نموذج dots.ocr: معالجة متقدمة للوثائق متعددة اللغات
يُقدم هذا المقال لمحة شاملة عن نموذج dots.ocr، وهو نموذج مفتوح المصدر لتحويل الرؤية واللغة، مصمم خصيصاً لتحليل تخطيط الوثائق ومعالجة التعرف الضوئي على الحروف (OCR) بلغات متعددة. يتميز هذا النموذج بدمج كفاءة التعرف على تخطيط الوثيقة مع استخراج محتواها في بنية واحدة، مما يوفر حلًا متكاملاً وفعالًا.
بنية النموذج وإمكانياته
- بنية موحدة: يعتمد dots.ocr على شبكة عصبية تحويلية (Transformer) تجمع بين اكتشاف تخطيط الوثيقة والتعرف على محتواها في هيكل واحد. هذه البنية المبتكرة تقلل من التعقيد الموجود في أنظمة المعالجة التقليدية التي تعتمد على خطوات منفصلة، مما يسمح للمستخدمين بالتبديل بين المهام بسهولة عن طريق تعديل الإرشادات المدخلة.
- عدد المعلمات: يحتوي النموذج على 1.7 مليار معلمة، مما يوفر توازنًا مثاليًا بين الكفاءة الحسابية والأداء العالي في معظم السيناريوهات العملية.
- مرونة المدخلات: يدعم النموذج تنسيقات مختلفة للمدخلات، بما في ذلك ملفات الصور (مثل JPEG و PNG) وملفات PDF. كما يوفر خيارات ما قبل المعالجة، مثل
fitz_preprocess، لتحسين جودة المعالجة للوثائق ذات الدقة المنخفضة أو الوثائق متعددة الصفحات ذات الكثافة العالية.
قدرات متعددة اللغات ودقة عالية
- دعم متعدد اللغات: تم تدريب dots.ocr على مجموعات بيانات تغطي أكثر من 100 لغة، بما في ذلك اللغات العالمية الرئيسية واللغات الأقل شيوعًا، مما يعكس دعمًا واسعًا للغات المتعددة.
- استخراج المحتوى: يستخرج النموذج النص العادي، والبيانات الجدولية، والصيغ الرياضية (بصيغة LaTeX)، مع الحفاظ على ترتيب القراءة داخل الوثائق. كما يدعم تنسيقات مُخرجات متنوعة تشمل JSON المُبَنى، و Markdown، و HTML، حسب تخطيط المحتوى ونوعه.
- الحفاظ على البنية: يحافظ dots.ocr على بنية الوثيقة الأصلية، بما في ذلك حدود الجداول، ومناطق الصيغ، ومواقع الصور، مما يضمن أن البيانات المُستخرجة تُحافظ على دقة وثبات البيانات الأصلية.
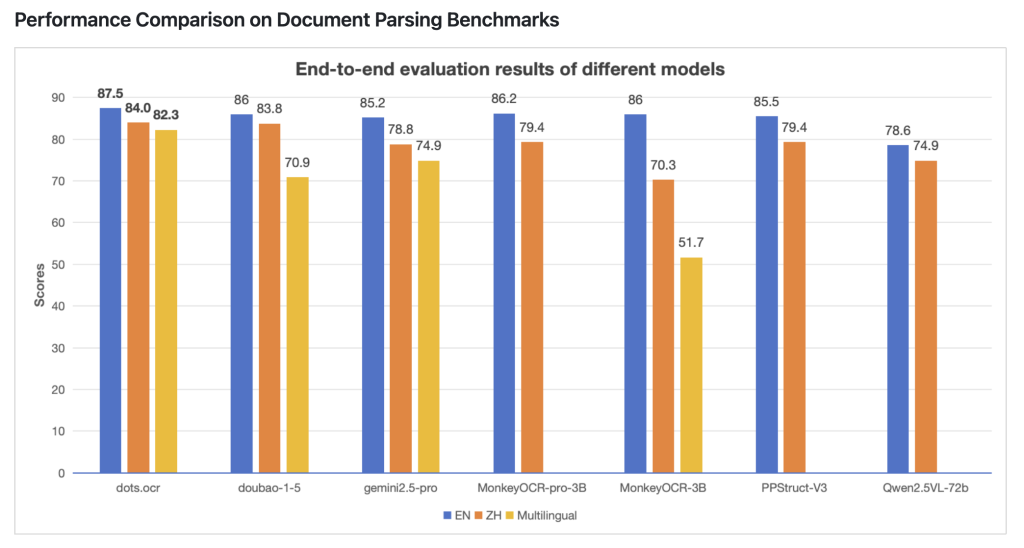
مقارنة الأداء مع النماذج الرائدة
أظهرت نتائج الاختبارات أن dots.ocr يتفوق على أنظمة الذكاء الاصطناعي الحديثة في معالجة الوثائق، حيث حقق نتائج مُذهلة:
