وكيل جوجل الذكي: إعادة صياغة مساعدة الواقع المعزز
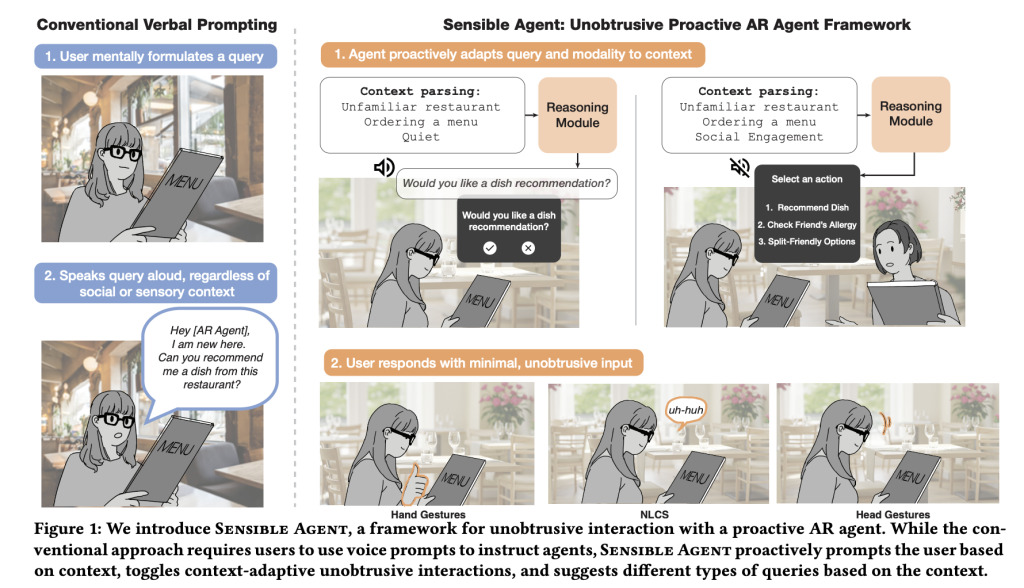
يُقدم بحث جوجل الجديد، “الوكيل الذكي”، إطار عمل ونظامًا أوليًا للذكاء الاصطناعي يختار كلًا من الإجراء الذي يجب أن يتخذه وكيل الواقع المعزز (AR) وطريقة التفاعل لتوصيله/تأكيده، وذلك بناءً على سياق متعدد الوسائط في الوقت الفعلي (مثل، انشغال اليدين، الضوضاء المحيطة، الوضع الاجتماعي). وبدلاً من معالجة “ما يجب اقتراحه” و”كيف يُسأل” كمُشكلتين منفصلتين، يحسبهما معًا لتقليل الاحتكاك والإحراج الاجتماعي في المواقف الواقعية.
التحديات التي يستهدفها النظام
تُعاني الطرق التقليدية المعتمدة على الصوت من قصور كبير، فهي بطيئة تحت ضغط الوقت، وغير قابلة للاستخدام عند انشغال اليدين أو العينين، ومحرجة في الأماكن العامة. يركز “الوكيل الذكي” على أنَّ الاقتراح عالي الجودة المُقدم من خلال القناة الخاطئة يُعتبر ضوضاءً فعليًا.
تصميم النظام وعملياته
يُنفذ النموذج الأولي على سماعة رأس XR من فئة Android خط أنابيب يتكون من ثلاث مراحل رئيسية:
- تحليل السياق: يُدمج هذا الجزء الصور الذاتية المركزية (الاستدلال المرئي اللغوي للمشهد/النشاط/المعرفة) مع مُصنف صوتي بيئي (YAMNet) لاكتشاف ظروف مثل الضوضاء أو المحادثة.
- توليد الاستعلامات الاستباقية: يُحفز هذا الجزء نموذجًا متعدد الوسائط كبيرًا باستخدام أمثلة قليلة لإختيار الإجراء، وهيكل الاستعلام (ثنائي/اختيار متعدد/إشارة رمزية)، وطريقة العرض.
- طبقة التفاعل: تُمكّن هذه الطبقة فقط طرق الإدخال المتوافقة مع توافر مدخلات/مخرجات المُحسّسة، مثل إشارة برأس للإجابة “نعم” عندما لا يكون الهمس مقبولاً، أو التحديق عندما تكون اليدين مشغولة.
