تحسين مذهل في تخطيط الذكاء الاصطناعي من باحثي معهد ماساتشوستس للتكنولوجيا
حقق باحثون في مختبر علوم الكمبيوتر والذكاء الاصطناعي (CSAIL) بمعهد ماساتشوستس للتكنولوجيا (MIT) قفزة نوعية في مجال تخطيط الذكاء الاصطناعي، حيث تمكنوا من تحسين أداء نماذج اللغات الكبيرة في هذا المجال بشكلٍ كبير. استخدم الفريق إطار عمل جديد أطلقوا عليه اسم “PDDL-INSTRUCT” ليحققوا نتائج مذهلة، تصل إلى زيادة قدرها ٦٤ ضعفًا في بعض الحالات، ودقة بلغت ٩٤٪ في بعض الاختبارات.
مشكلة التخطيط في نماذج اللغات الكبيرة:
تعاني نماذج اللغات الكبيرة من مشكلة شائعة تتمثل في توليد خطط تبدو منطقية في ظاهرها، ولكنها في الواقع غير صالحة من الناحية المنطقية. يهدف إطار عمل PDDL-INSTRUCT إلى معالجة هذه المشكلة من خلال ربط دلالات الحالة والعمل بشكلٍ صريح مع التحقق من صحة النتائج.
آلية عمل PDDL-INSTRUCT:
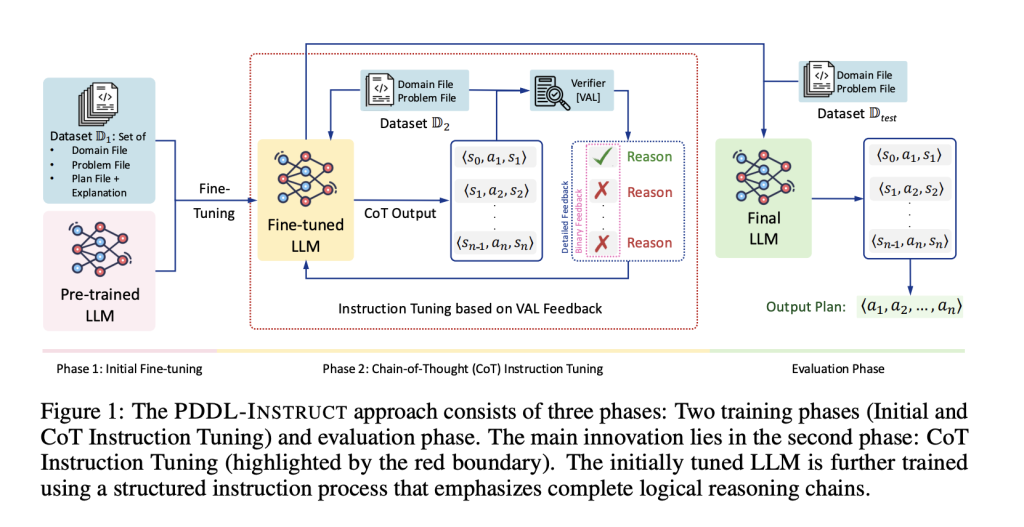
يتمثل إطار عمل PDDL-INSTRUCT في ثلاث خطوات رئيسية:
-
تعليم الأخطاء: يتم تدريب النموذج على شرح أسباب فشل الخطط المقترحة، سواء كانت بسبب شروط مسبقة غير مُرضاة، أو تأثيرات خاطئة، أو انتهاكات للإطار، أو عدم تحقيق الهدف.
-
سلسلة التفكير المنطقية (CoT): تتطلب المطالبات استنتاجًا خطوة بخطوة عبر الشروط المسبقة وإضافة/حذف التأثيرات، مما ينتج عنه تتبعات لحالة-عمل-حالة ⟨sᵢ, aᵢ₊₁, sᵢ₊₁⟩.
-
التحقق الخارجي (VAL): يتم التحقق من صحة كل خطوة باستخدام مُحقق خطط VAL الكلاسيكي؛ يمكن أن تكون التغذية الراجعة ثنائية (صحيح/خاطئ) أو مفصلة (أي شرط مسبق/تأثير فشل). أدت التغذية الراجعة المفصلة إلى أقوى المكاسب.
كما يتضمن الإطار عملية تحسين من مرحلتين:
- المرحلة الأولى: تُحسّن سلاسل الاستدلال (مع معاقبة أخطاء انتقال الحالة).
- المرحلة الثانية: تُحسّن دقة تخطيط المهمة النهائية.
النتائج: اختبارات مُذهلة
تم تقييم أداء PDDL-INSTRUCT باستخدام مجموعة بيانات PlanBench، والتي تتضمن اختبارات صعبة مثل: Blocksworld، وMystery Blocksworld (حيث تم إخفاء أسماء المُسندات لمنع مطابقة الأنماط)، وLogistics. وقد أظهرت النتائج تحسينات كبيرة:
- Blocksworld: وصلت دقة الخطط الصالحة إلى ٩٤٪ باستخدام نموذج Llama-3-8B.
- Mystery Blocksworld: تحسينات كبيرة جدًا، حيث تم الإبلاغ عن تحسن هائل مقارنةً بِخط الأساس (٦٤ ضعفًا).
- Logistics: زيادات كبيرة في عدد الخطط الصالحة.
بشكل عام، أظهرت النتائج تحسينًا مطلقًا يصل إلى ٦٦٪ مقارنةً بالخطوط الأساسية غير المُحسّنة. كما أن التغذية الراجعة المُفصّلة من المُحقق تفوقت على الإشارات الثنائية، كما أن زيادة ميزانية التغذية الراجعة ساعدت أكثر.
الخلاصة:
يُظهر PDDL-INSTRUCT أن اقتران سلسلة التفكير المنطقية مع التحقق الخارجي من الخطط يمكن أن يُحسّن بشكلٍ كبير من تخطيط نماذج اللغات الكبيرة. على الرغم من أن نطاقه الحالي يقتصر على مجالات PDDL الكلاسيكية (Blocksworld، Mystery Blocksworld، Logistics) ويعتمد على VAL كمُحقق خارجي، إلا أن المكاسب المُبلغ عنها -مثل ٩٤٪ من الخطط الصالحة في Blocksworld والتحسينات الكبيرة في Mystery Blocksworld مع Llama-3-8B- تُظهر مسارًا قابلًا للتطبيق للتدريب العصبي الرمزي حيث تكون خطوات الاستدلال مُرسّخة في دلالات رسمية ويتم التحقق منها تلقائيًا. يُشير هذا إلى فائدة فورية لأنابيب الوكيل التي يمكنها تحمل مُحقق في الحلقة، بينما تظل التخطيطات طويلة الأمد والزمانية/الرقمية والحساسة للتكلفة امتدادات مفتوحة.







اترك تعليقاً