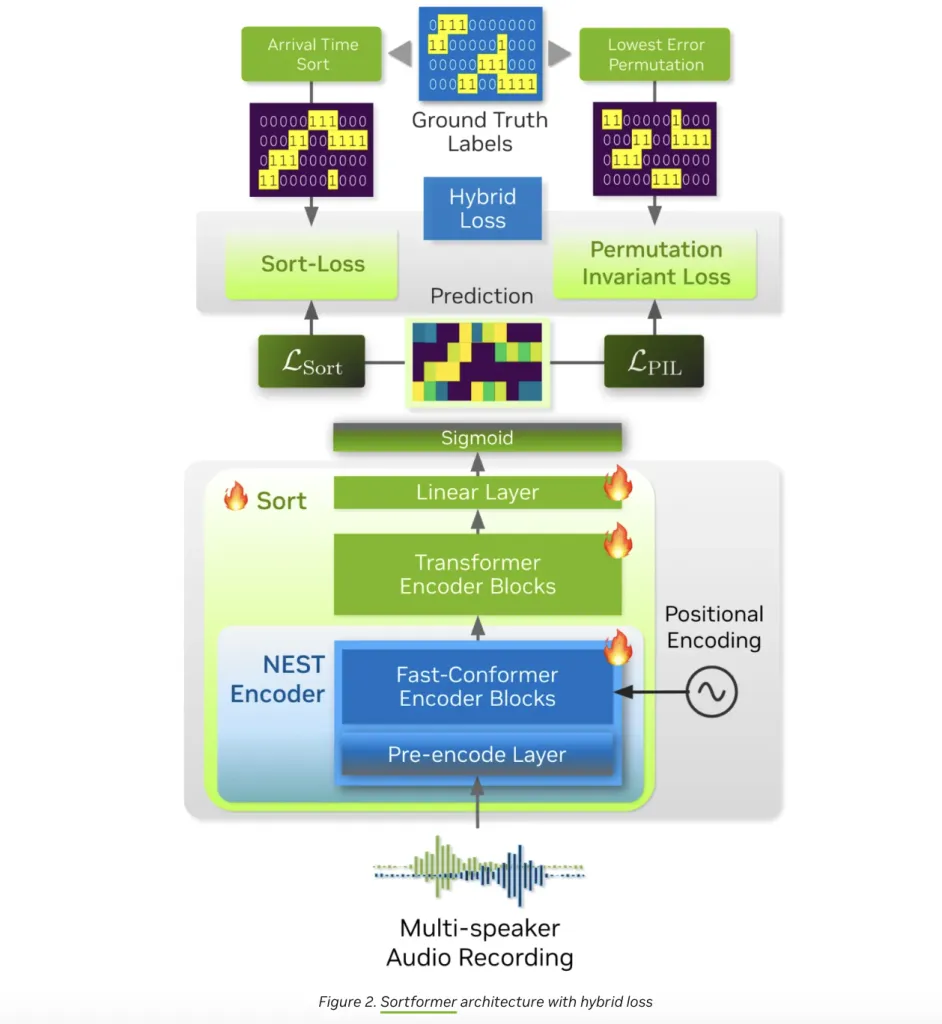
في جوهره، Streaming Sortformer هو بنية عصبية هجينة، تجمع بين نقاط القوة لشبكات الأعصاب التلافيفية (CNNs)، و Conformers، و Transformers. إليك كيفية عمله:
-
معالجة الصوت الأولية: تقوم وحدة ترميز أولية تلافيفية بضغط الصوت الخام إلى تمثيل مُدمج، مع الحفاظ على الميزات الصوتية الأساسية مع تقليل العبء الحسابي.
-
الفرز المُدرك للسياق: يقوم مُشفر Fast-Conformer متعدد الطبقات (17 طبقة في النسخة المُتدفقة) بمعالجة هذه الميزات، واستخراج مُدخلات خاصة بالمتحدث. ثم يتم تغذية هذه المُدخلات إلى مُشفر Transformer من 18 طبقة بحجم مُخفي قدره 192، تليها طبقتان مُتقدمتان ذات مخرجات سينية لكل إطار.
-
ذاكرة تخزين مُتحدثي الوصول حسب الترتيب (AOSC): هنا تحدث السّحرة الحقيقية. يُحافظ Streaming Sortformer على مُخزن مُؤقت ديناميكي للذاكرة – AOSC – يُخزن مُدخلات جميع المتحدثين المُكتشفين حتى الآن. مع وصول أجزاء صوتية جديدة، يُقارن النموذج هذه الأجزاء مع ذاكرة التخزين المؤقت، مما يُضمن أن يحتفظ كل مشارك بعلامة مُتناسقة طوال المحادثة. هذا الحل الأنيق لمشكلة تبديل المُتحدثين هو ما يُمكّن التتبع متعدد المتحدثين في الوقت الفعلي دون إعادة الحساب باهظة الثمن.