| المعيار | dots.ocr | Gemini2.5-Pro |
|---|---|---|
| دقة جداول TEDS | 88.6% | 85.8% |
| مسافة تعديل النص (Text Edit Distance) | 0.032 | 0.055 |
يتفوق dots.ocr على Gemini2.5-Pro في دقة تحليل الجداول، ويُظهر دقة أعلى في استخراج النصوص، بالإضافة إلى تحقيق نتائج مُماثلة أو أفضل في التعرف على الصيغ الرياضية وإعادة بناء بنية الوثيقة.
النشر والتكامل
- مصدر مفتوح: تم إصدار dots.ocr تحت ترخيص MIT، مع توفير المصدر، والوثائق، والنماذج المُدرّبة مسبقًا على GitHub. يُقدم المستودع تعليمات التثبيت باستخدام pip و Conda و Docker.
- واجهة برمجة التطبيقات (API) والبرمجة النصية: يدعم النموذج تهيئة المهام المرنة من خلال قوالب الإرشادات. يمكن استخدام النموذج تفاعليًا أو ضمن خطوط أنابيب آلية لمعالجة الوثائق الضخمة.
- تنسيقات المخرجات: يتم تقديم النتائج المُستخرجة بتنسيق JSON المُبَنى للاستخدام البرمجي، مع خيارات لـ Markdown و HTML عند الاقتضاء. تتيح نصوص التصور فحص التخطيطات المُكتشفة.
الخلاصة
يُقدم dots.ocr حلًا تقنيًا عالي الدقة لمعالجة الوثائق متعددة اللغات من خلال دمج اكتشاف التخطيط والتعرف على المحتوى في نموذج واحد مفتوح المصدر. وهو مناسب بشكل خاص للسيناريوهات التي تتطلب تحليلًا قويًا للوثائق بغض النظر عن اللغة، واستخراج معلومات مُبَنية في بيئات ذات موارد محدودة أو بيئات الإنتاج.
مواضيع مشابهة:
 دليل برمجي خطوة بخطوة لدمج أدوات البحث والتوصية في الوقت الحقيقي من Dappier AI مع واجهة برمجة تطبيقات دردشة OpenAI
من إليزا إلى نمذجة المحادثة: تطور أنظمة وباراديغمات الذكاء الاصطناعي المحادثي
دليل برمجي خطوة بخطوة لدمج أدوات البحث والتوصية في الوقت الحقيقي من Dappier AI مع واجهة برمجة تطبيقات دردشة OpenAI
من إليزا إلى نمذجة المحادثة: تطور أنظمة وباراديغمات الذكاء الاصطناعي المحادثي
 أداة Llama Prompt Ops: تحسين استجابات نماذج Llama بسهولة
أداة Llama Prompt Ops: تحسين استجابات نماذج Llama بسهولة
 هل يمكن الكشف الآلي عن الهلوسة في نماذج اللغات الكبيرة؟ دراسة نظرية وتطبيقية
هل يمكن الكشف الآلي عن الهلوسة في نماذج اللغات الكبيرة؟ دراسة نظرية وتطبيقية


اترك تعليقاً