مصادر سياسات الأمثلة القليلة
استخدم الفريق دراستين لتحديد سياسات الأمثلة القليلة:
- ورشة عمل الخبراء (n=12): لتحديد متى تكون المساعدة الاستباقية مفيدة، وما هي مدخلات التفاعل الصغيرة المقبولة اجتماعيًا.
- دراسة تعيين السياق (n=40؛ 960 مدخلًا): عبر سيناريوهات يومية (مثل، صالة رياضية، بقالة، متحف، تنقل، طهي) حيث حدد المشاركون الإجراءات المطلوبة من الوكيل واختاروا نوع الاستعلام وطريقة التفاعل المُفضلة بالنظر إلى السياق.
تُرسخ هذه الخرائط الأمثلة القليلة المُستخدمة في وقت التشغيل، مُحولة اختيار “ماذا وكيف” من الخوارزميات العشوائية إلى أنماط مُشتقة من البيانات (مثل، الاختيار المتعدد في البيئات غير المألوفة، الاختيار الثنائي تحت ضغط الوقت، الرمز المرئي في الإعدادات الحساسة اجتماعيًا).
تقنيات التفاعل
يدعم النموذج الأولي تقنيات تفاعل متعددة:
- التأكيد الثنائي: التعرف على إيماءات الرأس (إيماء/هز).
- الخيارات المتعددة: نظام إمالة الرأس لربط اليسار/اليمين/الخلف بالخيارات 1/2/3.
- إيماءات الأصابع: تحديد رقمي وإبهام لأعلى/لأسفل.
- التحديق: تشغيل أزرار مرئية حيث يكون التوجيه باستخدام الشعاع صعبًا.
- الكلام المختصر: (“نعم”، “لا”، “واحد”، “اثنان”، “ثلاثة”).
- الاصوات غير اللفظية: (“مم هم”) في السياقات الصاخبة أو الهمس.
تقليل تكلفة التفاعل
أظهرت دراسة أولية للمستخدمين (n=10) مقارنة الإطار مع خط أساس قائم على الصوت عبر الواقع المعزز وواقع افتراضي 360 درجة انخفاضًا في الجهد المُدرك للتفاعل وانخفاضًا في التطفل مع الحفاظ على سهولة الاستخدام والتفضيل.
الجانب الصوتي وYAMNet
يستخدم YAMNet، وهو مُصنف أحداث صوتية خفيف الوزن قائم على MobileNet-v1 مُدرب على مجموعة بيانات AudioSet من جوجل، للكشف بسرعة عن الظروف المحيطة (وجود الكلام، الموسيقى، ضوضاء الحشد) للتحكم في الإشارات الصوتية أو للتحيز نحو التفاعل المرئي/الإيماءات عندما يكون الكلام محرجًا أو غير موثوق به.
التكامل مع أنظمة المساعدة الحالية
تتضمن خطة التبني الحد الأدنى:
- استخدام مُحلل سياق خفيف الوزن.
- إنشاء جدول أمثلة قليلة لخرائط السياق→(الإجراء، نوع الاستعلام، الطريقة).
- تحفيز نموذج لغة كبير لإصدار “ماذا” و”كيف” في وقت واحد.
- عرض طرق الإدخال الممكنة فقط لكل حالة والحفاظ على التوكيدات ثنائية بشكل افتراضي.
- تسجيل الخيارات والنتائج لتعلم السياسات دون اتصال.
الخلاصة
يُشغّل “الوكيل الذكي” الواقع المعزز الاستباقي كمشكلة سياسة مُقترنة – اختيار الإجراء وطريقة التفاعل في قرار واحد مُشروط بالسياق – ويُصدق النهج بنموذج أولي فعال لـ WebXR ودراسة صغيرة للمستخدمين تُظهر انخفاضًا في جهد التفاعل المُدرك مقارنةً بخط أساس صوتي. مساهمة الإطار ليست منتجًا بل وصفة قابلة للتكاثر: مجموعة بيانات من خرائط السياق→(ماذا/كيف)، مطالبات قليلة الربط في وقت التشغيل، وبدائيات إدخال منخفضة الجهد تحترم القيود الاجتماعية ومدخلات/مخرجات النظام.






اترك تعليقاً