باراثينكر: التغلب على قيود الحوسبة في نماذج اللغات الكبيرة عبر التفكير الموازي
يواجه تطوير نماذج اللغات الكبيرة (LLMs) تحديات كبيرة في مجال الحوسبة، خاصةً أثناء مرحلة الاختبار. تعتمد الأساليب التقليدية على توسيع مسارات الاستدلال التسلسلية، إلا أن هذا النهج يصل إلى مستوى من الأداء لا يتجاوزه بسهولة، حيث تظهر ظاهرة “رؤية النفق” (Tunnel Vision). في هذا المقال، سنستعرض إطار عمل باراثينكر (ParaThinker) المبتكر الذي يعالج هذه المشكلة من خلال تبني نهج التفكير الموازي.
قيود نماذج اللغات الكبيرة التسلسلية: رؤية النفق
تعتمد نماذج اللغات الكبيرة التسلسلية على توليد سلسلة من الرموز (tokens) بشكل متتالي، حيث يؤدي أي خطأ مبكر إلى انتشاره وتأثيره على باقي العملية. تُعرف هذه الظاهرة باسم “رؤية النفق”، وهي تعيق قدرة النموذج على التعافي من الأخطاء، حتى مع زيادة موارد الحوسبة. أظهرت التجارب على نموذج DeepSeek-R1-distill-Qwen-1.5B أن زيادة عدد الرموز (tokens) فوق 32 ألف رمز (حتى 128 ألف رمز) لا تؤدي إلى تحسن يُذكر في الدقة. هذا يدل على أن المشكلة تكمن في الأسلوب التسلسلي وليس في قدرة النموذج نفسه.
باراثينكر: التفكير الموازي كحلّ مبتكر
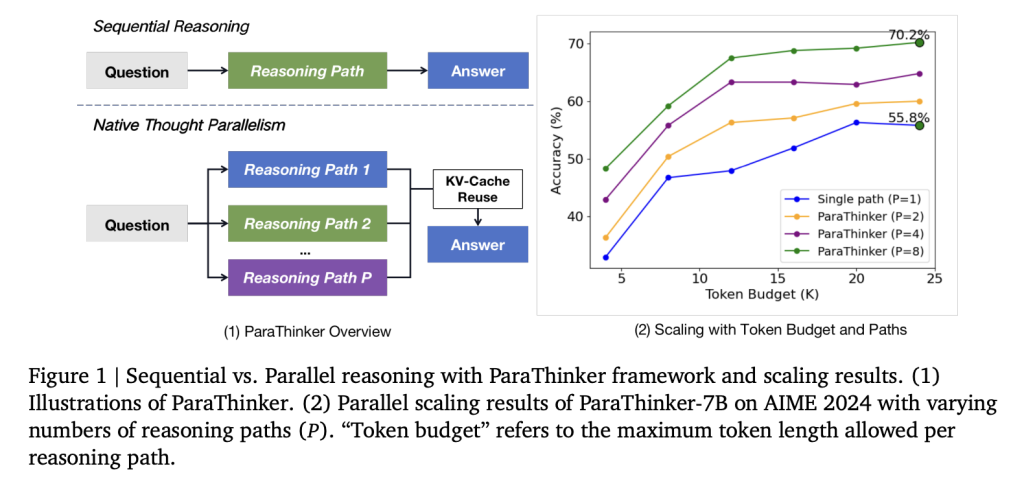
يقدم باحثون من جامعة تسينغهوا إطار عمل باراثينكر (ParaThinker)، وهو إطار عمل شامل يُدرب نموذج اللغات الكبيرة على توليد مسارات استدلال متعددة ومتنوعة بشكل موازٍ، ثم دمجها للحصول على إجابة نهائية أفضل. تتميز تقنية باراثينكر بالنقاط التالية:
- الرموز التحكمية المتخصصة: استخدام رموز تحكمية مثل
<think i>لبدء مسارات استدلال منفصلة. - التضمينات المكانية الخاصة بكل مسار: لتمييز الرموز بين المسارات المختلفة ومنع الانهيار أثناء عملية التجميع.
- أقنعة الانتباه ذات المرحلتين: لفرض الاستقلالية بين المسارات أثناء الاستدلال، وضبط عملية التكامل أثناء توليد الإجابة النهائية.
- إعادة استخدام ذاكرة التخزين المؤقت (KV-caches): إعادة استخدام ذاكرة التخزين المؤقت من مرحلة الاستدلال في مرحلة التجميع، مما يقلل من تكرار العمليات.
تدريب باراثينكر على التفكير الموازي
تم تدريب باراثينكر باستخدام تقنية الضبط الدقيق الخاضع للإشراف (SFT) مع مجموعات بيانات استدلال متعددة المسارات. تم إنشاء بيانات التدريب من خلال أخذ عينات من مسارات الحلول المتعددة من نماذج مُدرّبة مسبقًا (مثل DeepSeek-R1 و GPT-OSS-20B). تضمنت كل عينة عدة مسارات <think i> وحلاً نهائياً <summary>. تم استخدام نماذج Qwen-2.5 (1.5 مليار و 7 مليارات معلمة) مع الحد الأقصى لطول السياق 28 ألف رمز. شملت مصادر البيانات Open-R1 و DeepMath و s1k و LIMO، بالإضافة إلى حلول إضافية تم أخذ عينات منها بدرجة حرارة 0.8.
