تحويل نماذج التنبؤ بالمتسلسلات الزمنية إلى مُتعلمين ذوي طلقات قليلة باستخدام الضبط الدقيق ضمن السياق
يُقدم هذا المقال شرحًا مفصلاً لنهج جديد ثوري من جوجل للتعامل مع مشكلة التنبؤ بالمتسلسلات الزمنية، والذي يُمكّن نماذج التعلم الآلي من تحقيق دقة عالية باستخدام عدد قليل جدًا من الأمثلة. يعتمد هذا النهج على تقنية “الضبط الدقيق ضمن السياق” (ICF) المُطبقة على نموذج TimesFM، مما يُحوّله إلى مُتعلم ذي طلقات قليلة (Few-Shot Learner).
التحدي: التوازن بين الدقة وفعالية العمليات
تواجه عمليات التنبؤ بالمتسلسلات الزمنية تحديًا رئيسيًا يتمثل في التوازن بين دقة النتائج وفعالية العمليات. فمن ناحية، نجد نماذج مُدرّبة بشكل مُشرف لكل مجموعة بيانات على حدة (Supervised Fine-Tuning)، والتي تُحقق دقة عالية ولكنها تتطلب جهدًا كبيرًا في عمليات التشغيل والصيانة (MLOps). ومن ناحية أخرى، توجد النماذج الأساسية (Zero-Shot Foundation Models) التي تتميز ببساطة استخدامها، لكنها تفتقر إلى التكيّف مع مجالات تطبيق محددة.
الحل: الضبط الدقيق ضمن السياق (ICF)
يُقدم نهج جوجل الجديد حلاً وسطًا مثاليًا من خلال تقنية الضبط الدقيق ضمن السياق (ICF) المُطبقة على نموذج TimesFM. فهو يُبقي على نقطة فحص مُدرّبة مسبقًا واحدة (Pre-trained Checkpoint) من TimesFM، لكنه يُمكّنه من التكيّف بسرعة باستخدام عدد قليل من الأمثلة ضمن السياق من متسلسلات ذات صلة خلال عملية الاستنتاج، مما يتجنب الحاجة إلى تدريب منفصل لكل مجموعة بيانات.
آلية عمل الضبط الدقيق ضمن السياق
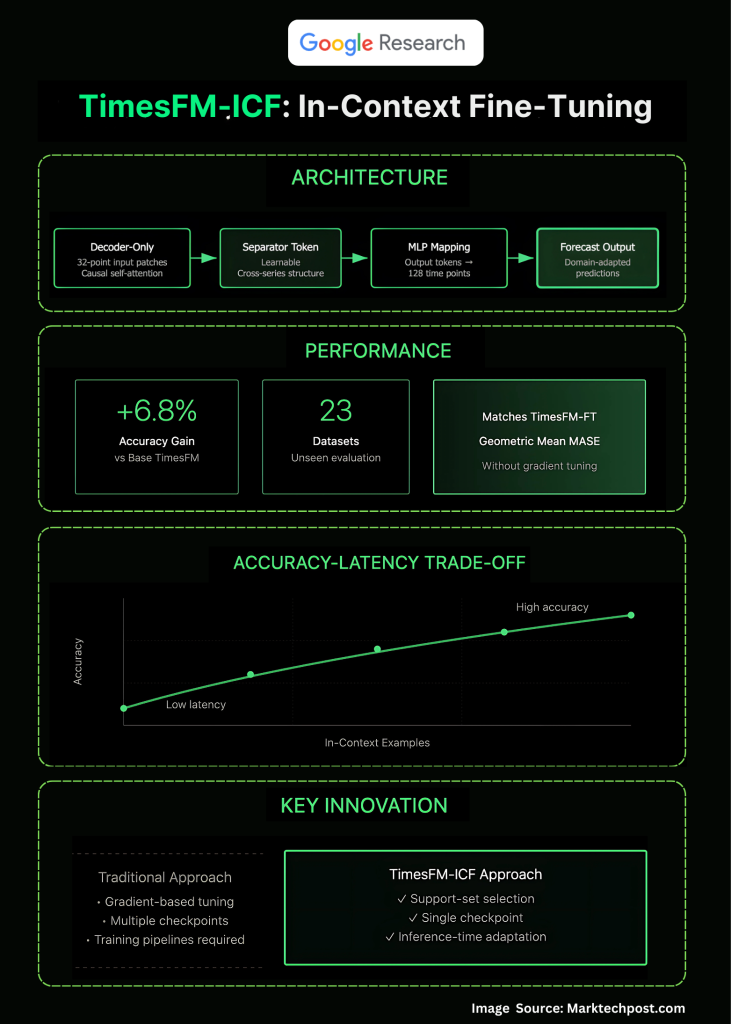
يعتمد هذا النهج على المُعالجة المُستمرة المُسبقة (Continued Pre-training) لنموذج TimesFM، وهو مُحوّل مُشفّر فقط (Decoder-Only Transformer) مُعدّل. تتم هذه المُعالجة باستخدام متسلسلات تُدمج بين سجلات البيانات المُستهدفة ومتسلسلات بيانات داعمة (Support Series) مُفصولة بعلامة فاصلة قابلة للتعلم. يُساعد هذا على تمكين الانتباه السببي (Causal Attention) من استخراج الهياكل بين الأمثلة دون الخلط بين الاتجاهات.
