التعلم المعزز: حلٌٌّ لمشكلة “النسيان الكارثي” في نماذج الذكاء الاصطناعي الضخمة
تُعاني نماذج الذكاء الاصطناعي الضخمة، رغم تميزها في مجالات متعددة، من مشكلة “النسيان الكارثي” عند إعادة تدريبها على مهام جديدة. تُشير دراسة جديدة من معهد ماساتشوستس للتكنولوجيا (MIT) إلى أن التعلم المعزز (Reinforcement Learning – RL) يُعدّ حلاًّ فعالاً لهذه المشكلة مقارنةً بالضبط الدقيق المُشرف (Supervised Fine-Tuning – SFT). سنستعرض في هذا المقال تفاصيل هذه الدراسة، ونُلقي الضوء على أهم النتائج والتوصيات.
ماهية النسيان الكارثي في نماذج الذكاء الاصطناعي الأساسية؟
تتميز النماذج الأساسية للذكاء الاصطناعي بقدراتها المتنوعة، إلا أنها غالباً ما تكون ثابتة بعد نشرها. يُسبب الضبط الدقيق على مهام جديدة ما يُعرف بـ”النسيان الكارثي”، وهو فقدان القدرات المكتسبة سابقاً. تُشكل هذه القيود عائقاً أمام بناء وكلاء ذكاء اصطناعي متطورين وقادرين على التعلم المستمر.
لماذا يُسبب التعلم المعزز نسياناً أقل من الضبط الدقيق المُشرف؟
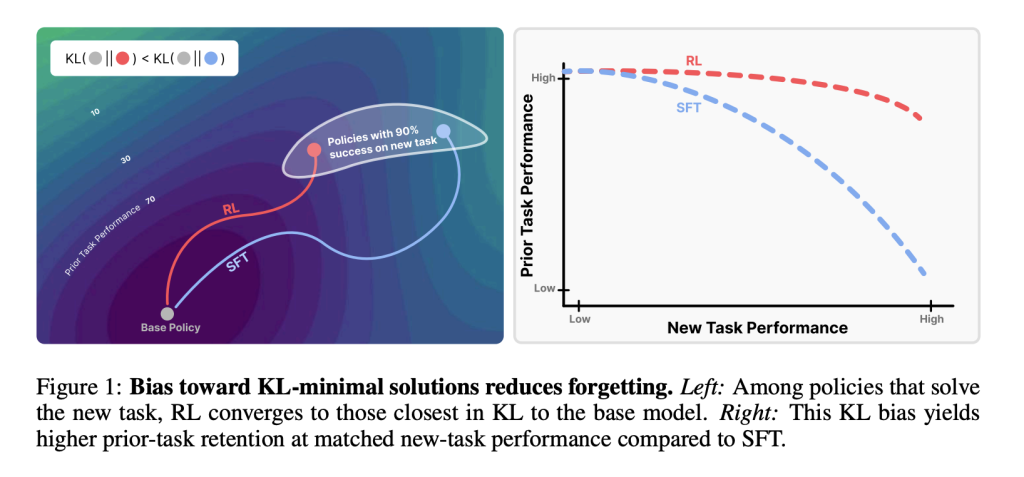
قارنت دراسة MIT بين التعلم المعزز والضبط الدقيق المُشرف. يُحقق كلاهما أداءً عالياً في المهام الجديدة، لكن الضبط الدقيق المُشرف غالباً ما يُعيد كتابة القدرات السابقة. على النقيض، يحافظ التعلم المعزز على هذه القدرات. يكمن السر في كيفية تغيير كل منهما لتوزيع مُخرجات النموذج بالنسبة إلى السياسة الأساسية. (رابط الدراسة)
كيف يمكن قياس النسيان؟
اقترح فريق البحث قانون نسيان تجريبيًا:
نسيان ∝ KL(π₀ || π)
حيث π₀ هو النموذج الأساسي و π هو النموذج المُضبّط بدقة. يُتوقع مدى النسيان بقوة من خلال تباعد KL الأمامي (Forward KL Divergence) المُقاس على المهمة الجديدة. يُسهّل هذا قياس النسيان دون الحاجة إلى بيانات من المهام السابقة.
ماذا كشفت التجارب على النماذج اللغوية الكبيرة؟
باستخدام نموذج Qwen 2.5 3B-Instruct كنموذج أساسي، تم إجراء ضبط دقيق على:
- الاستدلال الرياضي (Open-Reasoner-Zero)
- الأسئلة والأجوبة العلمية (مجموعة فرعية من SciKnowEval)
- استخدام الأدوات (ToolAlpaca)
تم تقييم الأداء على معايير سابقة مثل HellaSwag، و MMLU، و TruthfulQA، و HumanEval. أظهرت النتائج أن التعلم المعزز حسّن دقة المهام الجديدة مع الحفاظ على دقة المهام السابقة ثابتة، بينما ضحى الضبط الدقيق المُشرف باستمرار بالمعرفة السابقة.
كيف يُقارن التعلم المعزز بالضبط الدقيق المُشرف في مهام الروبوتات؟
في تجارب التحكم في الروبوتات مع OpenVLA-7B المُضبّط بدقة في سيناريوهات “التقاط ووضع” في SimplerEnv، حافظ التكيّف باستخدام التعلم المعزز على مهارات التلاعب العامة عبر المهام. بينما نجح الضبط الدقيق المُشرف في المهمة الجديدة، إلا أنه قلّل من قدرات التلاعب السابقة، مُوضحاً مرة أخرى حفاظ التعلم المعزز على المعرفة.
