نماذج SmallThinker اللغوية: ثورة في الذكاء الاصطناعي المحلي
يُهيمن على مشهد أنظمة الذكاء الاصطناعي التوليدي حاليًا نماذج اللغات الضخمة، المصممة غالبًا للعمل على سعة مراكز البيانات السحابية الهائلة. وبالرغم من قوة هذه النماذج، إلا أنها تُعيق أو تُحيل دون تمكين المستخدمين العاديين من نشر أنظمة ذكاء اصطناعي متقدمة بشكل خاص وفعال على أجهزة محلية مثل أجهزة الكمبيوتر المحمولة، والهواتف الذكية، أو الأنظمة المضمنة. وبدلاً من ضغط نماذج الحجم السحابي لتلائم الأجهزة الطرفية – وهو ما يؤدي غالبًا إلى تنازلات كبيرة في الأداء – طرح فريق SmallThinker سؤالًا أكثر جوهرية: ماذا لو صُممت نماذج اللغات منذ البداية لتناسب القيود المحلية؟
تصميم SmallThinker: ابتكارات معمارية
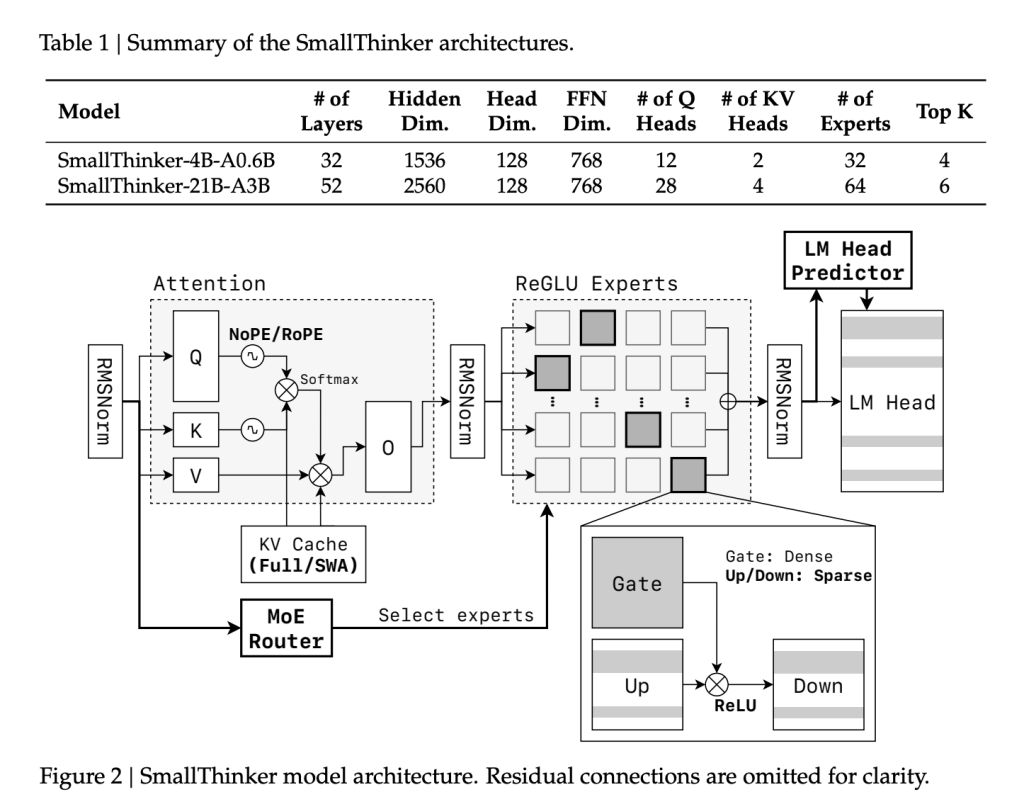
كان هذا هو الأساس لنماذج SmallThinker، وهي عائلة من نماذج “مزيج الخبراء” (MoE) طورتها مجموعة من الباحثين في جامعة جياو تونغ في شنغهاي و Zenergize AI، والتي تستهدف الأداء العالي مع محدودية الذاكرة وقوة الحوسبة في الاستدلال على الجهاز. مع نسختين رئيسيتين هما SmallThinker-4B-A0.6B و SmallThinker-21B-A3B، وضعت SmallThinker معيارًا جديدًا للذكاء الاصطناعي الفعال والمتاح. تحولت القيود المحلية إلى مبادئ تصميم.
خليط دقيق من الخبراء (MoE):
على عكس نماذج LLMs أحادية البنية النموذجية، يتميز SmallThinker بهيكل رئيسي مُصمم بخليط دقيق من الخبراء (MoE). يتم تدريب العديد من شبكات الخبراء المتخصصة، ولكن يتم تنشيط مجموعة فرعية صغيرة فقط لكل وحدة مدخل:
- SmallThinker-4B-A0.6B: 4 مليارات معلمة إجمالاً، مع 600 مليون معلمة فقط قيد التشغيل لكل وحدة.
