تعزيز قدرات الاستدلال في نماذج اللغات الكبيرة: إصدار NVIDIA لـ ProRLv2
يُعلن معهد NVIDIA للذكاء الاصطناعي عن إصدار ProRLv2، وهو أحدث إصدار من تقنية التعلم المعزز المطوّل (ProRL) المصممة خصيصاً لدفع حدود قدرات الاستدلال في نماذج اللغات الكبيرة (LLMs). يُعدّ هذا الإصدار نقلة نوعية في مجال معالجة اللغات الطبيعية، حيث يفتح آفاقاً جديدة في مجال الإبداع والتفكير العميق.
ما هو ProRLv2؟
ProRLv2 هو تطوير متقدم لتقنية التعلم المعزز المطوّل، حيث تم زيادة خطوات التعلم المعزز من 2000 إلى 3000 خطوة. يهدف هذا التطوير إلى اختبار مدى تأثير زيادة خطوات التعلم المعزز على إمكانيات نماذج اللغات الكبيرة في حلّ المشكلات المعقدة، وزيادة قدرتها على الإبداع والتفكير على مستوى عالٍ، حتى مع نماذج أصغر حجماً مثل نموذج Nemotron-Research-Reasoning-Qwen-1.5B-v2 الذي يحتوي على 1.5 مليار معامل.
الابتكارات الرئيسية في ProRLv2
يتضمن ProRLv2 العديد من الابتكارات للتغلب على القيود الشائعة في تدريب نماذج اللغات الكبيرة باستخدام تقنيات التعلم المعزز:
- الخوارزمية المُحسّنة REINFORCE++- Baseline: خوارزمية متينة للتعلم المعزز تمكن من التحسين على المدى الطويل عبر آلاف الخطوات، مع معالجة عدم الاستقرار النموذجي في التعلم المعزز لنماذج اللغات الكبيرة.
- تنظيم الانحراف الكلي (KL Divergence Regularization) وإعادة ضبط سياسة المرجع: يتم تحديث نموذج المرجع بشكل دوري بأفضل نقطة تحقق حالية، مما يسمح بتحقيق تقدم مستقر واستمرار الاستكشاف عن طريق منع هدف التعلم المعزز من الهيمنة في وقت مبكر.
- قصّ مفصول وديناميكي للعينات (Decoupled Clipping & Dynamic Sampling – DAPO): يشجع على اكتشاف حلول متنوعة عن طريق تعزيز الرموز غير المحتملة وتركيز إشارات التعلم على المطالبات ذات الصعوبة المتوسطة.
- عقوبة الطول المجدولة: تُطبق بشكل دوري، مما يساعد على الحفاظ على التنوع ومنع انهيار الانتروبيا مع زيادة طول التدريب.
- زيادة خطوات التدريب: ينقل ProRLv2 أفق تدريب التعلم المعزز من 2000 إلى 3000 خطوة، مما يختبر مباشرةً مدى إمكانية توسيع قدرات الاستدلال من خلال زيادة خطوات التعلم المعزز.
كيف يُوسّع ProRLv2 قدرات الاستدلال في نماذج اللغات الكبيرة؟
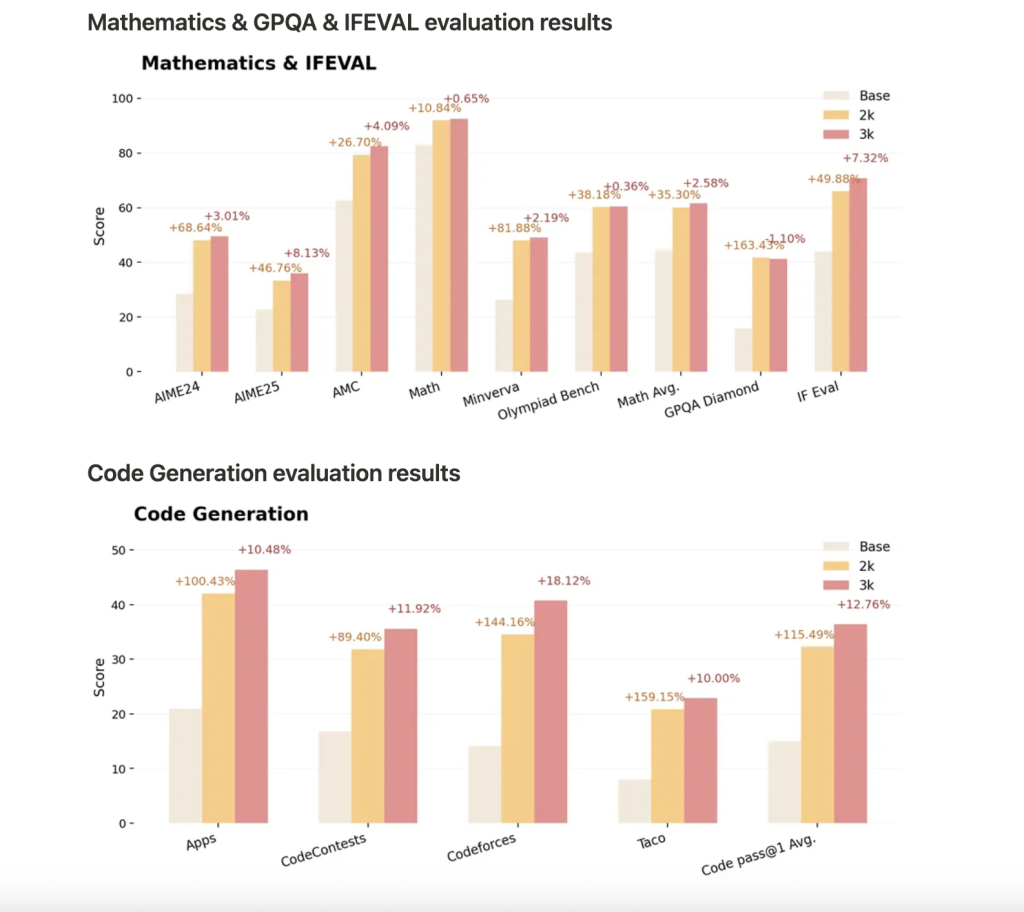
أظهر نموذج Nemotron-Research-Reasoning-Qwen-1.5B-v2، المدرب باستخدام ProRLv2 لـ 3000 خطوة من التعلم المعزز، معياراً جديداً للنماذج المفتوحة ذات 1.5 مليار معامل في مهام الاستدلال، بما في ذلك الرياضيات، والبرمجة، والعلوم، وألغاز المنطق:
- الأداء المتفوق: يتجاوز أداء النموذج الإصدارات السابقة والمنافسين مثل DeepSeek-R1-1.5B.
- المكاسب المستدامة مع المزيد من خطوات التعلم المعزز: يؤدي التدريب الأطول إلى تحسينات مستمرة، خاصة في المهام التي تُظهر فيها النماذج الأساسية أداءً ضعيفاً، مما يدل على توسيع حقيقي لحدود الاستدلال.
- التعميم: لا يعزز ProRLv2 دقة pass@1 فحسب، بل يُمكّن أيضاً من استراتيجيات استدلال وحلول جديدة في مهام لم تُشاهد خلال التدريب.
- المعايير: تتضمن المكاسب تحسينات متوسطة في دقة pass@1 بنسبة 14.7% في الرياضيات، و13.9% في البرمجة، و54.8% في ألغاز المنطق، و25.1% في الاستدلال في مجالات العلوم والتكنولوجيا والهندسة والرياضيات (STEM)، و18.1% في مهام اتباع التعليمات، مع تحسينات إضافية في الإصدار الثاني على المعايير غير المرئية والأصعب.
أهمية ProRLv2
النتيجة الرئيسية لـ ProRLv2 هي أن التدريب المستمر للتعلم المعزز، مع استكشاف دقيق وتنظيم، يُوسّع بشكل موثوق ما يمكن أن تتعلمه نماذج اللغات الكبيرة وتعمّمه. بدلاً من الوصول إلى مستوى ثابت مبكر أو فرط التجهيز، يسمح التعلم المعزز المطوّل للنماذج الأصغر بالتنافس مع النماذج الأكبر بكثير في مجال الاستدلال، مما يُظهر أن توسيع نطاق التعلم المعزز نفسه بنفس أهمية حجم النموذج أو حجم البيانات.
استخدام Nemotron-Research-Reasoning-Qwen-1.5B-v2
تتوفر أحدث نقطة تحقق للاختبار على منصة Hugging Face.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("nvidia/Nemotron-Research-Reasoning-Qwen-1.5B")
model = AutoModelForCausalLM.from_pretrained("nvidia/Nemotron-Research-Reasoning-Qwen-1.5B")الخاتمة
يعيد ProRLv2 تعريف حدود الاستدلال في نماذج اللغات عن طريق إظهار أن قوانين توسيع نطاق التعلم المعزز بنفس أهمية الحجم أو البيانات. من خلال التنظيم المتقدم والجدولة الذكية للتدريب، يُمكّن من استدلال عميق وإبداعي وقابل للتعميم حتى في الهياكل المدمجة. يكمن المستقبل في مدى قدرة التعلم المعزز على التقدم، وليس فقط في مدى ضخامة النماذج.
مواضيع مشابهة:
 DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
DeepSeek-Prover-V2: نموذج لغوي كبير مفتوح المصدر لإثبات النظريات الرياضية
الاستنتاج الموازي في نماذج اللغات الكبيرة: ثورة في كفاءة المعالجة
 بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena
بروتوكول سياق النموذج (MCP): المعيار الجديد لتكامل أدوات الذكاء الاصطناعي
جوجل تُطلق جيميني 2.5 برو (إصدار I/O): تفوق على GPT-4 في البرمجة ودعم فهم الفيديو الأصلي وريادة منصة WebDev Arena


اترك تعليقاً