-
التدريب الشامل: على عكس بعض خطوط أنابيب التمييز التي تعتمد على خطوات منفصلة لاكتشاف نشاط الصوت وتجميعه، يتم تدريب Sortformer بشكل شامل، حيث يوحد فصل المتحدثين والتصنيف في شبكة عصبية واحدة.
التكامل والنشر
Streaming Sortformer مفتوح، وجاهز للإنتاج، وجاهز للتكامل في سير العمل الحالي. يمكن للمطورين نشره عبر NVIDIA NeMo أو Riva، مما يجعله بديلاً مباشرًا لأنظمة التمييز القديمة. يقبل النموذج صوتًا أحادي القناة 16 كيلو هرتز قياسيًا (ملفات WAV) ويُخرج مصفوفة من احتمالات نشاط المُتحدث لكل إطار – مثالي لبناء تحليلات مخصصة أو خطوط أنابيب للنسخ.
التطبيقات العملية
يتمثل التأثير العملي لـ Streaming Sortformer في:
-
الاجتماعات والإنتاجية: إنشاء نصوص وملخصات مُعلّمة بالمتحدثين على الهواء مباشرة، مما يُسهّل متابعة المناقشات وتعيين عناصر العمل.
-
مراكز الاتصال: فصل تدفقات الصوت الخاصة بالوكيل والعميل لضمان الامتثال، وضمان الجودة، والتدريب في الوقت الفعلي.
-
الروبوتات الصوتية والمساعدون الاصطناعيون: تمكين حوارات أكثر طبيعية ووعيًا بالسياق من خلال تتبع هوية المتحدث وأنماط تناوب الدور بدقة.
-
الوسائط والإذاعة: تصنيف المتحدثين تلقائيًا في التسجيلات لتحرير سير العمل والنسخ والتعديل.
-
امتثال المؤسسات: إنشاء سجلات قابلة للمراجعة، مُحلّلة حسب المتحدث، لتلبية المتطلبات التنظيمية والقانونية.
أداء المعايير والقيود
في معايير الأداء، يحقق Streaming Sortformer معدل خطأ في التمييز (DER) أقل من أنظمة التمييز المُتدفقة الحديثة، مما يُشير إلى دقة أعلى في الظروف الواقعية. ومع ذلك، تم تحسين النموذج حاليًا لسياقات تضم ما يصل إلى أربعة متحدثين؛ يظل التوسع في مجموعات أكبر مجالًا للبحث في المستقبل. قد يختلف الأداء أيضًا في البيئات الصوتية الصعبة أو مع اللغات غير المُمثلة تمثيلاً كافيًا، على الرغم من أن مرونة البنية تُشير إلى إمكانية التكيّف مع توفر بيانات تدريب جديدة.
لمحة سريعة عن أهم النقاط التقنية
| الميزة | Streaming Sortformer |
|---|---|
| الحد الأقصى للمتحدثين | 2-4+ |
| التأخير | منخفض (وقت حقيقي، على مستوى الإطار) |
| اللغات | الإنجليزية (محسّنة)، الماندرين (مُعتمدة)، غيرها مُمكنة |
| البنية | CNN + Fast-Conformer + Transformer + AOSC |
| التكامل | NVIDIA NeMo، NVIDIA Riva، Hugging Face |
| المخرجات | علامات مُتحدث على مستوى الإطار، طوابع زمنية دقيقة |
| دعم وحدة معالجة الرسومات (GPU) | نعم (مطلوب وحدات معالجة رسومات NVIDIA) |
| مفتوح المصدر | نعم (نماذج مُدرّبة مسبقًا، قاعدة شفرة) |
الخلاصة
لا يمثل Streaming Sortformer من NVIDIA مجرد عرض تقني – بل هو أداة جاهزة للإنتاج تُغيّر بالفعل كيفية تعامل المؤسسات والمطورون ومقدمو الخدمات مع الصوت متعدد المتحدثين. بفضل تسريع وحدة معالجة الرسومات، والتكامل السلس، والأداء القوي عبر اللغات، من المقرر أن يصبح المعيار الفعلي لتمييز المتحدثين في الوقت الفعلي في عام 2025 وما بعده. بالنسبة إلى مديري الذكاء الاصطناعي، ومُنشئي المحتوى، ومسوقي المحتوى الرقمي الذين يركزون على تحليلات المحادثات، أو البنية التحتية السحابية، أو تطبيقات الصوت، فإن Streaming Sortformer هو منصة يجب تقييمها. يُعد مزيجها من السرعة والدقة وسهولة النشر خيارًا مُقنعًا لأي شخص يُنشئ الجيل التالي من المنتجات المُمكّنة بالصوت.






اترك تعليقاً