- SmallThinker-21B-A3B: 21 مليار معلمة، منها 3 مليارات فقط نشطة في وقت واحد.
يُمكن هذا من الحصول على سعة عالية دون عقوبات ذاكرة وحوسبة نماذج الكثافة.
ندرة التغذية الأمامية القائمة على ReGLU:
يتم تعزيز ندرة التنشيط بشكل أكبر باستخدام ReGLU. حتى داخل الخبراء المنشطين، يكون أكثر من 60% من الخلايا العصبية خاملة لكل خطوة استدلال، مما يحقق وفورات هائلة في الحوسبة والذاكرة.
آلية انتباه NoPE-RoPE الهجينة:
للحصول على معالجة سياقية فعالة، يستخدم SmallThinker نمط انتباه جديد: بالتناوب بين طبقات NoPositionalEmbedding (NoPE) العالمية وطبقات نافذة الانزلاق RoPE المحلية. يدعم هذا النهج أطوال سياقات كبيرة (حتى 32 ألف وحدة لـ 4B و 16 ألف وحدة لـ 21B) ولكنه يقلل من حجم ذاكرة التخزين المؤقت للمفتاح/القيمة مقارنة بآلية الانتباه العالمية التقليدية.
جهاز توجيه ما قبل الانتباه وإيقاف التشغيل الذكي:
يُعد فصل سرعة الاستدلال عن سرعة التخزين البطيئة أمرًا بالغ الأهمية للاستخدام على الجهاز. يتنبأ “جهاز توجيه ما قبل الانتباه” في SmallThinker بالخبراء الذين سيلزمهم قبل كل خطوة انتباه، بحيث يتم جلب معلماتهم مسبقًا من SSD/flash بالتوازي مع الحساب. يعتمد النظام على تخزين الخبراء “الساخنين” في ذاكرة الوصول العشوائي (RAM) (باستخدام سياسة LRU)، بينما تبقى المتخصصين الأقل استخدامًا في وحدة التخزين السريعة. يُخفي هذا التصميم بشكل أساسي تأخر مدخلات/مخرجات ويُعظم الإنتاجية حتى مع الحد الأدنى من ذاكرة النظام.
نظام التدريب والبيانات
تم تدريب نماذج SmallThinker من جديد، وليس كمشتقات، على منهج دراسي يتقدم من المعرفة العامة إلى بيانات STEM، والرياضيات، والترميز المتخصصة للغاية:
- معالجة النسخة 4B لـ 2.5 تريليون وحدة.
- معالجة النسخة 21B لـ 7.2 تريليون وحدة.
تأتي البيانات من مزيج من مجموعات مفتوحة المصدر مُنسقة، ومجموعات بيانات رياضية وترميز اصطناعية مُعززة، ومجموعات بيانات تعليمية مُشرف عليها. تضمنت المنهجيات تصفية الجودة، وتوليد البيانات على طراز MGA، واستراتيجيات مطالبات مُدارة بالشخصيات – خاصة لرفع الأداء في المجالات الرسمية والمجالات التي تعتمد على المنطق.
نتائج الاختبار
على المهام الأكاديمية:
يتفوق نموذج SmallThinker-21B-A3B، على الرغم من تنشيطه لعدد أقل بكثير من المعلمات مقارنةً بالخصوم المنافسين، أو يتساوى معهم في مجالات تتراوح من الرياضيات (MATH-500، GPQA-Diamond) إلى توليد الرموز (HumanEval) وتقييمات المعرفة الواسعة (MMLU):
| النموذج | MMLU | GPQA | Math-500 | IFEval | LiveBench | HumanEval | المتوسط |
|---|---|---|---|---|---|---|---|
| SmallThinker-21B-A3B | 84.45 | 5.18 | 2.48 | 5.86 | 0.38 | 9.67 | 6.3 |
| Qwen3-30B-A3B | 85.14 | 4.48 | 4.48 | 4.35 | 8.89 | 0.27 | 4.5 |
| Phi-4-14B | 84.65 | 5.58 | 0.26 | 3.24 | 2.48 | 7.26 | 8.8 |
| Gemma3-12B-it | 78.53 | 4.98 | 2.47 | 4.74 | 4.58 | 2.96 | 6.3 |
كما يتفوق نموذج 4B-A0.6B أو يتساوى مع نماذج أخرى ذات عدد معلمات مُنشطة مماثل، خاصةً في التفكير والترميز.