ماذا تُشير دراسة ParityMNIST؟
لَعزل الآليات، أدخل فريق البحث مشكلة مصغّرة، ParityMNIST. هنا، حقق كل من التعلم المعزز والضبط الدقيق المُشرف دقة عالية في المهام الجديدة، لكن الضبط الدقيق المُشرف تسبب في انخفاض حاد في معيار FashionMNIST المساعد. بشكل حاسم، كشف رسم النسيان مقابل تباعد KL عن منحنى تنبؤي واحد، مُؤكداً أن تباعد KL هو العامل الحاكم.
لماذا تُعتبر التحديثات “ضمن السياسة” مهمة؟
تُجري تقنيات التعلم المعزز “ضمن السياسة” أخذ عينات من مُخرجات النموذج الخاصة به، مُعاد وزنها تدريجياً حسب المكافأة. تقيد هذه العملية التعلم بالتوزيعات القريبة بالفعل من النموذج الأساسي. على النقيض، يُحسّن الضبط الدقيق المُشرف ضد تسميات ثابتة قد تكون بعيدة بشكل تعسفي. يُظهر التحليل النظري أن متجهات السياسة تتقارب مع الحلول المثالية المُصغّرة لـ KL، مُحدّدة ميزة التعلم المعزز.
هل هناك تفسيرات أخرى كافية؟
اختبر فريق البحث بدائل: تغييرات مساحة الأوزان، وتغيّر التمثيل الخفي، وندرة التحديثات، ومقاييس توزيعية بديلة (KL العكسي، والاختلاف الكلي، ومسافة L2). لم يُطابق أي منها قوة التنبؤ لتباعد KL الأمامي، مُعززاً أن القرب التوزيعي هو العامل الحاسم.
الآثار الأوسع نطاقاً
- التقييم: يجب أن يُراعي التقييم ما بعد التدريب حفاظ KL على التوزيع، وليس فقط دقة المهمة.
- الطرق الهجينة: يمكن أن يُحقق الجمع بين كفاءة الضبط الدقيق المُشرف والحد الأدنى من KL المُصرح به أفضل التوازنات.
- التعلم المستمر: يُوفر “مبدأ التعلم المعزز” معياراً قابلاً للقياس لتصميم وكلاء مُتكيّفين يتعلمون مهارات جديدة دون محو القدرات القديمة.
الخلاصة
أعادت دراسة MIT صياغة النسيان الكارثي كمشكلة توزيعية تحكمها تباعد KL الأمامي. يُسبب التعلم المعزز نسياناً أقل لأن تحديثاته “ضمن السياسة” تُميل بشكل طبيعي نحو الحلول المُصغّرة لـ KL. يُوفر هذا المبدأ – “مبدأ التعلم المعزز” – شرحاً لمتانة التعلم المعزز وخريطة طريق لتطوير طرق ما بعد التدريب التي تدعم التعلم مدى الحياة في نماذج الذكاء الاصطناعي الأساسية.
النقاط الرئيسية
- يحافظ التعلم المعزز على المعرفة السابقة بشكل أفضل من الضبط الدقيق المُشرف: حتى عندما يحقق كلاهما نفس الدقة في المهام الجديدة، يحتفظ التعلم المعزز بالقدرات السابقة بينما يُمحوها الضبط الدقيق المُشرف.
- يمكن التنبؤ بالنسيان من خلال تباعد KL: يرتبط مدى النسيان الكارثي ارتباطاً وثيقاً بتباعد KL الأمامي بين السياسة المُضبّطة بدقة والسياسة الأساسية، المُقاس على المهمة الجديدة.
- مبدأ “مبدأ التعلم المعزز”: تتقارب تحديثات التعلم المعزز “ضمن السياسة” نحو الحلول المُصغّرة لـ KL، مما يضمن بقاء التحديثات قريبة من النموذج الأساسي ويُقلل من النسيان.
- التحقق التجريبي عبر المجالات: تُؤكد التجارب على النماذج اللغوية الكبيرة (الرياضيات، والأسئلة والأجوبة العلمية، واستخدام الأدوات) ومهام الروبوتات متانة التعلم المعزز ضد النسيان، بينما يُضحي الضبط الدقيق المُشرف باستمرار بالمعرفة القديمة من أجل أداء المهام الجديدة.
- تُؤكد التجارب المُتحكم بها على العمومية: في إعداد ParityMNIST المصغر، أظهر كل من التعلم المعزز والضبط الدقيق المُشرف نسياناً مُتوافقاً مع تباعد KL، مُثبتاً أن المبدأ ينطبق على النماذج واسعة النطاق.
- محور التصميم المُستقبلي لما بعد التدريب: يجب تقييم الخوارزميات ليس فقط من خلال دقة المهمة الجديدة، ولكن أيضاً من خلال مدى محافظة تحويل التوزيعات في مساحة KL، مما يُفتح آفاقاً لطرق هجينة تجمع بين التعلم المعزز والضبط الدقيق المُشرف.
مواضيع مشابهة:
 DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
 بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena
بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena



اترك تعليقاً