نتائج التجارب
أظهرت نتائج التجارب على مجموعات بيانات AIME 2024، AIME 2025، AMC 2023، و MATH-500 ما يلي:
- الدقة: حقق نموذج باراثينكر 1.5 مليار معلمة زيادة في الدقة بنسبة 12.3% مقارنة بالأساليب التسلسلية، و 4.3% مقارنة بأسلوب التصويت بالأغلبية. أما نموذج 7 مليارات معلمة، فقد حقق زيادة بنسبة 7.5% مقارنة بالأساليب التسلسلية، و 2% مقارنة بأسلوب التصويت بالأغلبية. مع 8 مسارات استدلال، وصل نموذج باراثينكر 1.5 مليار معلمة إلى 63.2% من النجاح @1، متجاوزاً نماذج 7 مليارات معلمة التسلسلية بنفس موارد الحوسبة.
- الكفاءة: بلغ متوسط زيادة زمن الانتظار بسبب الاستدلال الموازي 7.1%. كان توليد 16 مساراً أقل من ضعف زمن توليد مسار واحد، وذلك بسبب تحسين استخدام ذاكرة وحدة معالجة الرسومات (GPU).
- استراتيجية الإنهاء: أظهرت استراتيجية “الانتهاء الأول” (First-Finish)، حيث ينتهي الاستدلال عند انتهاء أول مسار، أداءً أفضل من استراتيجيتي “الانتهاء الأخير” و “الانتهاء في المنتصف” من حيث الدقة وزمن الانتظار.
دراسات الاستبعاد
أكدت دراسات الاستبعاد أن التحسينات في الأداء ترجع إلى الابتكارات المعمارية وليس فقط بيانات التدريب. فإزالة التضمينات الخاصة بالمسارات الاستدلالية قللت من الدقة، بينما أدى استخدام التشفير المسطح إلى تدهور كبير. كما أكدت الدراسات فوائد إعادة استخدام ذاكرة التخزين المؤقت (KV-cache).
مقارنة باراثينكر بالأساليب الأخرى
تتطلب الأساليب الموازية التقليدية، مثل التصويت بالأغلبية، والاتساق الذاتي، وشجرة الأفكار، مُحققين خارجيين أو عمليات اختيار لاحقة، مما يحد من قابلية التوسع. أما الأساليب الموازية القائمة على الانتشار (Diffusion) فتعطي نتائج ضعيفة في مهام الاستدلال بسبب الاعتماد التسلسلي. أما الأساليب المعمارية مثل PARSCALE، فتتطلب تغييرات هيكلية وتدريبًا مسبقًا. أما باراثينكر، فيحافظ على بنية Transformer الأساسية ويُدخِل الموازاة على مستوى الاستدلال، مدمجا ذاكرة التخزين المؤقت (KV-caches) المتعددة في خطوة تجميع موحدة.
الخلاصة
يُظهر باراثينكر أن قيود الحوسبة في نماذج اللغات الكبيرة أثناء الاختبار هي نتيجة للأساليب التسلسلية للاستدلال. من خلال توزيع موارد الحوسبة على العرض (المسارات الموازية) بدلاً من العمق (سلاسل أطول)، يمكن لأنماذج أصغر أن تتفوق على نماذج أكبر بكثير مع زيادة طفيفة في زمن الانتظار. يُثبت هذا أن الموازاة الأصلية للتفكير هي بعد أساسي لتطوير نماذج اللغات الكبيرة في المستقبل.
مواضيع مشابهة:
 دليل برمجي خطوة بخطوة لدمج أدوات البحث والتوصية في الوقت الحقيقي من Dappier AI مع واجهة برمجة تطبيقات دردشة OpenAI
من إليزا إلى نمذجة المحادثة: تطور أنظمة وباراديغمات الذكاء الاصطناعي المحادثي
دليل برمجي خطوة بخطوة لدمج أدوات البحث والتوصية في الوقت الحقيقي من Dappier AI مع واجهة برمجة تطبيقات دردشة OpenAI
من إليزا إلى نمذجة المحادثة: تطور أنظمة وباراديغمات الذكاء الاصطناعي المحادثي
 أداة Llama Prompt Ops: تحسين استجابات نماذج Llama بسهولة
أداة Llama Prompt Ops: تحسين استجابات نماذج Llama بسهولة
 هل يمكن الكشف الآلي عن الهلوسة في نماذج اللغات الكبيرة؟ دراسة نظرية وتطبيقية
هل يمكن الكشف الآلي عن الهلوسة في نماذج اللغات الكبيرة؟ دراسة نظرية وتطبيقية



اترك تعليقاً