على الأجهزة الحقيقية:
يُظهر SmallThinker تميزه الحقيقي على الأجهزة ذات الذاكرة المحدودة:
- يعمل النموذج 4B بشكل مريح مع 1 جيجابايت من ذاكرة الوصول العشوائي فقط، والنموذج 21B مع 8 جيجابايت فقط، دون انخفاضات كارثية في السرعة.
- تعني ميزة الإحضار المسبق والتخزين المؤقت أنه حتى مع هذه الحدود، يظل الاستدلال أسرع وأكثر سلاسة بكثير من النماذج الأساسية التي تم تبديلها ببساطة إلى القرص.
- على سبيل المثال، يحافظ متغير 21B-A3B على أكثر من 20 وحدة/ثانية على وحدة المعالجة المركزية القياسية، بينما يتعطل Qwen3-30B-A3B تقريبًا تحت قيود ذاكرة مماثلة.
أثر الندرة والاختصاص
اختصاص الخبراء:
تكشف سجلات التنشيط أن 70-80% من الخبراء يُستخدمون بشكل نادر، بينما تُنشط مجموعة قليلة من الخبراء “النقطة الساخنة” لمجالات أو لغات محددة – وهي خاصية تُمكن من التخزين المؤقت المتنبأ به وفعال للغاية.
ندرة على مستوى الخلايا العصبية:
حتى داخل الخبراء النشطين، تتجاوز معدلات الخمول العصبية المتوسطة 60%. الطبقات المبكرة تكون نادرة تقريبًا بالكامل، بينما تحتفظ الطبقات الأعمق بهذه الكفاءة، مما يُوضح سبب تمكن SmallThinker من القيام بالكثير باستخدام القليل من الحوسبة.
القيود والعمل المستقبلي
على الرغم من الإنجازات الكبيرة، إلا أن SmallThinker ليس خاليًا من العيوب:
- حجم مجموعة التدريب: يُعد نص التدريب الخاص به، على الرغم من ضخامته، أصغر من النصوص الموجودة خلف بعض نماذج السحابة الرائدة – مما قد يُحد من التعميم في المجالات النادرة أو الغامضة.
- محاذاة النموذج: تم تطبيق الضبط الدقيق المُشرف فقط؛ على عكس نماذج LLMs السحابية الرائدة، لم يتم استخدام التعلم المعزز من التعليقات البشرية، مما قد يُترك بعض الثغرات في السلامة والمساعدة.
- التغطية اللغوية: تُهيمن اللغة الإنجليزية والصينية، مع STEM، على التدريب – قد تُظهر اللغات الأخرى جودة مُنخفضة.
يتوقع المؤلفون توسيع مجموعات البيانات وإدخال خطوط أنابيب RLHF في الإصدارات المستقبلية.
الخلاصة
يمثل SmallThinker انحرافًا جذريًا عن تقليد “تصغير نماذج السحابة للأجهزة الطرفية”. من خلال البدء من قيود محلية أولًا، يُقدم SmallThinker قدرة عالية، وسرعة عالية، واستخدام منخفض للذاكرة من خلال الابتكار المعماري والنظمي. يفتح هذا الباب أمام ذكاء اصطناعي خاص، سريع الاستجابة، وقادر على العمل على أي جهاز تقريبًا – مما يُعزز من إمكانية الوصول إلى تقنية اللغة المتقدمة لعدد أكبر بكثير من المستخدمين وحالات الاستخدام. تتوفر النماذج – SmallThinker-4B-A0.6B-Instruct و SmallThinker-21B-A3B-Instruct – مجانًا للباحثين والمطورين، وتُشكل دليلًا مُقنعًا لما هو ممكن عندما يُدار تصميم النموذج من خلال حقائق النشر، وليس فقط طموح مركز البيانات.
يمكنكم الاطلاع على الورقة البحثية، و SmallThinker-4B-A0.6B-Instruct و SmallThinker-21B-A3B-Instruct هنا. لا تترددوا في زيارة صفحة الدروس التعليمية الخاصة بنا حول وكيل الذكاء الاصطناعي والذكاء الاصطناعي الوكيلية لمختلف التطبيقات. كما لا تترددوا في متابعتنا على تويتر، ولا تنسوا الانضمام إلى مجتمع ML SubReddit الذي يضم أكثر من 100 ألف عضو، والاشتراك في قائمتنا البريدية.
مواضيع مشابهة:
 بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه
بناء وكلاء ذكاء اصطناعي متعاونين لتحليل السوق وإدارة المخاطر باستخدام إطار عمل Agno
دليل OpenAI الاستراتيجي لاعتماد الذكاء الاصطناعي في المؤسسات: دروس عملية من الميدان
LorSA: آلية الانتباه المتفرّعة لاستخراج وحدات الانتباه الذرية الخفية في نماذج الترانسفورمر
صفر مطلق: الذكاء الاصطناعي الذي يُعلّم نفسه بنفسه



اترك تعليقاً