إطار عمل Prefix-RFT: دمج متطور لضبط النماذج اللغوية الكبيرة
يُعَدّ ضبط نماذج اللغات الكبيرة بعد مرحلة ما قبل التدريب عملية بالغة الأهمية لتحسين أدائها. ويتم ذلك عادةً باستخدام إحدى طريقتين رئيسيتين: ضبط النموذج المُشرف (SFT) أو ضبط النموذج المعزز (RFT)، ولكل منهما نقاط قوة وضعف مميزة.
ضبط النموذج المُشرف (SFT) وضبط النموذج المعزز (RFT): مقارنة وتحديات
-
ضبط النموذج المُشرف (SFT): يُعدّ فعالاً في تعليم النموذج اتباع التعليمات من خلال التعلم القائم على الأمثلة. لكنّه قد يؤدي إلى سلوك جامد وضعف في التعميم.
-
ضبط النموذج المعزز (RFT): يُحسّن أداء النموذج لتحقيق أهداف محددة باستخدام إشارات المكافآت. وهذا يُحسّن الأداء، لكنّه قد يُدخِل عدم استقرار واعتمادًا كبيرًا على سياسة بدء قوية.
غالباً ما تُستخدم هاتان الطريقتان بشكل متسلسل، إلا أن تفاعلهما لا يزال غير مفهوم جيداً. وهذا يطرح سؤالاً مهماً: كيف يمكننا تصميم إطار عمل موحد يجمع بين بنية SFT والتعلم القائم على الأهداف في RFT؟
لقد اكتسب البحث في تقاطع التعلم المعزز ونماذج اللغات الكبيرة بعد التدريب زخمًا كبيرًا، خاصةً لتدريب نماذج قادرة على الاستدلال. غالباً ما ينتج عن التعلم المعزز غير المتصل (Offline RL)، الذي يتعلم من مجموعات بيانات ثابتة، سياسات دون المستوى الأمثل نظرًا للتنوع المحدود للبيانات. وقد أثار هذا اهتمامًا بدمج مناهج التعلم المعزز غير المتصل والمتصل لتحسين الأداء.
في نماذج اللغات الكبيرة، تتمثل الاستراتيجية السائدة في تطبيق SFT أولاً لتعليم السلوكيات المرغوبة، ثم استخدام RFT لتحسين النتائج. ومع ذلك، لا تزال الديناميكيات بين SFT و RFT غير مفهومة جيدًا، ويظل إيجاد طرق فعالة لدمجها تحديًا مفتوحًا للبحث.
إطار عمل Prefix-RFT: الحل المُبتكر
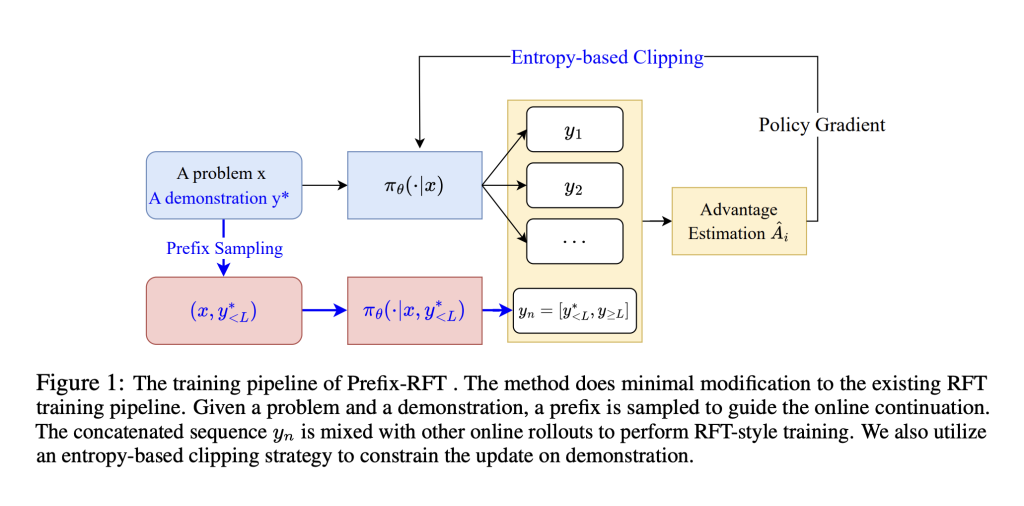
يقترح باحثون من جامعة إدنبرة وجامعة فودان ومجموعة علي بابا وStepfun وجامعة أمستردام إطار عمل موحد يُدمج ضبط النموذج المُشرف والمعزز بطريقة تُسمى Prefix-RFT. تقوم هذه الطريقة بإرشاد عملية الاستكشاف باستخدام عروض جزئية (Prefixes)، مما يسمح للنموذج بمواصلة توليد الحلول بمرونة وقابلية للتكيف.
مميزات Prefix-RFT:
- أداء متفوق: يتفوق Prefix-RFT باستمرار على كل من SFT و RFT وطرق السياسات المختلطة في مهام الاستدلال الرياضي.
- سهولة التكامل: يتكامل بسهولة مع الأطر الموجودة.
- متانة عالية: يُظهر متانة عالية تجاه التغيرات في جودة وكمية العروض.
- دمج التعلم القائم على العروض مع الاستكشاف: يؤدي إلى تدريب أكثر فعالية وقابلية للتكيف لنماذج اللغات الكبيرة.
آلية عمل Prefix-RFT:
يُعدّ Prefix-RFT طريقة ضبط معززة تُحسّن الأداء باستخدام مجموعات بيانات رياضية عالية الجودة، مثل OpenR1-Math-220K (46 ألف مشكلة مُصفّاة). تم اختباره على نماذج Qwen2.5-Math-7B و 1.5B و LLaMA-3.1-8B، وتم تقييمه على معايير قياسية تشمل AIME 2024/25 و AMC و MATH500 و Minerva و OlympiadBench. حقق Prefix-RFT أعلى متوسط درجات avg@32 و pass@1 عبر المهام، متفوقاً على RFT و SFT و ReLIFT و LUFFY.
النتائج والتطبيقات
باستخدام تقنية Dr. GRPO، تم تحديث أفضل 20% من رموز البادئة عالية الانتروبيا فقط، مع انخفاض طول البادئة من 95% إلى 5%. حافظ على متوسط خسارة SFT المتوسطة، مما يشير إلى توازن قوي بين التقليد والاستكشاف، خاصةً في المشاكل الصعبة.
حتى مع 1% فقط من بيانات التدريب (450 مطالبة)، حافظ على أداء قوي (انخفضت avg@32 من 40.8 إلى 37.6 فقط)، مما يُظهر الكفاءة والمتانة. وقد أثبتت استراتيجية تحديث الرموز القائمة على أعلى 20% من الانتروبيا فعاليتها، محققةً أعلى درجات المعايير القياسية مع مخرجات أقصر. علاوة على ذلك، فإن استخدام جدول زمني لانحلال جيب التمام لطول البادئة يُعزز الاستقرار وديناميكيات التعلم مقارنةً باستراتيجية موحدة، خاصةً في المهام المعقدة مثل AIME.
المصادر والروابط
يمكنك الاطلاع على الورقة البحثية هنا: رابط الورقة البحثية
يمكنك أيضًا زيارة صفحة GitHub الخاصة بنا للحصول على دروس تعليمية، أكواد، ودفاتر ملاحظات: [رابط صفحة GitHub]
تابعونا على تويتر: [رابط تويتر]
انضم إلى مجتمعنا على Reddit: [رابط Reddit]
اشترك في قائمتنا البريدية: [رابط القائمة البريدية]






اترك تعليقاً