ما المقصود بـ “المُتعلم ذي الطلقات القليلة” هنا؟
خلال عملية الاستنتاج، يقوم المستخدم بدمج سجلات البيانات المُستهدفة مع مقاطع من متسلسلات زمنية إضافية (مثل منتجات مُشابهة أو أجهزة استشعار مُجاورة)، مُفصولة بعلامة الفاصلة. تكون طبقات الانتباه مُدرّبة بشكل صريح على الاستفادة من هذه الأمثلة ضمن السياق، بشكل مشابه لطريقة عمل النماذج اللغوية الكبيرة (LLMs) في الاستنتاج القائم على عدد قليل من الأمثلة، ولكن مع متسلسلات رقمية بدلاً من الرموز النصية. هذا يُحوّل عملية التكيّف من تحديث المعلمات إلى هندسة المُطالبات على المتسلسلات المُهيكلة.
مقارنة مع تقنيات الضبط الدقيق المُشرف
أظهرت النتائج أن تقنية ICF تُحقق أداءً مُماثلاً للضبط الدقيق المُشرف لكل مجموعة بيانات على حدة، بل وتتفوق عليه بنسبة 6.8% مقارنةً بنموذج TimesFM الأساسي، وذلك باستخدام متوسط هندسي مُقاس بـ MASE. كما أظهرت النتائج التوازن المتوقع بين الدقة وزمن الاستجابة: فكلما زاد عدد الأمثلة ضمن السياق، زادت دقة التنبؤات، ولكن على حساب زيادة زمن الاستجابة.
الاختلاف عن أساليب Chronos
على عكس أساليب Chronos التي تعتمد على تحويل القيم إلى مُفردات منفصلة، فإن مساهمة جوجل هنا لا تقتصر على مُحسّن جديد أو تحسينات في الأداء بدون تدريب. بل إنها تتمثل في تمكين نموذج المُتسلسلات الزمنية من العمل كـ مُتعلم ذي طلقات قليلة، مُستفيداً من سياق المتسلسلات المُتعددة خلال عملية الاستنتاج. هذه القدرة تُقلّص الفجوة بين التكيّف أثناء التدريب والتكيّف أثناء عملية الاستنتاج للتنبؤات الرقمية.
المواصفات المعمارية الهامة
تُبرز الدراسة الجوانب المعمارية التالية:
- استخدام علامات فاصلة لفصل الحدود بين الأمثلة.
- استخدام الانتباه الذاتي السببي على السجلات المُختلطة والأمثلة.
- الحفاظ على تقنية التصحيح (Patching) ورؤوس MLP المُشتركة.
- المُعالجة المُستمرة المُسبقة لغرس سلوك استغلال الأمثلة المُتعددة.
هذه العناصر مجتمعة تُمكّن النموذج من معاملة المتسلسلات الداعمة كأمثلة مُفيدة بدلاً من ضوضاء خلفية.
الخلاصة
يُحوّل الضبط الدقيق ضمن السياق من جوجل نموذج TimesFM إلى مُتعلم عملي ذي طلقات قليلة: نقطة فحص مُدرّبة مسبقًا واحدة تتكيّف خلال عملية الاستنتاج عبر متسلسلات داعمة مُختارة بعناية، مما يُحقق دقة مُماثلة للضبط الدقيق المُشرف دون الحاجة إلى تدريب منفصل لكل مجموعة بيانات. هذا يُعدّ مفيدًا بشكل خاص في عمليات النشر المُتعددة المُستخدمين والتي تخضع لقيود زمنية، حيث يصبح اختيار مجموعات الدعم هو السطح الرئيسي للتحكم.
أسئلة شائعة
-
ما هو “الضبط الدقيق ضمن السياق” (ICF) من جوجل للمتسلسلات الزمنية؟
ICF هو تدريب مُستمر يُكيّف نموذج TimesFM لاستخدام متسلسلات مُتعددة ذات صلة مُوضوعة في المُطالبة أثناء الاستنتاج، مما يُمكّن التكيّف باستخدام عدد قليل من الأمثلة دون تحديثات مُتدرّجة لكل مجموعة بيانات. -
كيف يختلف ICF عن الضبط الدقيق القياسي والاستخدام بدون تدريب؟
يُحدث الضبط الدقيق القياسي تحديثات للأوزان لكل مجموعة بيانات، بينما يستخدم النموذج بدون تدريب نموذجًا ثابتًا مع سجلات البيانات المُستهدفة فقط. يُبقي ICF الأوزان ثابتة عند النشر، لكنه يتعلم خلال التدريب المُسبق كيفية الاستفادة من الأمثلة الإضافية ضمن السياق، مُحققًا أداءً مُماثلاً للضبط الدقيق لكل مجموعة بيانات على حدة. -
ما هي التغييرات المعمارية أو التدريبية المُدخلة؟
تم تدريب TimesFM مُستمرًا باستخدام متسلسلات تُدمج بين سجلات البيانات المُستهدفة ومتسلسلات البيانات الداعمة، مُفصولة بعلامات فاصلة خاصة بحيث يُمكن للانتباه السببي استغلال الهيكل بين المتسلسلات؛ بينما يظل باقي نموذج TimesFM المُشفّر فقط كما هو. -
ماذا تُظهر النتائج مقارنةً بالخطوط الأساسية؟
على مجموعات البيانات الخارجية، يُحسّن ICF من أداء نموذج TimesFM الأساسي ويُحقق أداءً مُماثلاً للضبط الدقيق المُشرف؛ وقد تم تقييمه مقابل خطوط أساسية قوية للمتسلسلات الزمنية (مثل PatchTST) ونماذج المُحولات السابقة (مثل Chronos).




اترك تعليقاً