نموذج شاومي الصوتي MiMo-Audio: ثورة في معالجة اللغة الصوتية
أعلنت شركة شاومي مؤخراً عن إطلاق نموذجها اللغوي الصوتي الضخم MiMo-Audio، وهو نموذج يحتوي على 7 مليارات بارامتر، تم تدريبه على أكثر من 100 مليون ساعة من البيانات الصوتية. يمثل هذا النموذج نقلة نوعية في مجال معالجة اللغة الطبيعية، وذلك بفضل تصميمه المبتكر ونتائجه المذهلة.
الابتكار في تقنية معالجة الصوت
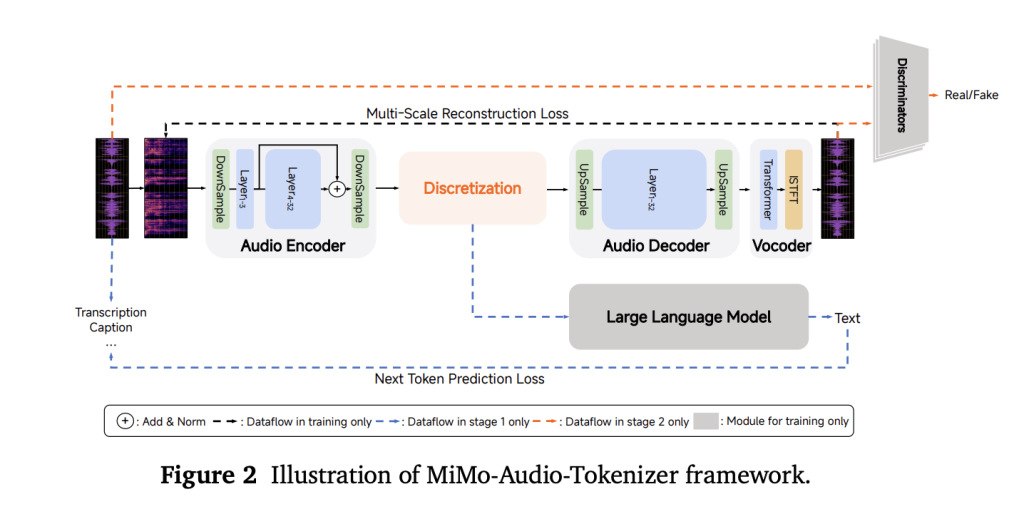
يتفوق MiMo-Audio على النماذج السابقة من خلال اعتماده على تقنية مبتكرة لترميز الصوت، تسمى “ترميز المتجهات المتبقية” (RVQ). تُمكّن هذه التقنية من تحويل الإشارات الصوتية إلى رموز رقمية عالية الدقة، تحافظ على جودة الصوت وخصائصه الأساسية، مثل نبرة الصوت ولهجة المتحدث، دون اللجوء إلى تقنيات ضاغطة قد تُفقد جزءًا من المعلومات.
يعمل مُرمّز RVQ بتردد 25 هرتز، وينتج 8 طبقات من الرموز (حوالي 200 رمز في الثانية)، مما يوفر للنموذج اللغوي إمكانية الوصول إلى خصائص صوتية “خالية من الخسائر”، يمكن معالجتها تلقائيًا جنبًا إلى جنب مع النصوص.
هيكلية النموذج وطريقة التدريب
يتكون MiMo-Audio من ثلاثة أجزاء رئيسية:
- مشفر التصحيح (Patch Encoder): يقوم بتحويل الإشارات الصوتية إلى تصحيحات قابلة للمعالجة بواسطة النموذج اللغوي.
- النموذج اللغوي الضخم (LLM): وهو نموذج لغوي ضخم من 7 مليارات بارامتر، يعالج التصحيحات الصوتية والنصوص معًا.
- فكّك التصحيح (Patch Decoder): يعيد بناء تدفقات RVQ عالية الجودة من التصحيحات المُعالجة.
لتجاوز مشكلة عدم تطابق معدل معالجة الصوت والنص، يقوم النظام بتجميع أربعة أجزاء زمنية في تصحيح واحد (خفض التردد من 25 هرتز إلى 6.25 هرتز)، ثم يعيد بناء تدفقات RVQ كاملة الدقة باستخدام فكّك التصحيح السببي.
يتم تدريب الأجزاء الثلاثة – مشفر التصحيح، النموذج اللغوي MiMo-7B، وفكّك التصحيح – باستخدام هدف واحد وهو التنبؤ بالرمز التالي. تتضمن عملية التدريب مرحلتين رئيسيتين:
- مرحلة الفهم: يتم فيها تحسين فقدان الرموز النصية على مجموعات بيانات صوتية ونصية متداخلة.
- مرحلة الفهم والتوليد: يتم فيها تشغيل خسائر الصوت لمواصلة الكلام، ومهام الترجمة من الصوت إلى النص والعكس، والبيانات على شكل تعليمات.
النتائج والأداء
أظهر MiMo-Audio أداءً متميزًا في معايير مختلفة، بما في ذلك:
- SpeechMMLU: حقق نتائج متقدمة في مهام الاستدلال على الكلام (69.1% من الصوت إلى الصوت، 71.5% من النص إلى الصوت).
- MMAU: أظهر فهمًا شاملاً للصوتيات، بما في ذلك الكلام، والموسيقى، والآلات الصوتية.
كما تميز MiMo-Audio بتقليل الفجوة بين مهام النص فقط ومهام الصوت، مما يدل على قدرته على تعميم المعرفة بين الوسائط المختلفة.
أهمية MiMo-Audio وخصائصه الفريدة
تتمثل أهمية MiMo-Audio في بساطته وفعاليته، حيث يعتمد على هدف واحد فقط وهو التنبؤ بالرمز التالي، دون الحاجة إلى رؤوس متعددة المهام أو أهداف محددة لمهام التعرف على الكلام أو توليد الكلام. تتمثل الأفكار الهندسية الرئيسية في:
- ترميز عالي الدقة: يحافظ على دقة الصوت وخصائصه.
- نمذجة التصحيح: يقلل من طول المتواليات، مما يسهل معالجة مقاطع الصوت الطويلة.
- فكّك RVQ المؤجل: يحافظ على جودة الصوت عند التوليد.
توفر MiMo-Audio
أتاحت شاومي إمكانية الوصول إلى MiMo-Audio من خلال:
- النموذج الكامل (7B بارامتر): بنسختيه الأساسية والتعليمية.
- مجموعة أدوات التقييم MiMo-Audio-Eval: لإعادة إنتاج النتائج.
- عروض توضيحية: لتجربة ميزات النموذج، مثل مواصلة الكلام، وتحويل الصوت، وإزالة الضوضاء، والترجمة الصوتية.
يُعد MiMo-Audio خطوة كبيرة إلى الأمام في مجال معالجة اللغة الصوتية، ويفتح آفاقًا جديدة لتطوير التطبيقات الصوتية الذكية.






اترك تعليقاً